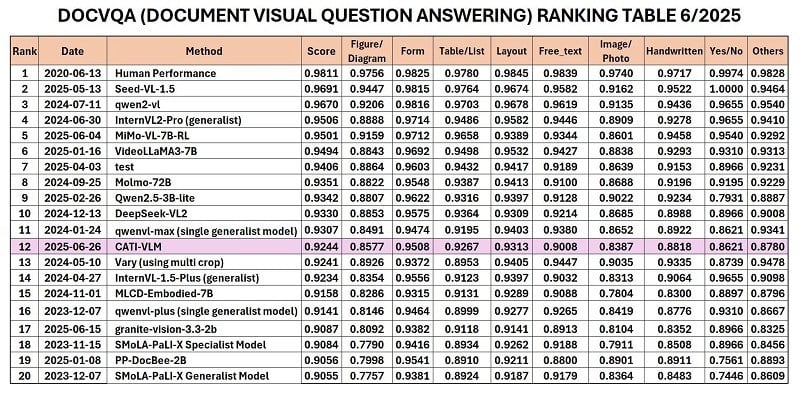
رتبهبندی RRC در بخش DocVQA، ژوئن ۲۰۲۵.
در بحبوحه تحول سریع دیجیتال و پذیرش هوش مصنوعی در ویتنام، فناوری OCR (تشخیص نوری حروف) نقش بسیار مهمی در دیجیتالی کردن اسناد، اتوماسیون فرآیندهای تجاری، صرفهجویی در هزینهها و بهبود بهرهوری مدیریت ایفا میکند. با این حال، با توجه به ویژگیهای منحصر به فرد زبان ویتنامی، از جمله لهجهها و دستخط آن، مشکل تشخیص فراتر از صرفاً «خواندن» حروف است؛ این امر به مدلی نیاز دارد که بتواند زمینه را به طور جامع درک کند.
اخیراً، موسسه فناوری کاربردی CMC (CMC ATI) مدل CATI-VLM (درک بصری اسناد) را که توسط تیم تحقیقاتی آن از یک انبار داده بزرگ ۵ ترابایتی توسعه داده شده است، معرفی کرد. این مدل با پیشی گرفتن از بسیاری از رقبای بینالمللی، در رتبهبندی منتشر شده توسط Robust Reading Competition (RRC) در ژوئن ۲۰۲۵ در بخش پاسخ به سوالات بصری اسناد (DocVQA)، به جمع ۱۲ دانشگاه برتر جهان و رتبه اول ویتنام رسید.
مسابقهی «خواندن قدرتمند» (RRC) یک مسابقهی علمی معتبر (https://rrc.cvc.uab.es/) است که توسط مرکز بینایی کامپیوتر (CVC) دانشگاه اتونوما د بارسلونا (UAB) اسپانیا، یک موسسهی تحقیقاتی مشهور جهانی در زمینهی بینایی کامپیوتر، برگزار میشود.
این مسابقه که از سال ۲۰۱۱ آغاز شده است، سالانه در چارچوب کنفرانس بینالمللی تحلیل و تشخیص متن (ICDAR) - یکی از انجمنهای پیشرو جهان در زمینه بینایی کامپیوتر - برگزار میشود. این مسابقه محققان و مهندسان بیشماری را از دانشگاهها، مؤسسات تحقیقاتی و شرکتهای بزرگ فناوری مانند دانشگاه تسینگهوا، گروه هیوندای موتور و تنسنت جذب میکند. مسائل RRC برای ارتقای پیشرفت فناوری طراحی شدهاند و ارتباط نزدیکی با مسائل عملی از ترجمه و مدیریت دادههای سازمانی گرفته تا تحلیل شهری و پردازش اسناد تاریخی دارند.
دکتر دانگ مین توان، مدیر CMC ATI، اظهار داشت: «ما بسیار خوشحالیم که قابلیتهای تحقیقاتی تیم CMC از طریق یک رقابت جهانی معتبر مانند RRC تأیید شده است. در مدت کوتاهی، تیم تحقیقاتی به رتبه بالایی دست یافته است که نشاندهنده رقابتپذیری بینالمللی با نامهای بزرگ از کشورهای توسعهیافته است. مهمتر از همه، این گواه روشنی بر توانایی ما در تسلط بر فناوری برای حل مشکلات خاص مربوط به زبان ویتنامی و زمینههای تخصصی در ویتنام است.»

دکتر Dang Minh Tuan، مدیر CMC ATI.
CATI-VLM با OCR سنتی متفاوت است، زیرا نه تنها کاراکترها را استخراج میکند، بلکه لایههای چندگانه اطلاعات را نیز درک میکند: محتوای متن، عناصر غیرمتنی (کادرهای تیک، کادرهای انتخاب، نمودارها، امضاها، فرمولها)، طرحبندی (ساختار صفحه، جداول، فرمها) و سبک (فونتها، هایلایت و غیره). این مدل میتواند به سؤالات بصری مطرحشده در تصاویر سند، مشابه ChatGPT، بدون نیاز به یادگیری قبلی هر فرم خاص، پاسخ دهد.
نکته قابل توجه این است که در رتبهبندی RRC، CATI-VLM با تنها ۳ میلیارد پارامتر، بالاترین دقت را در ۴ مجموعه داده از ۷ مجموعه داده به دست آورد و از بسیاری از مدلهای Big Tech مانند Deepseek (۲۷ میلیارد پارامتر)، GPT-4 Vision Turbo + Amazon Textract OCR (۳۴ مورد برتر) و Baidu (۲۲ مورد برتر) پیشی گرفت.
این دستاورد همچنین یک رویکرد عملی را نشان میدهد که بر تسلط بر فناوریهای اصلی و بهینهسازی مدلها برای مطابقت با شرایط زیرساختی ویتنام تمرکز دارد، نه اینکه صرفاً به دنبال پارامترهای مقیاسپذیری باشد.

نمونه فرم درخواست پذیرش دانشگاه

متن از روی دستخط موجود در تصویر بالا شناسایی شده است.
آقای نگوین ترونگ چین، رئیس هیئت مدیره و رئیس اجرایی گروه فناوری CMC، تأکید کرد: «این نتیجه بیش از یک دهه سرمایهگذاری مداوم در تحقیق و توسعه (R&D) فناوری است. دستاوردهای بالای CMC در عرصه فناوری بینالمللی، استراتژی ما برای تسلط بر فناوری ویتنام را همراه با جهتگیری ما به سمت تحول هوش مصنوعی و گسترش به بازار جهانی تأیید میکند. ما معتقدیم که هوش ویتنامی کاملاً قادر به رقابت با شرکتهای بزرگ فناوری جهانی است و جایگاه شایستهای در نقشه فناوری جهان ایجاد میکند.»
CATI-VLM در اکوسیستم محصولات C.OpenAI، از جمله موارد زیر، اعمال خواهد شد: دستیار مجازی CLS برای بررسی اسناد حقوقی، CMC SmartDoc - یک پلتفرم تبدیل اسناد دیجیتال، سیستم مدیریت دانش CMC KMS، یک سیستم گزارشدهی خودکار برای دفاتر هوشمند و برنامههای کاربردی Agentic Documents نسل بعدی.
کوانگ هوی
منبع: https://nhandan.vn/cmc-dat-top-12-the-gioi-ve-nhan-dang-van-ban-post891252.html



![[تصویر] نمای نزدیک از تقاطعی که دو بزرگراه و فرودگاه لانگ تان را به هم متصل میکند.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/05/25/1779703378210_ndo_br_z7863716673926-224453a31600126cce10622af6290afd-4549-jpg.webp)


![[تصویر] زندگی شهری هانوی در چالش محیطی «بسیار گرم»](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/05/25/1779706979265_nang-nong-t5-2026-minh-duy-7-4636-jpg.webp)

























![[تصویر] زندگی شهری هانوی در چالش محیطی «بسیار گرم»](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2026/05/25/1779706979265_nang-nong-t5-2026-minh-duy-7-4636-jpg.webp)






































































نظر (0)