

Le GPU sono il cervello dei computer che utilizzano l'intelligenza artificiale.
In parole semplici, l'unità di elaborazione grafica (GPU) funge da cervello di un computer dotato di intelligenza artificiale.
Come probabilmente già saprete, l'unità centrale di elaborazione (CPU) è il cervello di un computer. Il vantaggio di una GPU risiede nel fatto che si tratta di una CPU specializzata per l'esecuzione di calcoli complessi. Il modo più rapido per eseguire questi calcoli è quello di far lavorare insieme gruppi di GPU per risolvere un problema. Ciononostante, l'addestramento di un modello di intelligenza artificiale può richiedere settimane o addirittura mesi. Una volta creato, il modello viene inserito nel sistema informatico front-end e gli utenti possono porre domande al modello di intelligenza artificiale; questo processo è chiamato inferenza.
Un computer dotato di intelligenza artificiale contiene più GPU.
L'architettura migliore per risolvere problemi di intelligenza artificiale prevede l'utilizzo di un gruppo di GPU in un rack, collegate a uno switch posto sulla sommità del rack stesso. È possibile collegare ulteriormente più rack di GPU in un sistema di connettività di rete gerarchico. Man mano che i problemi da risolvere diventano più complessi, aumentano anche i requisiti in termini di GPU, e alcuni progetti potrebbero richiedere l'implementazione di cluster composti da migliaia di GPU.
Ogni cluster di intelligenza artificiale è una piccola rete.
Quando si crea un cluster di intelligenza artificiale, è necessario configurare una piccola rete di computer per connettere le GPU e consentire loro di lavorare insieme e condividere i dati in modo efficiente.
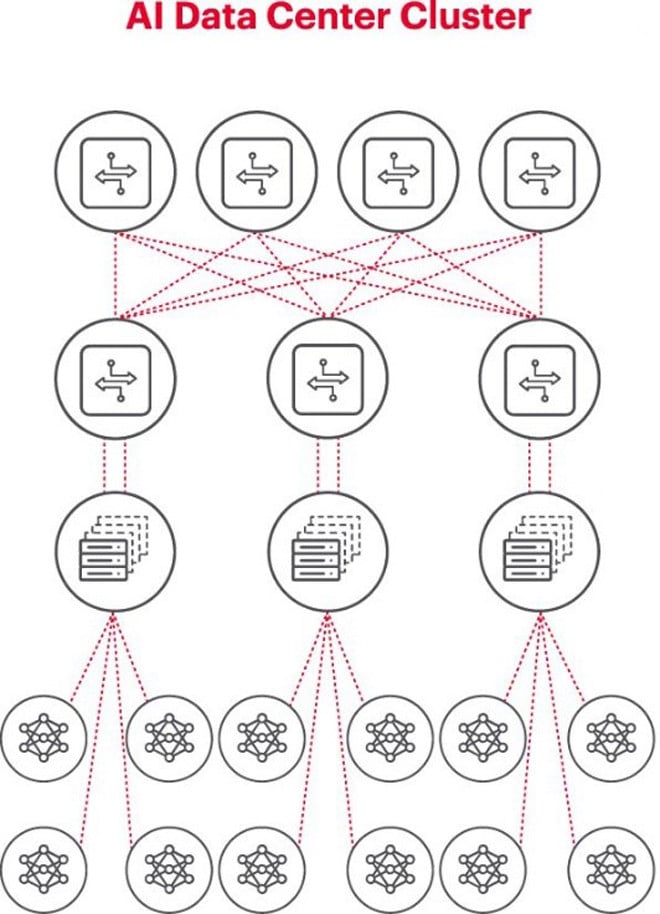
Il diagramma sopra illustra un cluster di intelligenza artificiale in cui i cerchi in basso rappresentano i flussi di lavoro in esecuzione sulle GPU. Le GPU si connettono agli switch sul rack superiore (ToR). Questi switch ToR si connettono anche agli switch della dorsale di rete mostrati sopra nel diagramma, a dimostrazione della chiara gerarchia di rete necessaria quando sono coinvolte più GPU.
Le reti rappresentano un collo di bottiglia nell'implementazione dell'intelligenza artificiale.
Lo scorso autunno, al summit globale dell'Open Computer Project (OCP), dove i delegati stavano costruendo la prossima generazione di infrastrutture per l'intelligenza artificiale, Loi Nguyen di Marvell Technology ha evidenziato un problema cruciale: "le reti sono il nuovo collo di bottiglia".
Tecnicamente, un'elevata latenza dei pacchetti o la perdita di pacchetti dovuta alla congestione della rete possono causare la ritrasmissione dei pacchetti, aumentando significativamente il tempo di completamento del lavoro (JCT). Di conseguenza, milioni o decine di milioni di dollari di GPU appartenenti alle aziende vengono sprecati a causa di sistemi di intelligenza artificiale inefficienti, danneggiando le aziende sia in termini di fatturato che di time to market.
La sperimentazione e la misurazione sono condizioni cruciali per il buon funzionamento delle reti di intelligenza artificiale.
Per far funzionare un cluster di intelligenza artificiale in modo efficiente, le GPU devono essere in grado di utilizzare la loro piena capacità per ridurre i tempi di addestramento e implementare modelli di apprendimento che massimizzino il ritorno sull'investimento. Pertanto, è necessario testare e valutare le prestazioni del cluster di intelligenza artificiale (Figura 2). Tuttavia, questo compito non è semplice, poiché l'architettura del sistema prevede numerose impostazioni e relazioni tra la GPU e la struttura di rete che devono integrarsi a vicenda per risolvere il problema.
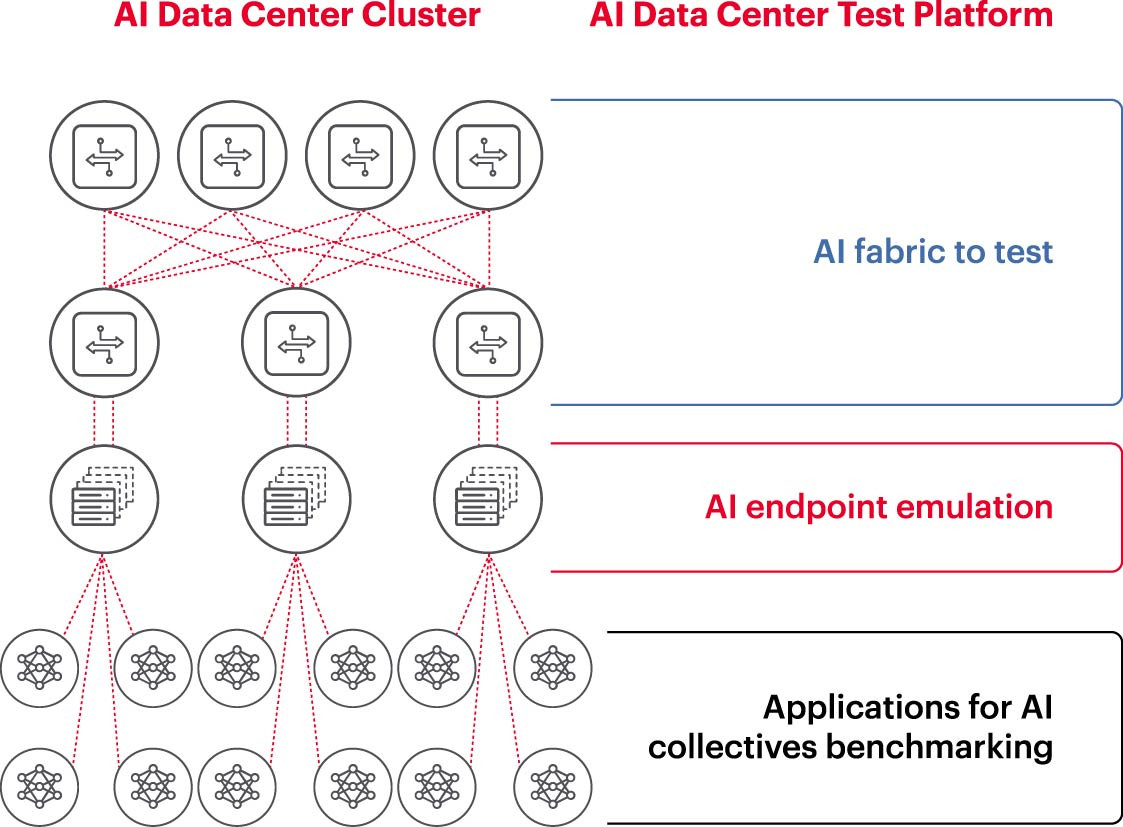
Ciò crea numerose difficoltà e sfide nella misurazione delle reti di intelligenza artificiale:
La difficoltà nel replicare l'intera rete di produzione in laboratorio è dovuta a limitazioni in termini di costi, attrezzature, carenza di ingegneri di rete specializzati in intelligenza artificiale, spazio, alimentazione elettrica e temperatura.
- I test in loco su un sistema di produzione riducono la capacità di elaborazione disponibile del sistema di produzione stesso.
- Difficoltà nel riprodurre accuratamente i problemi a causa delle differenze nella scala e nella portata degli stessi.
- La complessità del modo in cui le GPU si connettono tra loro.
Per affrontare queste sfide, le aziende possono condurre test di benchmarking su un sottoinsieme delle configurazioni proposte in un ambiente di laboratorio per valutare parametri chiave come il JCT (tempo di completamento del lavoro), la larghezza di banda raggiungibile dal team di IA e confrontarli con l'utilizzo della piattaforma di switching e l'utilizzo della cache. Questo benchmarking aiuta a trovare il giusto equilibrio tra carico di lavoro GPU/elaborazione e progettazione/installazione della rete. Una volta soddisfatti dei risultati, gli architetti informatici e gli ingegneri di rete possono applicare queste configurazioni in produzione e misurare i nuovi risultati.
Laboratori di ricerca aziendali, istituti di ricerca e università stanno lavorando per analizzare ogni aspetto della creazione e della gestione di reti di intelligenza artificiale efficaci, al fine di affrontare le sfide poste dalle reti di grandi dimensioni, soprattutto considerando che le migliori pratiche sono in continua evoluzione. Questo approccio collaborativo e ripetibile è l'unico modo per le aziende di effettuare misurazioni ripetibili e test rapidi di scenari "se-allora", elementi fondamentali per ottimizzare le reti basate sull'intelligenza artificiale.
(Fonte: Keysight Technologies)
Fonte: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html


![[Foto] Il caldo torrido sul luogo dello spettacolo pirotecnico durante la serata di apertura del Festival Internazionale dei Fuochi d'Artificio di Da Nang 2026.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/05/27/1779889741485_ndo_br_z7872039145157-fecaba5112f39e8352544099d7ef4738-5140-jpg.webp)
![[Foto] Il coraggio delle nuove reclute della Brigata 144 sul campo di addestramento.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/05/27/1779881651341_anh-man-hinh-2026-05-27-luc-18-32-52.png)






































































![[Foto] Il coraggio delle nuove reclute della Brigata 144 sul campo di addestramento.](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2026/05/27/1779881651341_anh-man-hinh-2026-05-27-luc-18-32-52.png)

































Commento (0)