
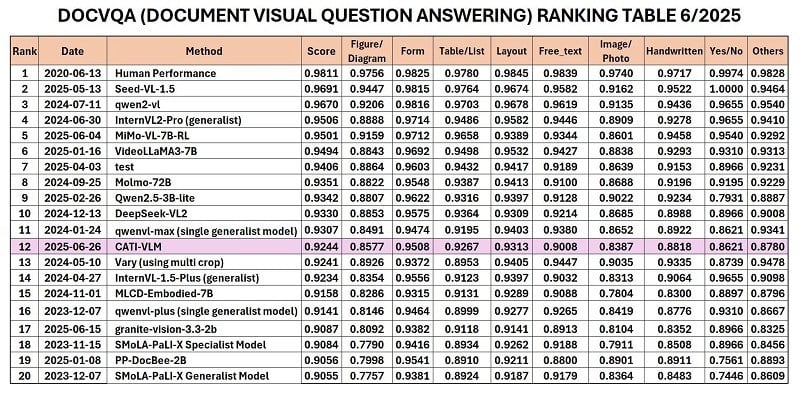
ການຈັດອັນດັບ RRC ໃນໝວດ DocVQA 6/2025.
ໃນສະພາບການຫັນເປັນດິຈິຕອລ ແລະ ການຜັນຂະຫຍາຍການນຳໃຊ້ປັນຍາປະດິດຢູ່ ຫວຽດນາມ ພວມດຳເນີນຢ່າງແຮງ, ເຕັກໂນໂລຢີ OCR (Optical Character Recognition) ໄດ້ມີບົດບາດສຳຄັນກວ່າອີກໃນການຫັນເອກະສານເປັນດິຈິຕອລ, ດຳເນີນທຸລະກິດຢ່າງອັດຕະໂນມັດ, ປະຢັດຕົ້ນທຶນ ແລະ ຍົກສູງປະສິດທິຜົນການຄຸ້ມຄອງ. ເຖິງຢ່າງໃດກໍຕາມ, ດ້ວຍລັກສະນະພາສາຫວຽດນາມ ດ້ວຍສຳນຽງ ແລະ ການຂຽນດ້ວຍມື, ບັນຫາການຮັບຮູ້ບໍ່ໄດ້ຢຸດຢູ່ທີ່ 'ການອ່ານຄຳ', ແຕ່ຮຽກຮ້ອງໃຫ້ຕົວແບບມີຄວາມສາມາດເຂົ້າໃຈສະພາບການຢ່າງຄົບຖ້ວນ.
ບໍ່ດົນມານີ້, CMC Technology Institute (CMC ATI) ໄດ້ປະກາດຕົວແບບ CATI-VLM (Visual Document Understanding) - ພັດທະນາໂດຍທີມວິໄຈຈາກສາງຂໍ້ມູນຂະໜາດໃຫຍ່ 5TB, ລື່ນກາຍຄູ່ແຂ່ງສາກົນຫຼາຍຄົນເພື່ອບັນລຸອັນດັບທີ 12 ໃນໂລກ ແລະ ອັນດັບ 1 ຂອງຫວຽດນາມ ໃນການຈັດອັນດັບພຽງແຕ່ປະກາດໂດຍການແຂ່ງຂັນອ່ານ Robust Reading Competition (RRC) ໃນເດືອນມິຖຸນາ 2020 ຜ່ານມາ (Quoc 2025). ປະເພດ.
Robust Reading Competition (RRC) ເປັນສະຫນາມເດັກຫຼິ້ນ ວິທະຍາສາດ ທີ່ມີຊື່ສຽງ, (https://rrc.cvc.uab.es/) ຈັດໂດຍ Computer Vision Center (CVC) ຂອງ Universitat Autònoma de Barcelona (UAB) ສະເປນ, ສະຖານທີ່ຄົ້ນຄ້ວາທີ່ມີຊື່ສຽງໃນໂລກໃນພາກສະຫນາມຂອງວິໄສທັດຄອມພິວເຕີ.
ການແຂ່ງຂັນໄດ້ຖືກລິເລີ່ມໃນປີ 2011 ແລະຖືກຈັດຂຶ້ນໃນທຸກໆປີໃນຂອບເຂດຂອງກອງປະຊຸມສາກົນກ່ຽວກັບການວິເຄາະຂໍ້ຄວາມແລະການຮັບຮູ້ (ICDAR) - ຫນຶ່ງໃນເວທີປຶກສາຫາລືດ້ານຄອມພິວເຕີຊັ້ນນໍາ ຂອງໂລກ . ການແຂ່ງຂັນໄດ້ດຶງດູດນັກຄົ້ນຄ້ວາແລະວິສະວະກອນຈໍານວນຫລາຍຈາກມະຫາວິທະຍາໄລ, ສະຖາບັນຄົ້ນຄ້ວາແລະບໍລິສັດເຕັກໂນໂລຢີຂະຫນາດໃຫຍ່ເຊັ່ນ: ມະຫາວິທະຍາໄລ Tsinghua, Hyundai Motor Group, Tencent ... ບັນຫາຂອງ RRC ຖືກອອກແບບມາເພື່ອສົ່ງເສີມຄວາມກ້າວຫນ້າທາງດ້ານເຕັກໂນໂລຢີ, ເຊື່ອມໂຍງຢ່າງໃກ້ຊິດກັບບັນຫາພາກປະຕິບັດຈາກການແປພາສາ, ການຄຸ້ມຄອງຂໍ້ມູນວິສາຫະກິດກັບການວິເຄາະຕົວເມືອງແລະການປຸງແຕ່ງເອກະສານປະຫວັດສາດ.
ທ່ານ ດັ້ງມິງຕ໋ວນ, ຜູ້ອຳນວຍການໃຫຍ່ CMC ATI ແບ່ງປັນວ່າ: “ພວກເຮົາດີໃຈຫຼາຍທີ່ຄວາມສາມາດຄົ້ນຄວ້າຂອງທີມ CMC ໄດ້ຮັບການຢັ້ງຢືນຜ່ານສະໜາມຫຼິ້ນລະດັບໂລກທີ່ມີຊື່ສຽງຄື RRC. ໃນເວລາສັ້ນໆ, ຄະນະຄົ້ນຄວ້າໄດ້ບັນລຸລະດັບສູງ, ສະແດງໃຫ້ເຫັນຄວາມສາມາດແຂ່ງຂັນສາກົນກັບບັນດາປະເທດທີ່ພັດທະນາແລ້ວ. ຫວຽດນາມ."

ດຣ ດັ້ງມິງຕວນ, ຜູ້ອໍານວຍການ CMC ATI.
CATI-VLM ແຕກຕ່າງຈາກ OCR ແບບດັ້ງເດີມທີ່ມັນບໍ່ພຽງແຕ່ສະກັດຕົວອັກສອນ, ແຕ່ຍັງເຂົ້າໃຈຫຼາຍຊັ້ນຂອງຂໍ້ມູນ: ເນື້ອໃນຂໍ້ຄວາມ, ອົງປະກອບທີ່ບໍ່ແມ່ນຂໍ້ຄວາມ (ກ່ອງຫມາຍຕິກ, ກ່ອງກາເຄື່ອງຫມາຍ, ຕາຕະລາງ, ລາຍເຊັນ, ສູດ), ຮູບແບບ (ໂຄງສ້າງຫນ້າ, ຕາຕະລາງ, ແບບຟອມ) ແລະຮູບແບບ (ຕົວອັກສອນ, ຈຸດເດັ່ນ, ແລະອື່ນໆ). ຮູບແບບດັ່ງກ່າວສາມາດຕອບຄໍາຖາມທີ່ເຫັນໃນຮູບພາບເອກະສານ, ຄ້າຍຄືກັບ ChatGPT, ໂດຍບໍ່ຕ້ອງຮຽນຮູ້ແບບຟອມສະເພາະກ່ອນ.
ໂດຍສະເພາະ, ໃນການຈັດອັນດັບ RRC, CATI-VLM ທີ່ມີພຽງແຕ່ 3 ຕື້ພາລາມິເຕີໄດ້ບັນລຸຄວາມຖືກຕ້ອງສູງສຸດໃນຊຸດຂໍ້ມູນ 4/7, ລື່ນກາຍຕົວແບບ Big Tech ຈໍານວນຫຼາຍເຊັ່ນ Deepseek (27 ຕື້ພາລາມິເຕີ), GPT-4 Vision Turbo + Amazon Textract OCR (ເທິງ 34) ຫຼື Baidu (ເທິງ 22).
ໝາກຜົນດັ່ງກ່າວຍັງສະແດງໃຫ້ເຫັນວິທີປະຕິບັດ, ສຸມໃສ່ເປັນເຈົ້າການເຕັກໂນໂລຊີຫຼັກແຫຼ່ງ, ປັບປຸງຕົວແບບໃຫ້ເໝາະສົມກັບເງື່ອນໄຂພື້ນຖານໂຄງລ່າງຂອງຫວຽດນາມ ແທນທີ່ຈະນັບແຕ່ຂະບວນການຂະບວນການ.

ຕົວຢ່າງແບບຟອມສະຫມັກເຂົ້າວິທະຍາໄລ

ຂໍ້ຄວາມໄດ້ຖືກຮັບຮູ້ຈາກການຂຽນດ້ວຍມືໃນຮູບຂ້າງເທິງ.
ທ່ານ Nguyen Trung Chinh, ປະທານສະພາບໍລິຫານ, ປະທານບໍລິຫານກຸ່ມເຕັກໂນໂລຊີ CMC ເນັ້ນໜັກວ່າ: “ນີ້ແມ່ນໝາກຜົນແຫ່ງການລົງທຶນຢ່າງບໍ່ຢຸດຢັ້ງໃນການຄົ້ນຄ້ວາ ແລະ ພັດທະນາເຕັກໂນໂລຊີ (R&D), CMC ບັນລຸໄດ້ບັນດາຜົນງານທີ່ສູງໃນສະໜາມກິລາເຕັກໂນໂລຊີສາກົນຢືນຢັນຍຸດທະສາດຊຳນານເຕັກໂນໂລຊີຂອງຫວຽດນາມ, ຄຽງຄູ່ກັບທິດຫັນການຫັນເປັນ AI ປັນຍາຊົນ ແລະ ເຂົ້າສູ່ຕະຫຼາດເຕັກໂນໂລຊີສາກົນຂອງຫວຽດນາມ. ສ້າງຕໍາແຫນ່ງທີ່ສົມຄວນຢູ່ໃນແຜນທີ່ເຕັກໂນໂລຢີໂລກ."
CATI-VLM ຈະຖືກນໍາໄປໃຊ້ໃນລະບົບນິເວດຂອງ C.OpenAI, ລວມທັງ: ຜູ້ຊ່ວຍ virtual CLS ສໍາລັບການທົບທວນຄືນເອກະສານທາງດ້ານກົດຫມາຍ, CMC SmartDoc - ແພລະຕະຟອມການແປງເອກະສານດິຈິຕອນ, ລະບົບການຄຸ້ມຄອງຄວາມຮູ້ CMC KMS, ລະບົບການລາຍງານອັດຕະໂນມັດສໍາລັບຫ້ອງການ smart ແລະຄໍາຮ້ອງສະຫມັກ Agentic Documents ຮຸ່ນໃຫມ່.
ກວາງຮຸຍ
ທີ່ມາ: https://nhandan.vn/cmc-dat-top-12-the-gioi-ve-nhan-dang-van-ban-post891252.html





























































































![ການຫັນປ່ຽນ OCOP ດົງນາຍ: [ມາດຕາ 3] ເຊື່ອມໂຍງການທ່ອງທ່ຽວກັບການບໍລິໂພກຜະລິດຕະພັນ OCOP](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/11/10/1762739199309_1324-2740-7_n-162543_981.jpeg)












(0)