
وتأتي هذه الخطوة في الوقت الذي تُتهم فيه شركات الذكاء الاصطناعي بسرقة المحتوى من الناشرين لتدريب الذكاء الاصطناعي أو تلخيص المعلومات، بما في ذلك المقالات المحمية بحقوق الطبع والنشر، للرد على المستخدمين دون دفع أو حتى طلب الإذن.

الصورة: رويترز
قالت شركة Reddit إنها ستقوم بتحديث بروتوكول استبعاد الروبوتات الخاص بها، أو "robots.txt"، وهو معيار مقبول على نطاق واسع لتحديد الأجزاء التي يُسمح بالزحف إليها من موقع الويب.
وقالت الشركة أيضًا إنها ستحافظ على الحد من المعدلات، وهي تقنية تستخدم للتحكم في عدد الطلبات من كيان معين، وستمنع الروبوتات والزواحف غير المعروفة من جمع البيانات على موقعها.
Robots.txt هي أداة مهمة يستخدمها الناشرون، بما في ذلك المؤسسات الإخبارية، لمنع شركات التكنولوجيا من استخراج المحتوى الخاص بهم بشكل غير قانوني لتدريب الذكاء الاصطناعي أو إنشاء ملخصات للإجابة على استعلامات بحث معينة.
وفي الأسبوع الماضي، كشفت شركة TollBit الناشئة لترخيص المحتوى في تقرير لها أن بعض شركات الذكاء الاصطناعي تتجاوز القواعد لجمع المحتوى من مواقع الناشرين.
يأتي هذا بعد أن وجد تحقيق Wired أن شركة البحث بالذكاء الاصطناعي Perplexity ربما تكون قد انتهكت القواعد لمنع برامج الزحف على الويب عبر ملف robots.txt.
وفي وقت سابق من شهر يونيو/حزيران، اتهمت مجلة فوربس الإعلامية أيضًا موقع Perplexity بسرقة مقالاتها الاستقصائية، لاستخدامها في أنظمة الذكاء الاصطناعي التوليدية دون الإسناد.
قالت شركة ريديت يوم الثلاثاء إن الباحثين والمنظمات مثل أرشيف الإنترنت سيستمرون في الوصول إلى محتواها لأغراض غير تجارية.
هوانغ هاي (بحسب رويترز)
[إعلان 2]
المصدر: https://www.congluan.vn/reddit-cap-nhat-giao-thuc-ngan-chan-ai-danh-cap-noi-dung-post300804.html







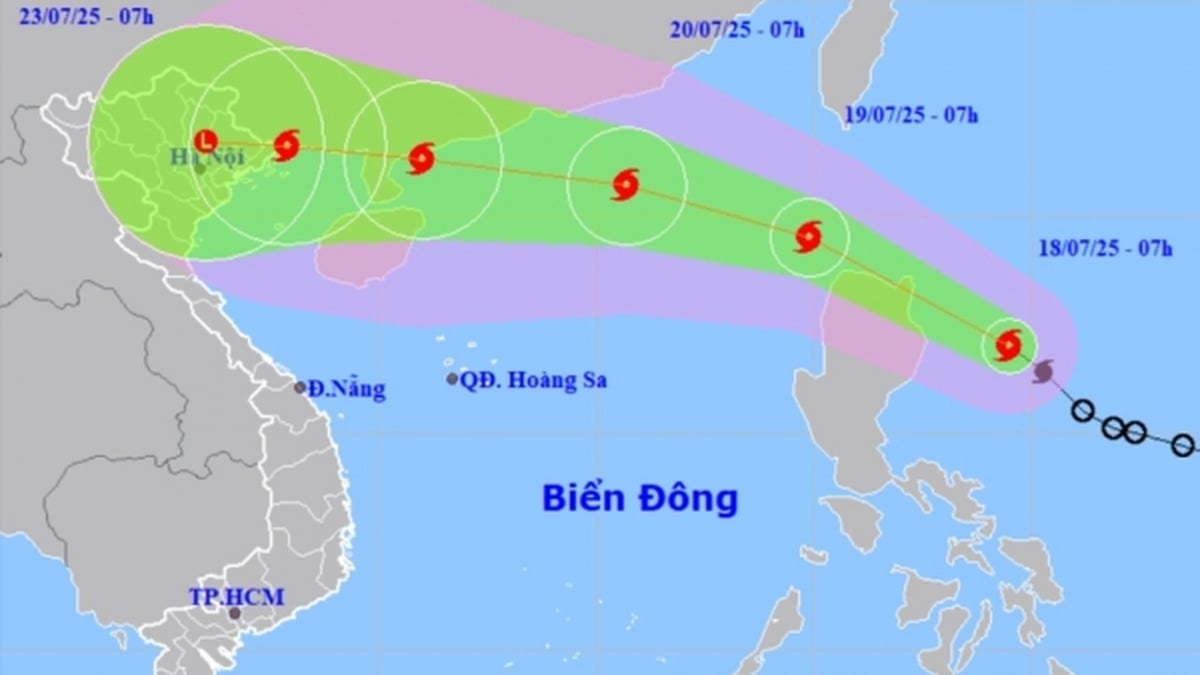

























































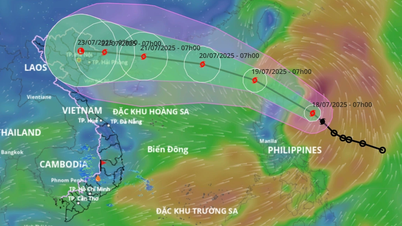




























![[إنفوجراف] في عام 2025، سيحقق 47 منتجًا هدف OCOP الوطني](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/7/16/5d672398b0744db3ab920e05db8e5b7d)






تعليق (0)