
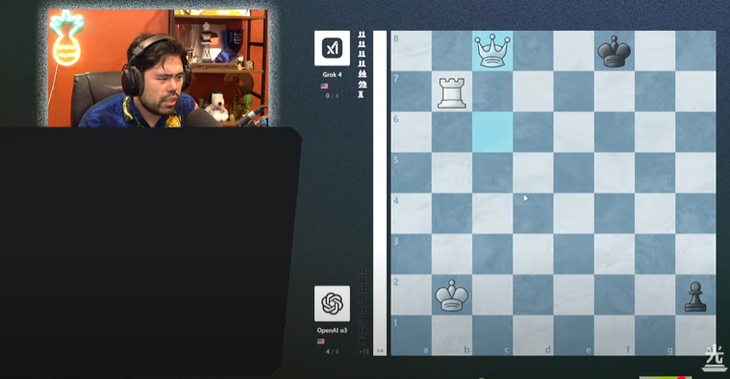
بازیکن ناکامورا گفت که به نظر میرسد گروک ۴ در مسابقه فینال با ذهنیتی پرتنش بازی کرده است - عکس: اسکرین شات
قبل از مسابقه، OpenAI با اعلام راهاندازی یازدهمین نسل LLM، GPT-5، سر و صدای زیادی به پا کرد.
با این حال، مدل o3 - ChatGPT که در مرحله نهایی استفاده شد، همچنان قابلیتهای استنتاج قوی را نشان داد و میانگین نرخ حرکت صحیح آن تا ۹۰.۸ درصد رسید که کاملاً از ۸۰.۲ درصد Grok 4 پیشی گرفت.
در هر چهار بازی، ChatGPT هیچ شانسی به Grok 4 نداد و به ترتیب پس از 35، 30، 28 و 54 حرکت حریفش را مات کرد.
به گفته هیکارو ناکامورا، نفر دوم جهان ، به نظر میرسید که گروک ۴ با تنش بیشتری بازی میکند و اشتباهات بیشتری نسبت به دورهای قبلی مرتکب میشود. به طور خاص، او به راحتی مهرههایش را از دست میداد - اتفاقی نادر که در آن با قاطعیت Gemini 2.5 Flash و Gemini 2.5 Pro گوگل را شکست داد.
با سه برد متوالی با نتیجه ۴-۰ و میانگین دقت شوت ۹۱٪، تیم O3 این مسابقات را به طور بینقصی به پایان رساند.
اگرچه قدرت o3 را نمیتوان با استادان بزرگ شطرنج حرفهای مقایسه کرد، اما به اندازه کافی هست که برای بازیکنانی با سطح الو زیر ۲۰۰۰ مشکل ایجاد کند. به خصوص در دستههای بلیتس و سوپر بلیتس.
مسابقات سازماندهی شده توسط گوگل با برتری مطلق نمایندگان آمریکایی به پایان رسید. در حالی که دو مدل چینی، Kimi K4 و DeepSeek، در مراحل اولیه حذف شدند، مسابقه مقام سوم توسط Gemini 2.5 Pro بر o4-mini پیروز شد و جایگاه شرکتهای پیشرو در فناوری آمریکایی را تثبیت کرد.
این رویداد نه تنها قابلیتهای شگفتانگیز مدلهای هوش مصنوعی عمومی را در یک زمینه تخصصی نشان میدهد، بلکه چشمانداز جدیدی را در مورد پتانسیل توسعه هوش مصنوعی در آینده میگشاید.
با این حال، این همچنین یادآوری میکند که اگرچه LLM ها به سرعت در حال توسعه هستند، اما هنوز نمیتوانند با سطح موتورهای شطرنج حرفهای که رتبهبندی Elo آنها بسیار بالاتر از انسانها است، مطابقت داشته باشند.
منبع: https://tuoitre.vn/chatgpt-dang-quang-giai-co-vua-danh-cho-ai-20250808090405997.htm
![[عکس] نمایشگاه پاییزی ۲۰۲۵ - یک تجربه جذاب](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/30/1761791564603_1761738410688-jpg.webp)



![[عکس] عضو دائمی دبیرخانه، تران کام تو، از مناطق سیلزده دا نانگ بازدید و مردم را تشویق میکند](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/30/1761808671991_bt4-jpg.webp)



























![[عکس] اعضای حزب عصر جدید در «پارک صنعتی سبز»](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/30/1761789456888_1-dsc-5556-jpg.webp)






































































نظر (0)