
ທີມວິໄຈທາງປັນຍາປະດິດ (AI) ທີ່ມະຫາວິທະຍາໄລໂພລີເທກນິກແຫ່ງວາເລນເຊຍ ປະເທດສະເປນ ພົບວ່າເມື່ອຕົວແບບພາສາຂະໜາດໃຫຍ່ກາຍເປັນພາສາທີ່ໃຫຍ່ຂຶ້ນ ແລະມີຄວາມຊັບຊ້ອນຫຼາຍຂຶ້ນ, ເຂົາເຈົ້າມີແນວໂນ້ມທີ່ຈະຍອມຮັບກັບຜູ້ໃຊ້ທີ່ບໍ່ຮູ້ຄຳຕອບ.
") |
| AI ທີ່ສະຫລາດກວ່າ, ມັນເປັນໄປໄດ້ຫນ້ອຍທີ່ຈະຍອມຮັບກັບຜູ້ໃຊ້ວ່າມັນບໍ່ຮູ້ຄໍາຕອບ. (ຮູບພາບ AI) |
ໃນການຄົ້ນຄວ້າທີ່ຕີພິມໃນວາລະສານ Nature , ທີມງານໄດ້ທົດສອບສະບັບຫລ້າສຸດຂອງສາມ AI chatbots ທີ່ນິຍົມທີ່ສຸດກ່ຽວກັບການຕອບສະຫນອງ, ຄວາມຖືກຕ້ອງ, ແລະຄວາມສາມາດຂອງຜູ້ໃຊ້ທີ່ຈະຊອກຫາຄໍາຕອບທີ່ຜິດພາດ.
ເພື່ອທົດສອບຄວາມຖືກຕ້ອງຂອງສາມ LLM ທີ່ນິຍົມຫຼາຍທີ່ສຸດ, BLOOM, LLaMA, ແລະ GPT, ທີມງານໄດ້ຖາມຫລາຍພັນຄໍາຖາມແລະປຽບທຽບຄໍາຕອບທີ່ໄດ້ຮັບກັບສະບັບກ່ອນຫນ້າຂອງຄໍາຖາມດຽວກັນ. ພວກເຂົາຍັງປ່ຽນແປງຫົວຂໍ້ຕ່າງໆ, ລວມທັງຄະນິດສາດ, ວິທະຍາສາດ , ບັນຫາຄໍາສັບ, ແລະພູມສາດ, ເຊັ່ນດຽວກັນກັບຄວາມສາມາດໃນການສ້າງຂໍ້ຄວາມຫຼືການປະຕິບັດເຊັ່ນການຮຽງລໍາດັບ.
ການສຶກສາໄດ້ເປີດເຜີຍບາງແນວໂນ້ມທີ່ໂດດເດັ່ນ. ຄວາມຖືກຕ້ອງໂດຍລວມຂອງ chatbots ປັບປຸງດ້ວຍແຕ່ລະຮຸ່ນໃຫມ່, ແຕ່ຍັງຫຼຸດລົງເມື່ອປະເຊີນກັບຄໍາຖາມທີ່ຍາກກວ່າ. ເປັນເລື່ອງແປກທີ່, ຍ້ອນວ່າ LLMs ກາຍເປັນຂະຫນາດໃຫຍ່ແລະມີຄວາມຊັບຊ້ອນຫຼາຍ, ເຂົາເຈົ້າມັກຈະເປີດຫນ້ອຍລົງກ່ຽວກັບຄວາມສາມາດໃນການຕອບທີ່ຖືກຕ້ອງ.
ໃນຮຸ່ນກ່ອນຫນ້າ, LLM ສ່ວນໃຫຍ່ຈະແຈ້ງໃຫ້ຜູ້ໃຊ້ເປີດເຜີຍໃນເວລາທີ່ພວກເຂົາບໍ່ສາມາດຊອກຫາຄໍາຕອບຫຼືຕ້ອງການຂໍ້ມູນເພີ່ມເຕີມ. ໃນທາງກົງກັນຂ້າມ, ຮຸ່ນໃຫມ່ມີແນວໂນ້ມທີ່ຈະເດົາຫຼາຍ, ເຮັດໃຫ້ຄໍາຕອບໂດຍລວມ, ທັງຖືກຕ້ອງແລະບໍ່ຖືກຕ້ອງ. ສິ່ງທີ່ຫນ້າເປັນຫ່ວງກວ່ານັ້ນ, ການສຶກສາພົບວ່າ LLMs ທັງຫມົດຍັງບາງຄັ້ງໃຫ້ຄໍາຕອບທີ່ບໍ່ຖືກຕ້ອງເຖິງແມ່ນວ່າຄໍາຖາມທີ່ງ່າຍດາຍ, ຊີ້ໃຫ້ເຫັນວ່າຄວາມຫນ້າເຊື່ອຖືຂອງພວກເຂົາຍັງຄົງເປັນບັນຫາທີ່ຕ້ອງການປັບປຸງ.
ການຄົ້ນພົບເຫຼົ່ານີ້ຊີ້ໃຫ້ເຫັນເຖິງຄວາມຂັດແຍ້ງໃນການວິວັດທະນາການຂອງ AI: ໃນຂະນະທີ່ຕົວແບບກໍາລັງມີຄວາມເຂັ້ມແຂງ, ພວກມັນອາດຈະມີຄວາມໂປ່ງໃສຫນ້ອຍກ່ຽວກັບຂໍ້ຈໍາກັດຂອງພວກເຂົາ.
ນີ້ເຮັດໃຫ້ເກີດສິ່ງທ້າທາຍໃຫມ່ໃນການນໍາໃຊ້ແລະຄວາມໄວ້ວາງໃຈຂອງລະບົບ AI, ຮຽກຮ້ອງໃຫ້ຜູ້ໃຊ້ມີຄວາມລະມັດລະວັງຫຼາຍກວ່າເກົ່າແລະຜູ້ພັດທະນາສຸມໃສ່ການປັບປຸງບໍ່ພຽງແຕ່ຄວາມຖືກຕ້ອງເທົ່ານັ້ນ, ແຕ່ຍັງເປັນ "ການຮັບຮູ້ຕົນເອງ" ຂອງແບບຈໍາລອງ.
ທີ່ມາ: https://baoquocte.vn/cang-thong-minh-tri-tue-nhan-tao-cang-co-xu-huong-giau-dot-287987.html





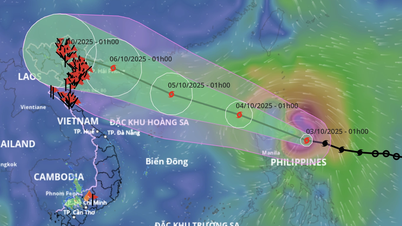
![[ຮູບພາບ] ຂົວ 1 Binh Trieu ໄດ້ສ້າງສໍາເລັດ, ຍົກສູງຂຶ້ນ 1,1 ແມັດ, ແລະຈະເປີດການຈະລາຈອນໃນທ້າຍເດືອນພະຈິກ.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/2/a6549e2a3b5848a1ba76a1ded6141fae)






























































































(0)