

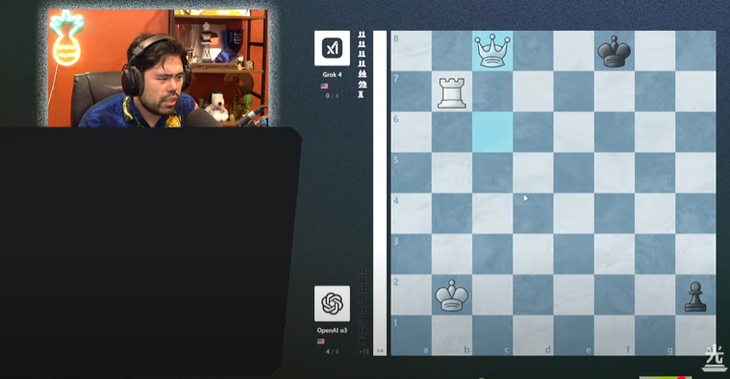
ຜູ້ນ Nakamura ເວົ້າວ່າ Grok 4 ເບິ່ງຄືວ່າຈະຫຼິ້ນກັບຈິດໃຈທີ່ເຄັ່ງຕຶງໃນການແຂ່ງຂັນສຸດທ້າຍ - ຮູບພາບ: screenshot
ກ່ອນການແຂ່ງຂັນ, OpenAI ໄດ້ສ້າງຄວາມວຸ້ນວາຍເມື່ອປະກາດເປີດຕົວ LLM ລຸ້ນທີ 11, GPT-5.
ຢ່າງໃດກໍ່ຕາມ, ຮູບແບບ o3 - ChatGPT ທີ່ໃຊ້ໃນຂັ້ນສຸດທ້າຍຍັງສະແດງໃຫ້ເຫັນຄວາມສາມາດໃນການສົມເຫດສົມຜົນທີ່ເຂັ້ມແຂງ, ມີອັດຕາການເຄື່ອນຍ້າຍທີ່ຖືກຕ້ອງໂດຍສະເລ່ຍເຖິງ 90.8%, ເກີນທັງຫມົດ Grok 4 ຂອງ 80.2%.
ໃນທັງຫມົດສີ່ເກມ, ChatGPT ບໍ່ໄດ້ໃຫ້ Grok 4 ໂອກາດ, checkmating opponent ລາວຫຼັງຈາກ 35, 30, 28 ແລະ 54 ຍ້າຍຕາມລໍາດັບ.
ອີງຕາມການອັນດັບ 2 ຂອງໂລກ Hikaru Nakamura, Grok 4 ເບິ່ງຄືວ່າຈະຫຼີ້ນກັບຄວາມກົດດັນແລະເຮັດຜິດພາດຫຼາຍກ່ວາໃນຮອບທີ່ຜ່ານມາ. ໂດຍສະເພາະ, ມັນສູນເສຍຕ່ອນໄດ້ຢ່າງງ່າຍດາຍ - ເປັນປະກົດການທີ່ຫາຍາກໃນເວລາທີ່ມັນ overwhelmingly defeat Gemini 2.5 Flash ແລະ Gemini 2.5 Pro ຂອງກູໂກ.
ດ້ວຍໄຊຊະນະສາມຄັ້ງຕິດຕໍ່ກັນດ້ວຍຄະແນນ 4-0 ແລະອັດຕາຄວາມຖືກຕ້ອງໂດຍສະເລ່ຍສູງເຖິງ 91%, o3 ຈົບການແຂ່ງຂັນຢ່າງສົມບູນ.
ເຖິງແມ່ນວ່າພະລັງງານຂອງ o3 ບໍ່ສາມາດປຽບທຽບກັບນາຍໃຫຍ່ຫມາກຮຸກມືອາຊີບ, ມັນພຽງພໍທີ່ຈະເຮັດໃຫ້ເກີດຄວາມຫຍຸ້ງຍາກສໍາລັບຜູ້ຫຼິ້ນທີ່ມີ Elo ຕ່ໍາກວ່າ 2,000. ໂດຍສະເພາະໃນປະເພດຂອງ blitz ແລະ super blitz.
ການແຂ່ງຂັນທີ່ຈັດໂດຍ Google ສິ້ນສຸດລົງດ້ວຍການຄອບງໍາຢ່າງແທ້ຈິງຂອງຜູ້ຕາງຫນ້າອາເມລິກາ. ໃນຂະນະທີ່ສອງຕົວແບບຂອງຈີນ, Kimi K4 ແລະ DeepSeek, ທັງສອງໄດ້ຖືກລົບລ້າງໃນຕອນຕົ້ນ, ການແຂ່ງຂັນອັນດັບສາມໄດ້ເຫັນໄຊຊະນະຂອງ Gemini 2.5 Pro ຫຼາຍກວ່າ o4-mini, ຢືນຢັນຕໍາແຫນ່ງຂອງບໍລິສັດເຕັກໂນໂລຢີຊັ້ນນໍາຂອງອາເມລິກາ.
ເຫດການນີ້ບໍ່ພຽງແຕ່ສະແດງໃຫ້ເຫັນຄວາມສາມາດທີ່ຫນ້າອັດສະຈັນຂອງແບບຈໍາລອງ AI ທົ່ວໄປໃນສາຂາວິຊາສະເພາະ. ມັນຍັງເປີດທັດສະນະໃຫມ່ກ່ຽວກັບການພັດທະນາທ່າແຮງຂອງປັນຍາປະດິດໃນອະນາຄົດ.
ຢ່າງໃດກໍຕາມ, ມັນຍັງເປັນການເຕືອນວ່າໃນຂະນະທີ່ LLMs ກໍາລັງພັດທະນາຢ່າງໄວວາ, ພວກເຂົາຍັງບໍ່ສາມາດທຽບກັບລະດັບຂອງເຄື່ອງຈັກ chess ມືອາຊີບ, ເຊິ່ງ Elo rating ສູງກວ່າມະນຸດ.
ທີ່ມາ: https://tuoitre.vn/chatgpt-dang-quang-giai-co-vua-danh-cho-ai-20250808090405997.htm


![[ຮູບພາບ] ທ່ານປະທານປະເທດ ເລືອງເກື່ອງ ໄດ້ໃຫ້ການຕ້ອນຮັບທ່ານຜູ້ວ່າການລັດ ອົດສະຕາລີ](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/10/a00546a3d7364bbc81ee51aae9ef8383)

![[ຮູບພາບ] ທໍ່ສົ່ງນ້ໍາຂະຫນາດໃຫຍ່ນໍາໄປສູ່ທະເລສາຕາເວັນຕົກ, ປະກອບສ່ວນເພື່ອຟື້ນຟູໃຫ້ນ້ໍາ Lich](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/10/887e1aab2cc643a0b2ef2ffac7cb00b4)
![[ຮູບພາບ] ທ່ານນາຍົກລັດຖະມົນຕີ ຟ້າມບິ່ງມິງ ເປັນປະທານກອງປະຊຸມຄັ້ງທີ 20 ຂອງຄະນະຊີ້ນຳບັນດາໂຄງການ ແລະ ວຽກງານສຳຄັນແຫ່ງຊາດ.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/10/e82d71fd36eb4bcd8529c8828d64f17c)


























































































(0)