Les GPU sont le cerveau des ordinateurs dotés d'intelligence artificielle.
En termes simples, l'unité de traitement graphique (GPU) agit comme le cerveau d'un ordinateur d'IA.
Comme vous le savez peut-être déjà, le processeur (CPU) est le cerveau d'un ordinateur. L'avantage d'un GPU réside dans le fait qu'il s'agit d'un processeur spécialisé dans les calculs complexes. La méthode la plus rapide pour effectuer ces calculs consiste à faire travailler plusieurs GPU simultanément pour résoudre un problème. Malgré cela, l'entraînement d'un modèle d'IA peut prendre des semaines, voire des mois. Une fois construit, le modèle est placé sur le système informatique frontal, et les utilisateurs peuvent lui poser des questions ; ce processus est appelé inférence.
Un ordinateur doté d'une IA contient plusieurs GPU.
L'architecture optimale pour résoudre les problèmes d'IA consiste à utiliser un ensemble de GPU dans une baie, connectés à un commutateur situé en haut de cette baie. Plusieurs baies de GPU peuvent être interconnectées au sein d'un réseau hiérarchique. À mesure que les problèmes à résoudre se complexifient, les besoins en GPU augmentent également, certains projets pouvant nécessiter le déploiement de clusters de plusieurs milliers de GPU.
Chaque cluster d'IA est un petit réseau.
Lors de la construction d'un cluster d'IA, il est nécessaire de mettre en place un petit réseau informatique pour connecter les GPU et leur permettre de travailler ensemble et de partager efficacement les données.
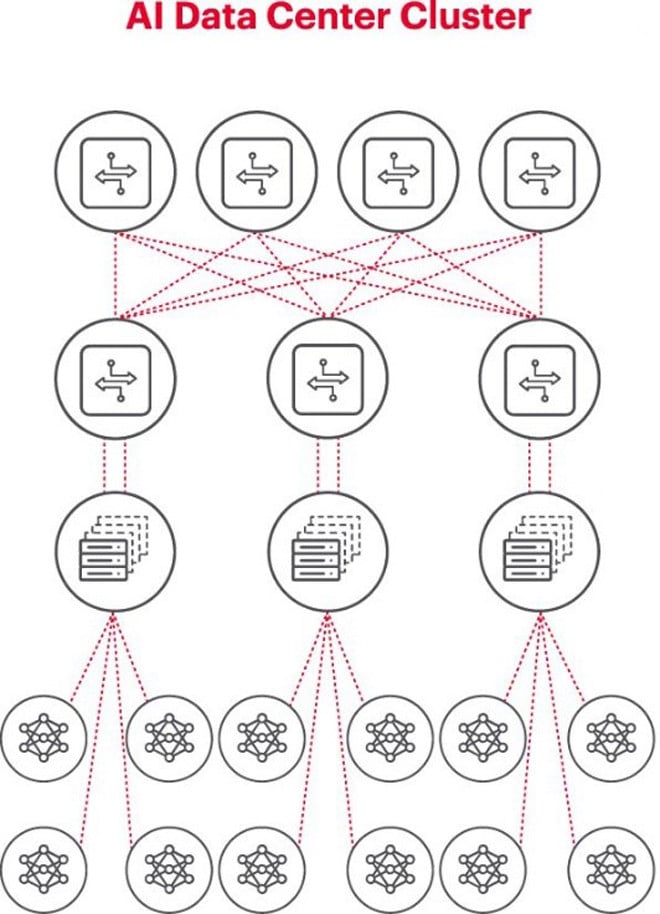
Le schéma ci-dessus illustre un cluster d'IA où les cercles en bas représentent les flux de travail exécutés sur des GPU. Les GPU sont connectés à des commutateurs situés sur le rack supérieur (ToR). Ces commutateurs ToR sont eux-mêmes connectés aux commutateurs du réseau principal, également représentés sur le schéma, ce qui met en évidence la hiérarchie réseau nécessaire lorsqu'il y a plusieurs GPU.



Les réseaux constituent un goulot d'étranglement dans le déploiement de l'IA.
L'automne dernier, lors du sommet mondial de l'Open Computer Project (OCP), où les délégués construisaient la prochaine génération d'infrastructures d'IA, le délégué Loi Nguyen de Marvell Technology a souligné un problème clé : « les réseaux sont le nouveau goulot d'étranglement ».
Techniquement, une latence élevée ou une perte de paquets due à la congestion du réseau peuvent entraîner la réémission de paquets, augmentant considérablement le temps d'exécution des tâches (JCT). Par conséquent, des millions, voire des dizaines de millions de dollars, de GPU appartenant à des entreprises sont gaspillés à cause de systèmes d'IA inefficaces, ce qui nuit à leurs revenus et allonge les délais de commercialisation.
Les tests et les mesures sont des conditions essentielles au bon fonctionnement des réseaux d'IA.
Pour qu'un cluster d'IA fonctionne efficacement, les GPU doivent exploiter pleinement leur capacité afin de réduire le temps d'entraînement et d'implémenter des modèles d'apprentissage optimisant ainsi le retour sur investissement. Il est donc nécessaire de tester et d'évaluer les performances du cluster d'IA (Figure 2). Cependant, cette tâche est complexe, car l'architecture du système implique de nombreux paramètres et interactions entre le GPU et la structure du réseau, qui doivent être complémentaires pour résoudre le problème.
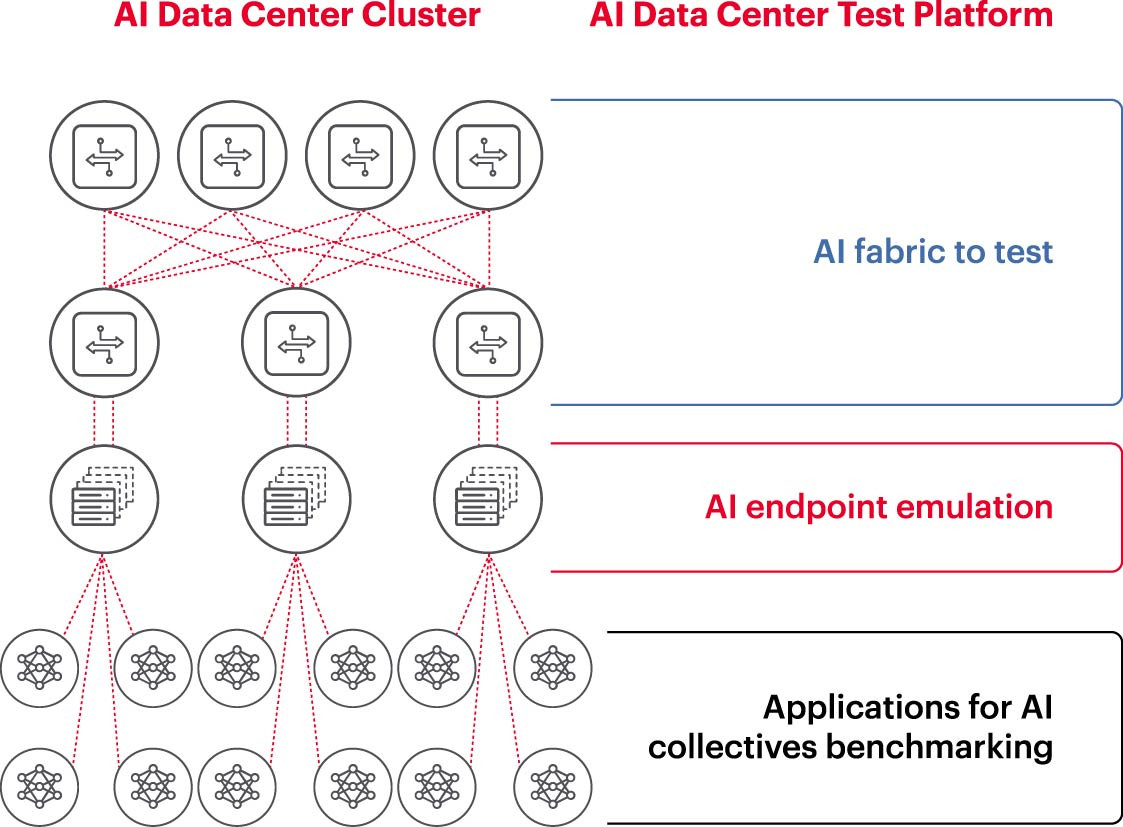
Cela engendre de nombreuses difficultés et défis dans la mesure des réseaux d'IA :
- La difficulté de reproduire l'intégralité du réseau de production en laboratoire tient aux limitations de coût, d'équipement, à la pénurie d'ingénieurs en réseaux d'IA hautement qualifiés, à l'espace, à l'alimentation électrique et à la température.
- Les tests effectués sur le système de production réduisent la capacité de traitement disponible du système de production lui-même.
- Difficulté à reproduire fidèlement les problèmes en raison des différences d'échelle et de portée de ces derniers.



- La complexité de la manière dont les GPU se connectent collectivement.
Pour relever ces défis, les entreprises peuvent réaliser des tests comparatifs sur un sous-ensemble de configurations proposées en environnement de laboratoire afin d'évaluer des paramètres clés tels que le JCT (temps d'exécution des tâches), la bande passante accessible à l'équipe d'IA, et de les comparer à l'utilisation de la plateforme de commutation et du cache. Ces tests permettent de trouver le juste équilibre entre la charge de travail du GPU/traitement et la conception/installation du réseau. Une fois satisfaits des résultats, les architectes informatiques et les ingénieurs réseau peuvent déployer ces configurations en production et mesurer les nouveaux résultats.
Les laboratoires de recherche d'entreprise, les instituts de recherche et les universités s'efforcent d'analyser chaque aspect de la conception et de l'exploitation de réseaux d'IA performants afin de relever les défis liés à la gestion de grands réseaux, d'autant plus que les bonnes pratiques évoluent constamment. Cette approche collaborative et reproductible est la seule façon pour les entreprises d'effectuer des mesures répétables et des tests rapides de scénarios « si-alors », éléments fondamentaux pour l'optimisation des réseaux basés sur l'IA.
(Source : Keysight Technologies)
Source : https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html



![[Image] Conférence nationale résumant une année de fonctionnement du modèle organisationnel global du système politique, le modèle de gouvernement à trois niveaux.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/07/01/1782882811691_ndo_br_1-jpg.webp)