
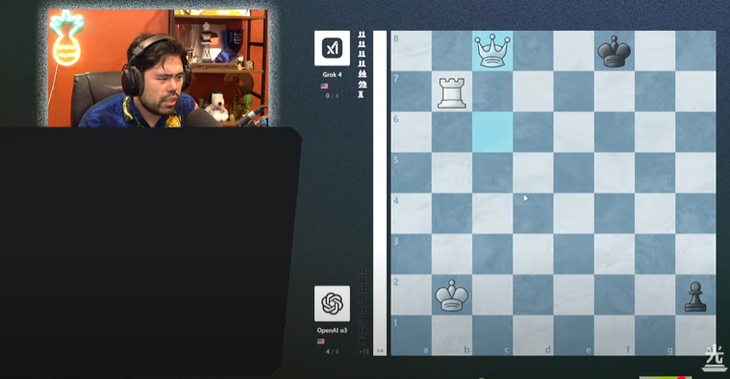
ผู้เล่นนากามูระกล่าวว่า Grok 4 ดูเหมือนจะเล่นด้วยอารมณ์ที่ตึงเครียดในแมตช์สุดท้าย - รูปภาพ: ภาพหน้าจอ
ก่อนการแข่งขัน OpenAI สร้างความฮือฮาเมื่อประกาศเปิดตัว LLM รุ่นที่ 11 หรือ GPT-5
อย่างไรก็ตาม โมเดล o3 - ChatGPT ที่ใช้ในรอบสุดท้ายยังคงแสดงให้เห็นถึงความสามารถในการใช้เหตุผลที่แข็งแกร่ง โดยมีอัตราการเคลื่อนไหวที่ถูกต้องโดยเฉลี่ยสูงถึง 90.8% ซึ่งแซงหน้า 80.2% ของ Grok 4 อย่างสิ้นเชิง
ในทั้ง 4 เกม ChatGPT ไม่เปิดโอกาสให้ Grok 4 เลย โดยสามารถรุกฆาตคู่ต่อสู้ได้หลังจากผ่านไป 35, 30, 28 และ 54 ตา ตามลำดับ
ฮิคารุ นากามูระ มือวางอันดับ 2 ของโลก เผยว่า Grok 4 ดูเหมือนจะเล่นด้วยความตึงเครียดและผิดพลาดมากกว่ารอบก่อนๆ โดยเฉพาะอย่างยิ่ง พวกเขาเสียเปรียบได้ง่าย ซึ่งเกิดขึ้นได้ยากเมื่อเอาชนะ Gemini 2.5 Flash และ Gemini 2.5 Pro ของ Google อย่างขาดลอย
ด้วยชัยชนะติดต่อกัน 3 ครั้งด้วยคะแนน 4-0 และอัตราความแม่นยำเฉลี่ยสูงถึง 91% o3 จึงปิดฉากการแข่งขันได้อย่างสมบูรณ์แบบ
แม้ว่าพลังของ o3 จะเทียบไม่ได้กับปรมาจารย์หมากรุกมืออาชีพ แต่มันก็เพียงพอที่จะสร้างความยากให้กับผู้เล่นที่มี Elo ต่ำกว่า 2,000 โดยเฉพาะในประเภทบลิตซ์และซูเปอร์บลิตซ์
การแข่งขันที่จัดโดย Google สิ้นสุดลงด้วยความโดดเด่นของตัวแทนจากสหรัฐอเมริกา แม้ว่าโมเดลชาวจีนสองรุ่น ได้แก่ Kimi K4 และ DeepSeek จะตกรอบไปตั้งแต่ช่วงต้น แต่การแข่งขันชิงอันดับสามกลับเป็นชัยชนะของ Gemini 2.5 Pro เหนือ o4-mini ซึ่งตอกย้ำตำแหน่งของบริษัทเทคโนโลยีชั้นนำของอเมริกา
งานนี้ไม่เพียงแต่แสดงให้เห็นถึงความสามารถอันน่าทึ่งของโมเดล AI อเนกประสงค์ในสาขาเฉพาะทางเท่านั้น แต่ยังเปิดมุมมองใหม่เกี่ยวกับศักยภาพการพัฒนาปัญญาประดิษฐ์ในอนาคตอีกด้วย
อย่างไรก็ตาม มันยังเป็นการเตือนใจอีกด้วยว่า แม้ว่า LLM จะพัฒนาอย่างรวดเร็ว แต่ก็ยังไม่สามารถเทียบเคียงได้กับระดับของโปรแกรมเล่นหมากรุกระดับมืออาชีพ ซึ่งระดับ Elo ของมันนั้นสูงเกินกว่ามนุษย์มาก
ที่มา: https://tuoitre.vn/chatgpt-dang-quang-giai-co-vua-danh-cho-ai-20250808090405997.htm




























































































การแสดงความคิดเห็น (0)