
لم تكشف OpenAI الكثير عن كيفية تدريب ChatGPT-4. مع ذلك، عادةً ما تُدرَّب نماذج اللغات الكبيرة (LLMs) على نصوص مُستخلصة من الإنترنت، حيث تُعتبر اللغة الإنجليزية هي اللغة المُستخدمة. حوالي 93% من بيانات تدريب ChatGPT-3 مُستخدمة باللغة الإنجليزية.
في قاعدة بيانات Common Crawl، وهي واحدة فقط من مجموعات البيانات التي دُرِّب عليها نموذج الذكاء الاصطناعي، تُشكِّل اللغة الإنجليزية 47% من المجموعة، بينما تُشكِّل اللغات الأوروبية الأخرى 38% إضافية. في المقابل، تُشكِّل اللغتان الصينية واليابانية مجتمعتين 9% فقط.

هذه ليست مشكلةً تقتصر على ChatGPT فحسب، كما وجد ناثانيال روبنسون، الباحث في جامعة جونز هوبكنز، وزملاؤه. فقد كان أداء جميع برامج ماجستير الحقوق أفضل في اللغات "عالية الموارد"، حيث كانت بيانات التدريب وفيرة، مقارنةً باللغات "منخفضة الموارد"، حيث كانت البيانات نادرة.
تُمثل هذه مشكلةً لمن يأملون في جلب الذكاء الاصطناعي إلى الدول الفقيرة لتحسين مجالاتٍ من التعليم إلى الصحة. ونتيجةً لذلك، يعمل الباحثون حول العالم على جعل الذكاء الاصطناعي أكثر تعددًا للغات.
في سبتمبر/أيلول الماضي، أطلقت الحكومة الهندية برنامج دردشة آلي لمساعدة المزارعين على البقاء على اطلاع دائم بالمعلومات المفيدة من الحكومة.
قال شانكار ماروادا، من مؤسسة إكستيب، وهي منظمة غير ربحية ساهمت في تطوير روبوت المحادثة، إن الروبوت يعمل بدمج نوعين من نماذج اللغة، مما يسمح للمستخدمين بإرسال استفساراتهم بلغتهم الأم. تُمرر هذه الاستفسارات إلى برنامج ترجمة آلية في مركز أبحاث هندي، يترجمها بدوره إلى الإنجليزية قبل إرسال الرد إلى برنامج LLM الذي يعالج الرد. وأخيرًا، تُترجم الاستجابة مرة أخرى إلى لغة المستخدم الأم.
قد تنجح هذه العملية، لكن ترجمة الاستفسارات إلى اللغة "المفضلة" لبرنامج ماجستير القانون تُعدّ حلاً بديلاً غير متقن. فاللغة انعكاس للثقافة ورؤية العالم . وقد وجدت ورقة بحثية نُشرت عام ٢٠٢٢ من قِبل ريبيكا جونسون، الباحثة في جامعة سيدني، أن ChatGPT-3 قدّم إجابات حول مواضيع مثل ضبط الأسلحة وسياسة اللاجئين، تُضاهي القيم الأمريكية الواردة في استطلاع القيم العالمية.
نتيجةً لذلك، يسعى العديد من الباحثين إلى جعل برامج الماجستير في القانون (LLM) مُتقنة للغات الأقل استخدامًا. من الناحية التقنية، تتمثل إحدى الطرق في تعديل مُجزئ اللغة. وقد طورت شركة ناشئة هندية تُدعى Sarvam AI مُجزئًا مُحسّنًا للغة الهندية، أو نموذج OpenHathi - وهو برنامج ماجستير في القانون (LLM) مُحسّن للغة الديفاناغارية (الهند)، مما يُقلل بشكل كبير من تكلفة الإجابة على الأسئلة.
هناك طريقة أخرى لتحسين مجموعات البيانات التي يُدرَّب عليها برنامج LLM. في نوفمبر، أصدر فريق من الباحثين في جامعة محمد بن زايد بأبوظبي أحدث نسخة من نموذجهم الناطق باللغة العربية، المسمى "جيس". يحتوي هذا النموذج على سدس عدد معلمات ChatGPT-3، ولكنه يُقدم أداءً جيدًا تقريبًا باللغة العربية.
أشار تيموثي بالدوين، رئيس جامعة محمد بن زايد، إلى أنه على الرغم من قيام فريقه برقمنة الكثير من النصوص العربية، إلا أن بعض النصوص الإنجليزية لا تزال مُضمنة في النموذج. بعض المفاهيم متشابهة في جميع اللغات، ويمكن تعلمها بأي لغة.
النهج الثالث هو ضبط النماذج بدقة بعد تدريبها. يمتلك كلٌّ من Jais وOpenHathi عددًا من أزواج الأسئلة والأجوبة المُولّدة بشريًا. وينطبق الأمر نفسه على روبوتات الدردشة الغربية، لمنع المعلومات المضللة.
تم تصميم إرني بوت، الحاصل على ماجستير في القانون من بايدو، وهي شركة تقنية صينية كبيرة، للحد من الكلام الذي قد يُسيء إلى الحكومة. كما يمكن للنماذج التعلم من ردود الفعل البشرية، حيث يُقيّم المستخدمون إجابات الحاصل على ماجستير القانون. لكن هذا الأمر صعب التنفيذ في العديد من اللغات في المناطق الأقل نموًا نظرًا للحاجة إلى توظيف أشخاص مؤهلين لنقد إجابات الآلة.
(وفقا لمجلة الإيكونوميست)

[إعلان 2]
مصدر
![[صورة] افتتاح مهرجان الثقافة العالمي في هانوي](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/10/1760113426728_ndo_br_lehoi-khaimac-jpg.webp)
![[صورة] اكتشف تجارب فريدة في أول مهرجان ثقافي عالمي](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/11/1760198064937_le-hoi-van-hoa-4199-3623-jpg.webp)

![[صورة] الأمين العام يحضر العرض العسكري للاحتفال بالذكرى الثمانين لتأسيس حزب العمال الكوري](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/11/1760150039564_vna-potal-tong-bi-thu-du-le-duyet-binh-ky-niem-80-nam-thanh-lap-dang-lao-dong-trieu-tien-8331994-jpg.webp)


























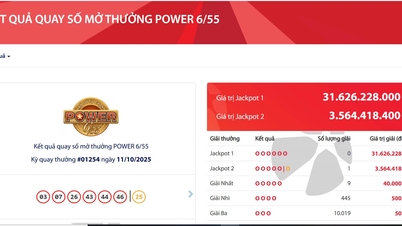



![[صورة] مدينة هوشي منه تتزين بالأعلام والزهور عشية انعقاد المؤتمر الحزبي الأول للفترة 2025-2030](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/10/1760102923219_ndo_br_thiet-ke-chua-co-ten-43-png.webp)
































































تعليق (0)