
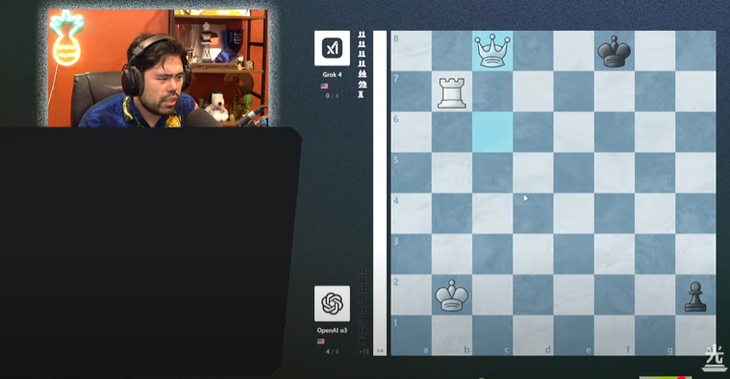
Player Nakamura said that Grok 4 seemed to have played with a tense mentality in the final match - Photo: screenshot
Before the match, OpenAI made a stir when it announced the launch of the 11th generation of LLM, GPT-5.
However, the o3 - ChatGPT model used in the final still showed strong inference capabilities, with an average correct move rate of up to 90.8%, completely surpassing Grok 4's 80.2%.
In all four games, ChatGPT did not give Grok 4 any chance, checkmating his opponent after 35, 30, 28 and 54 moves respectively.
According to world No. 2 Hikaru Nakamura, Grok 4 seemed to be playing with more tension and making more mistakes than in previous rounds. In particular, it lost pieces easily - a rare occurrence when it overwhelmingly defeated Google's Gemini 2.5 Flash and Gemini 2.5 Pro.
With three wins in a row with a score of 4-0 and an average accuracy rate of up to 91%, o3 ended the tournament perfectly.
Although o3's strength cannot be compared to professional chess grandmasters, it is enough to cause trouble for players with Elo below 2,000. Especially in blitz and super blitz categories.
The Google-organized tournament ended with the absolute dominance of the American representatives. While the two Chinese models, Kimi K4 and DeepSeek, were eliminated early, the third-place match was won by Gemini 2.5 Pro over o4-mini, affirming the position of the leading American technology companies.
This event not only shows the amazing capabilities of general-purpose AI models in a specialized field. It also opens a new perspective on the development potential of artificial intelligence in the future.
However, it is also a reminder that while LLMs are developing rapidly, they still cannot match the level of professional chess engines, whose Elo ratings far exceed those of humans.
Source: https://tuoitre.vn/chatgpt-dang-quang-giai-co-vua-danh-cho-ai-20250808090405997.htm





![[Photo] Prime Minister Pham Minh Chinh chairs the first meeting of the Central Steering Committee on housing policy and real estate market](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/22/c0f42b88c6284975b4bcfcf5b17656e7)


























































































Comment (0)