


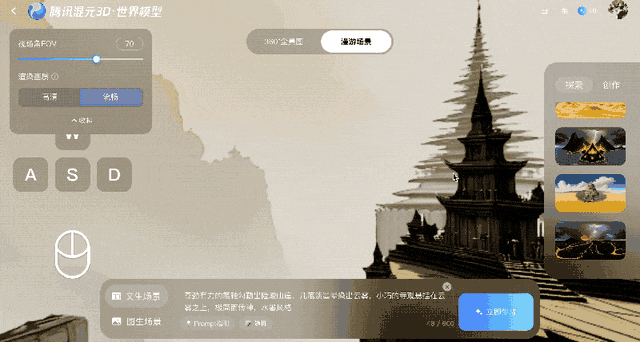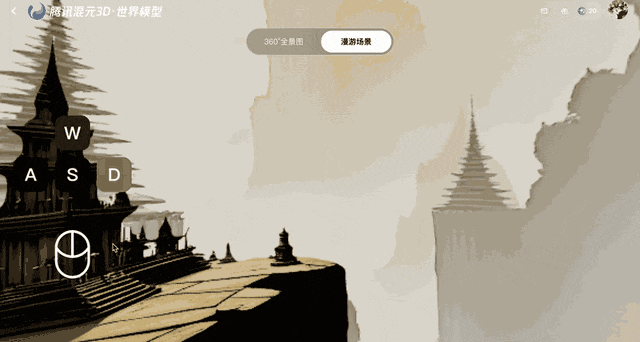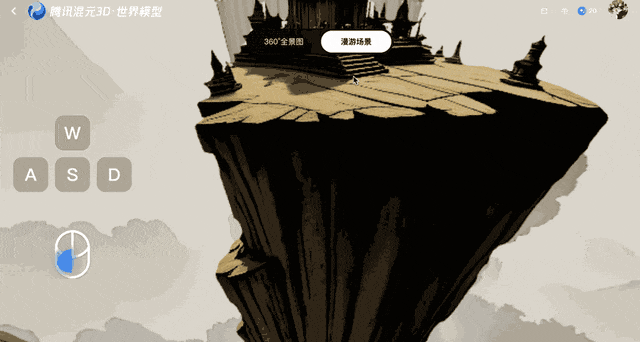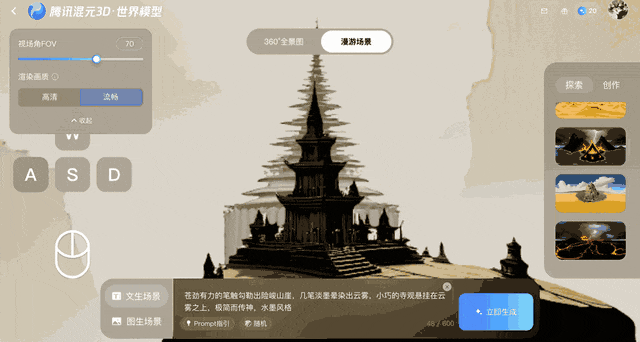
Tencent, la société technologique leader en Chine, vient d'annoncer un nouveau modèle d'intelligence artificielle, capable de créer des vidéos simulant le mouvement dans un espace tridimensionnel avec une seule image d'entrée.

Baptisé HunyuanWorld-Voyager, le système génère de courts clips contenant des informations de profondeur, qui peuvent ensuite être reconstruites dans une matrice de points 3D, ouvrant ainsi de nouvelles possibilités aux créateurs de contenu, même s'il ne parvient pas à interagir pleinement avec les modèles 3D.
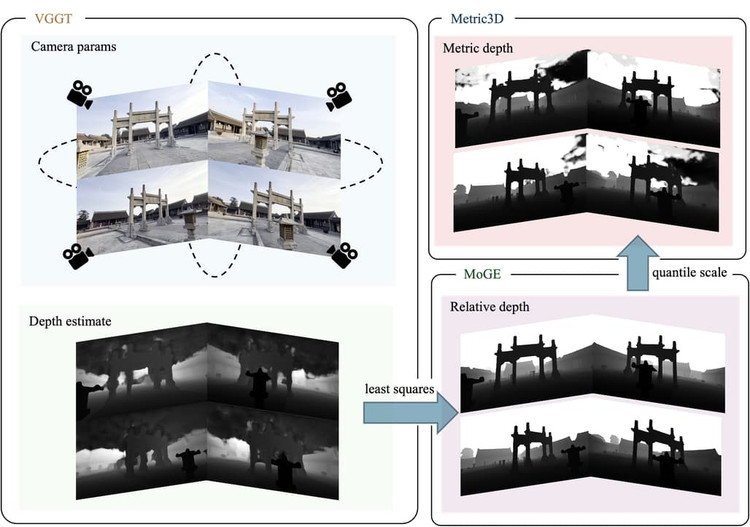
HunyuanWorld-Voyager est un modèle pondéré ouvert qui génère des séquences de 49 images — environ deux secondes de vidéo — mais les utilisateurs peuvent relier des clips entre eux pour créer plusieurs minutes de séquences continues.
Ars Technica constate que lorsque le spectateur modifie la perspective de la caméra virtuelle, les objets conservent leurs positions relatives et l'environnement se comporte comme s'il était entièrement tridimensionnel. Bien que le résultat final soit toujours une vidéo bidimensionnelle, Tencent affirme que les données de profondeur associées permettent une reconstruction 3D sans recourir aux techniques de modélisation traditionnelles.

Voyager fonctionne en combinant des images d'entrée avec des trajectoires de caméra définies par l'utilisateur. L'utilisateur spécifie des mouvements tels que des panoramiques, des inclinaisons ou des déplacements dans la scène, et le système génère simultanément une vidéo couleur et une carte de profondeur. Lorsqu'un objet apparaît dans la vidéo, les données de profondeur de sortie enregistrent sa distance relative par rapport à l'emplacement correct.
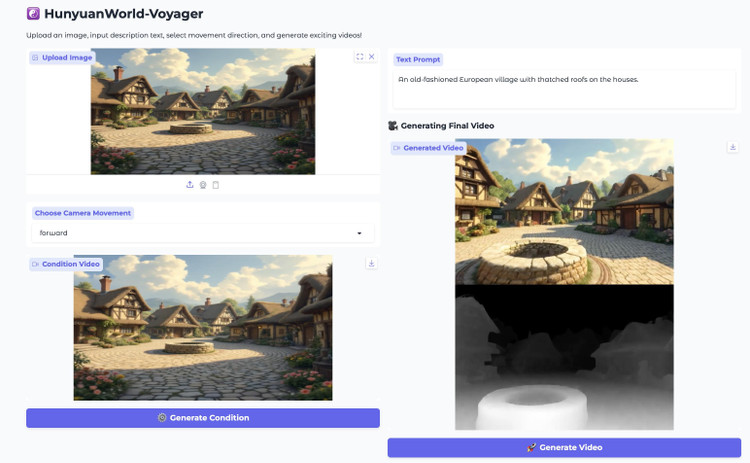
Un composant secondaire, appelé cache mondial dans le document technique de Tencent, stocke des nuages de points 3D à mesure que le système génère de nouvelles images.

À chaque mouvement de caméra, Voyager projette ces points en deux dimensions et les utilise comme référence. Ce processus garantit que les images suivantes correspondent au contenu généré précédemment, contribuant ainsi à maintenir la cohérence spatiale.
Ce modèle protège contre la distorsion après la création des images en les convertissant en points 3D, qui sont ensuite renvoyés au système pour comparaison. Cette boucle de rétroaction garantit la stabilité géométrique, même si les erreurs s'accumulent au fil du temps.
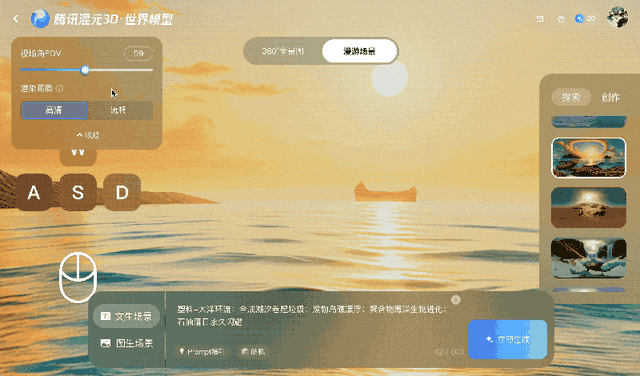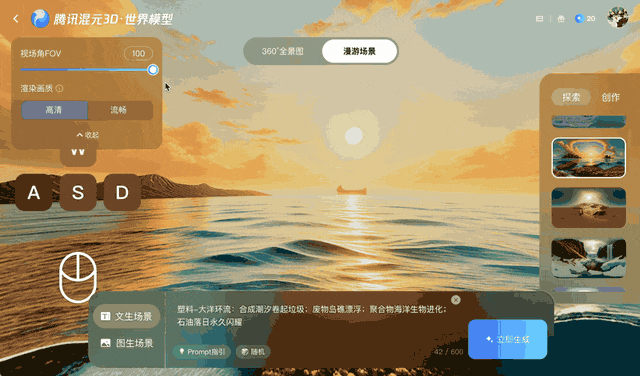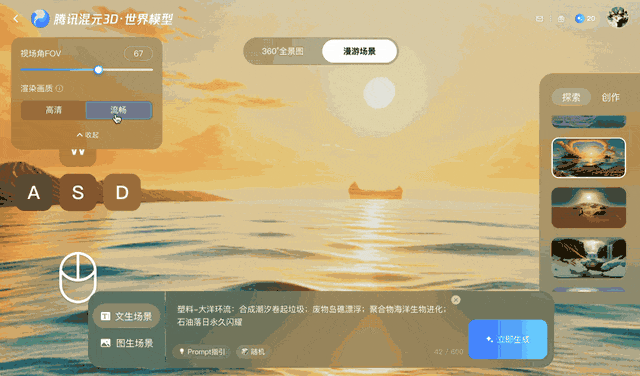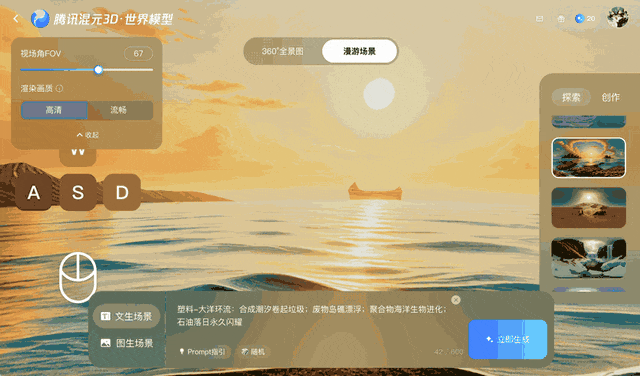
Cette méthode maintient une vidéo cohérente pendant quelques minutes, mais présente des difficultés avec des mouvements de caméra plus longs ou plus complexes, en particulier les rotations à 360°.
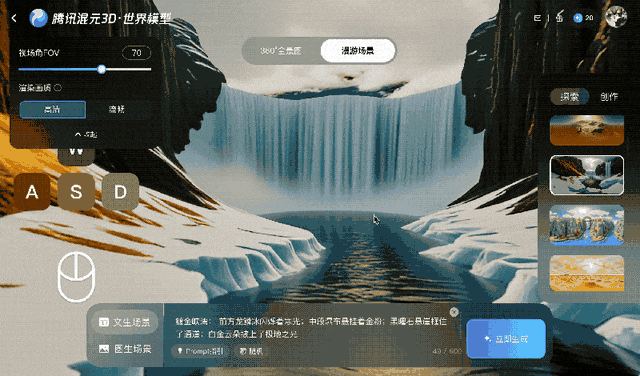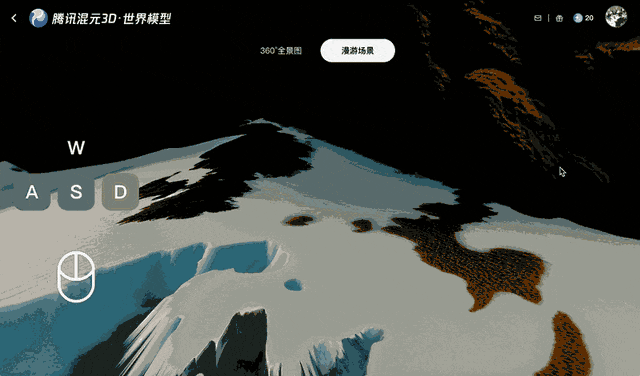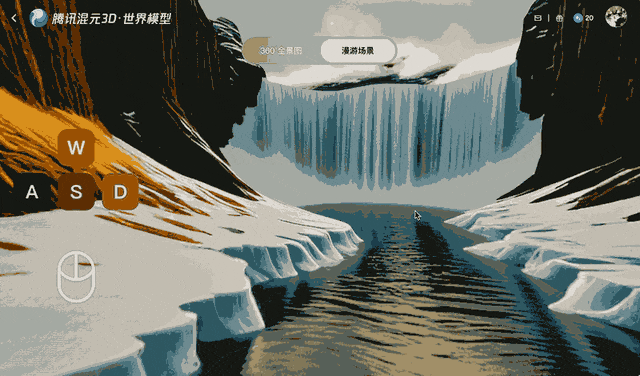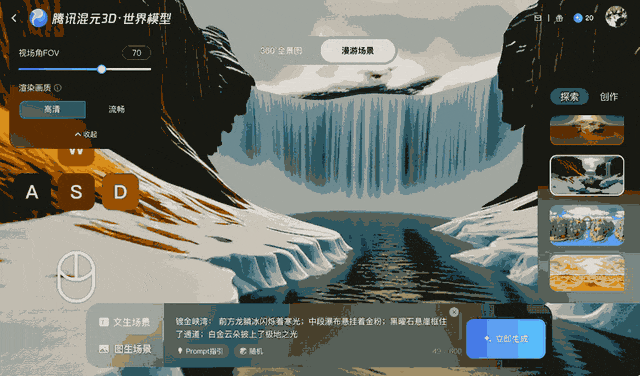
Tencent a entraîné Voyager sur plus de 100 000 clips vidéo, dont des séquences réelles et des scènes créées avec Unreal Engine. Cet ensemble de données à grande échelle a appris au système comment les caméras se déplacent généralement dans un environnement tridimensionnel. Un processus automatisé distinct a généré des données d'entraînement en scannant les clips vidéo pour calculer la profondeur de chaque image, éliminant ainsi le besoin d'étiqueter manuellement les données.

Le système requiert une puissance de calcul considérable. L'exécution du modèle en résolution 540p nécessite au moins 60 Go de mémoire GPU, 80 Go étant recommandés pour des résultats optimaux. Tencent a annoncé que le modèle est compatible avec Hugging Face et prend en charge les configurations mono-GPU et multi-GPU. Grâce à la plateforme xDiT, l'entreprise affirme que les performances évoluent horizontalement : un système équipé de huit GPU peut traiter les séquences environ 6,7 fois plus vite qu'avec un seul GPU.

La plupart des modèles vidéo génératifs génèrent chaque image sans appliquer de cohérence géométrique. Par exemple, Sora d'OpenAI privilégie le réalisme visuel à la cohérence 3D. Voyager adopte une approche différente, préservant une géométrie nette d'une image à l'autre grâce à la correspondance de motifs basée sur le feedback plutôt qu'à une compréhension 3D complète.

Au WorldScore, une échelle développée par des chercheurs de Stanford pour évaluer les systèmes de génération de mondes 3D, Voyager a obtenu un score de 77,62. Le rapport de Tencent indique qu'il s'agit du score le plus élevé parmi les modèles comparables, surpassant les 72,69 de WonderWorld et les 62,15 de CogVideoX-I2V. Voyager a surpassé WonderWorld en termes de cohérence stylistique et de qualité subjective, mais a été moins performant en termes de contrôle de la caméra.

Malgré des résultats prometteurs, le système présente un inconvénient majeur : certaines restrictions de licence. Comme d'autres modèles de la suite Hunyuan de Tencent, l'utilisation de Voyager est interdite dans l'Union européenne, au Royaume-Uni et en Corée du Sud. L'entreprise exige également des accords supplémentaires pour les déploiements commerciaux desservant plus de 100 millions d'utilisateurs actifs mensuels.

La qualité de sortie représente un progrès considérable pour les environnements générés par l'IA. Cependant, les coûts de calcul élevés et les limitations actuelles en matière de cohérence des scènes signifient qu'il faudra peut-être un certain temps avant que des systèmes comme Voyager puissent prendre en charge des expériences entièrement interactives en temps réel. Pour l'instant, ce système est probablement plus utile pour la création vidéo et les workflows de reconstruction 3D expérimentale.
Source : https://khoahocdoisong.vn/mo-hinh-ai-bien-mot-buc-anh-duy-nhat-thanh-the-gioi-3d-post2149050727.html




![[Photo] Le Politburo travaille avec les comités permanents des comités provinciaux du Parti de Dong Thap et de Quang Tri](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/8/3e1c690a190746faa2d4651ac6ddd01a)
![[Photo] Le Politburo travaille avec les comités permanents des comités provinciaux du Parti de Vinh Long et de Thai Nguyen](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/8/4f046c454726499e830b662497ea1893)



![[INFOGRAPHIE] Écouteurs intelligents Samsung Galaxy Buds3 FE, autonomie de 30 heures](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/9/8/fa1a0e331dfc46e0830091378c32dc6c)













![[Photo] Éclipse lunaire totale incroyable dans de nombreux endroits du monde](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/8/7f695f794f1849639ff82b64909a6e3d)

































































Comment (0)