

GPU's zijn het brein van AI-computers.
Simpel gezegd fungeert de grafische processor (GPU) als het brein van een AI-computer.
Zoals u wellicht al weet, is de centrale verwerkingseenheid (CPU) het brein van een computer. Het voordeel van een GPU is dat het een gespecialiseerde CPU is voor het uitvoeren van complexe berekeningen. De snelste manier om deze berekeningen uit te voeren, is door groepen GPU's samen een probleem te laten oplossen. Desondanks kan het trainen van een AI-model nog steeds weken of zelfs maanden duren. Zodra het model is gebouwd, wordt het in het front-end computersysteem geplaatst en kunnen gebruikers vragen stellen aan het AI-model; dit proces wordt inferentie genoemd.
Een AI-computer bevat meerdere GPU's.
De beste architectuur voor het oplossen van AI-problemen is het gebruik van een groep GPU's in een rack, aangesloten op een switch bovenop het rack. Meerdere GPU-racks kunnen bovendien worden verbonden in een hiërarchisch netwerkconnectiviteitssysteem. Naarmate de op te lossen problemen complexer worden, nemen ook de GPU-vereisten toe, waarbij sommige projecten mogelijk clusters van duizenden GPU's nodig hebben.
Elk AI-cluster is een klein netwerk.
Bij het bouwen van een AI-cluster is het nodig om een klein computernetwerk op te zetten om de GPU's met elkaar te verbinden, zodat ze efficiënt kunnen samenwerken en gegevens kunnen delen.
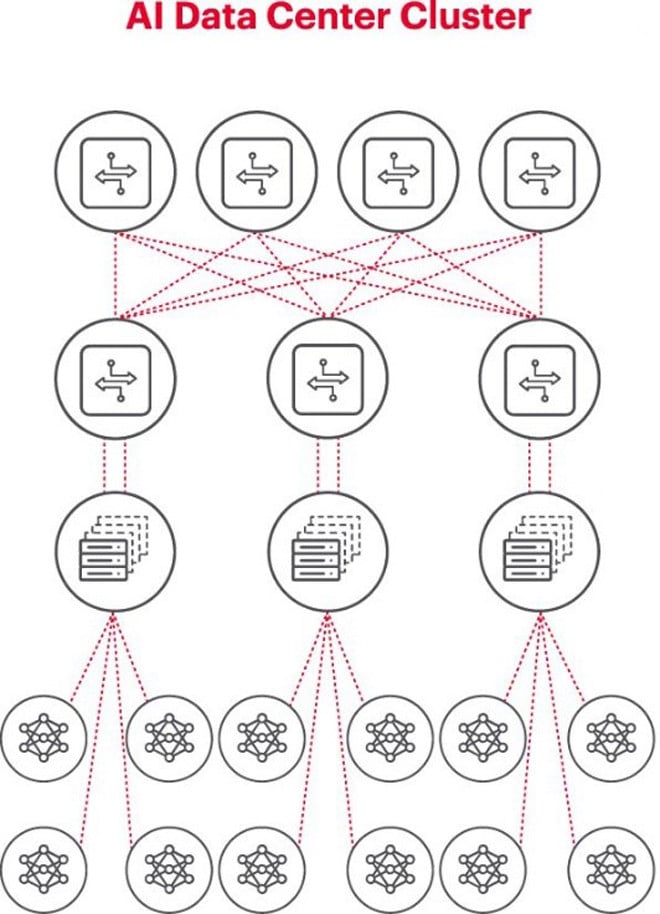
Het bovenstaande diagram illustreert een AI-cluster, waarbij de cirkels onderaan workflows voorstellen die op GPU's draaien. GPU's zijn verbonden met switches in het bovenste rack (ToR). Deze ToR-switches zijn ook verbonden met de switches in het netwerkbackbone, zoals weergegeven in het diagram hierboven. Dit toont de duidelijke netwerkhiërarchie die nodig is wanneer meerdere GPU's betrokken zijn.



Netwerken vormen een knelpunt bij de implementatie van AI.
Afgelopen najaar, tijdens de wereldwijde top van het Open Computer Project (OCP), waar deelnemers de volgende generatie AI-infrastructuur ontwikkelden, wees afgevaardigde Loi Nguyen van Marvell Technology op een belangrijk probleem: "netwerken vormen het nieuwe knelpunt."
Technisch gezien kan een hoge pakketlatentie of pakketverlies als gevolg van netwerkcongestie ertoe leiden dat pakketten opnieuw verzonden moeten worden, waardoor de voltooiingstijd van taken (JCT) aanzienlijk toeneemt. Hierdoor gaan GPU's ter waarde van miljoenen of zelfs tientallen miljoenen dollars van bedrijven verloren door inefficiënte AI-systemen, wat bedrijven schaadt op het gebied van omzet en time-to-market.
Testen en meten zijn cruciale voorwaarden voor het succesvol functioneren van AI-netwerken.
Om een AI-cluster efficiënt te laten werken, moeten GPU's hun volledige capaciteit kunnen benutten om de trainingstijd te verkorten en leermodellen te implementeren om het rendement op de investering te maximaliseren. Daarom is het testen en evalueren van de prestaties van het AI-cluster noodzakelijk (Figuur 2). Deze taak is echter niet eenvoudig, aangezien de systeemarchitectuur veel instellingen en relaties tussen de GPU en de netwerkstructuur omvat die elkaar moeten aanvullen om het probleem op te lossen.
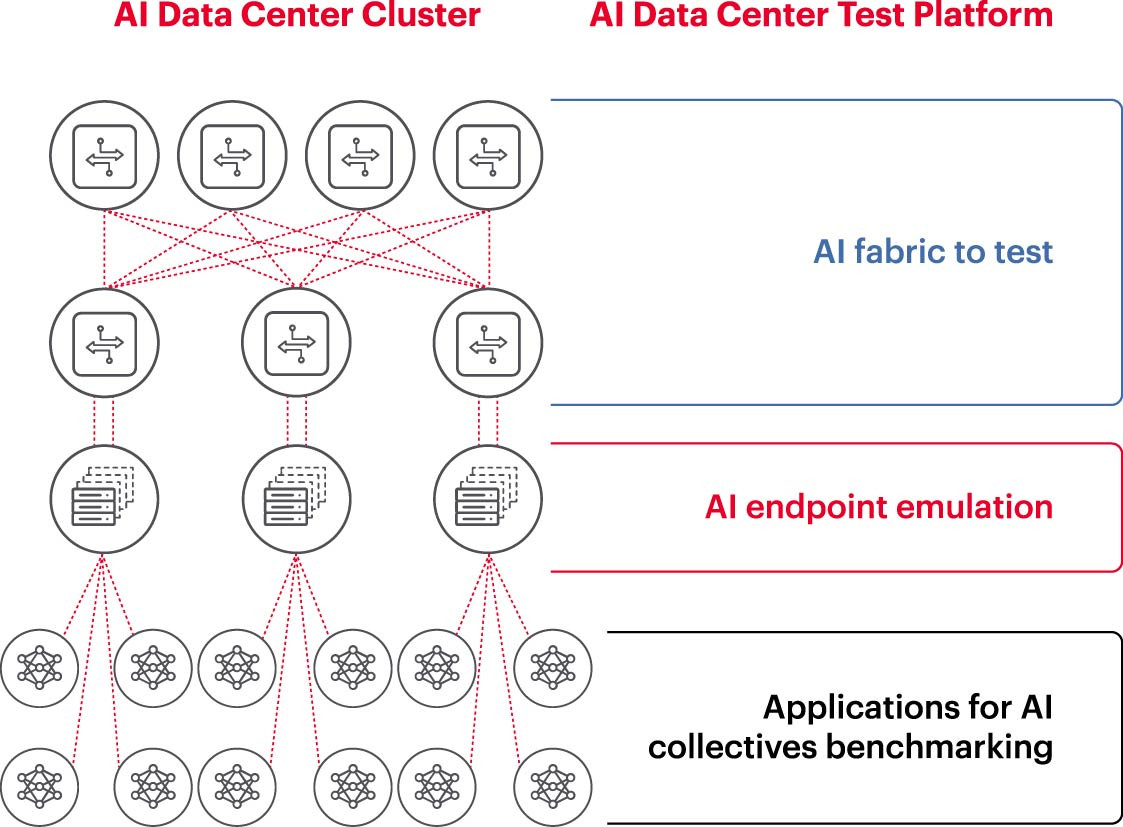
Dit leidt tot veel moeilijkheden en uitdagingen bij het meten van AI-netwerken:
De uitdaging bij het repliceren van het volledige productienetwerk in het laboratorium ligt in beperkingen op het gebied van kosten, apparatuur, een tekort aan hooggekwalificeerde AI-netwerkengineers, ruimte, stroomvoorziening en temperatuur.
- Testen op locatie in een productiesysteem vermindert de beschikbare verwerkingscapaciteit van het productiesysteem zelf.
- Moeilijkheden bij het nauwkeurig reproduceren van problemen vanwege verschillen in de omvang en reikwijdte van de problemen.



- De complexiteit van de manier waarop GPU's gezamenlijk verbinding maken.
Om deze uitdagingen aan te pakken, kunnen bedrijven een subset van voorgestelde configuraties in een laboratoriumomgeving benchmarken om belangrijke parameters zoals JCT (job completion time), de bandbreedte die het AI-team kan bereiken, te meten en te vergelijken met het gebruik van het switchingplatform en de cache. Deze benchmark helpt bij het vinden van de juiste balans tussen GPU-/processingbelasting en netwerkontwerp/installatie. Zodra de resultaten bevredigend zijn, kunnen de computerarchitecten en netwerkengineers deze configuraties in productie nemen en de nieuwe resultaten meten.
Bedrijfsonderzoekslaboratoria, onderzoeksinstituten en universiteiten werken aan de analyse van elk aspect van het bouwen en beheren van effectieve AI-netwerken om de uitdagingen van het werken met grote netwerken aan te pakken, vooral omdat best practices voortdurend veranderen. Deze herhaalbare, collaboratieve aanpak is de enige manier voor bedrijven om herhaalbare metingen uit te voeren en snel 'als-dan'-scenario's te testen – essentieel voor het optimaliseren van AI-gestuurde netwerken.
(Bron: Keysight Technologies)
Bron: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html





















































































































