
Brukerens livstidsverdi (LTV) er en viktig målestokk for å måle effektiviteten av en apps inntekter. Nøyaktig måling av LTV krever mye menneskelige og materielle ressurser ... og takket være utviklingen av AI blir denne prosessen enklere.

Anton Ogay, produkteier for appkampanjer hos Yandex Ads – et av de ledende globale annonsenettverkene, snakker om potensialet til livstidsverdi (LTV):

PV: Hvilken rolle spiller livstidsverdi (LTV) for å hjelpe apputviklere med å konkurrere globalt?
Mr. Anton Ogay: LTV-data lar utviklere optimalisere inntektsstrømmer som kjøp i appen og annonser i appen ved å bestemme verdien brukerne kan tilføre og kostnaden ved å skaffe brukere. Dermed bidrar LTV til å bestemme verdien brukerne skaper for appen, slik at utviklere kan fokusere på brukerbasen og skape den høyeste verdien for å optimalisere appsalget ved å foreslå effektive markedsføringsaktiviteter rettet mot den ønskede brukerbasen. LTV går utover overfladiske beregninger som appnedlastinger, tid brukt på appen ... og gir detaljert informasjon om global brukeratferd og preferanser, og er grunnlaget for at utviklere skal kunne lansere effektive kampanjer for langsiktig suksess.
Hvordan måle LTV? Hvilke vanskeligheter har mobilspillutgivere, etter din observasjon, møtt når appene deres ikke måler LTV?
LTV innebærer å se på en rekke faktorer som gjennomsnittlig salg, kjøpsfrekvens, profittmarginer og kundelojalitet for å bestemme den totale inntekten som genereres av en kunde over tid. Som et resultat står utviklere overfor utfordringer med å håndtere store mengder data som kan være unøyaktige eller ufullstendige, noe som hindrer nøyaktig innsikt i brukeratferd og inntektsgenerering. For best mulig måling vil spillutviklere trenge en stor mengde brukerdata, men dette kan være utfordrende for utviklere, spesielt små og mellomstore utviklere, som ikke har råd til det. Dette øker presset på apputviklere. Videre, med fremveksten av AI, blir LTV-måling mer nøyaktig, noe som hjelper utviklere med å få en dypere forståelse av brukeratferd slik at de kan optimalisere markedsføringsstrategiene sine effektivt.
Så hvordan kan man bruke AI til å måle LTV?
AI-drevne modeller kan analysere data fra en rekke kilder, som appbruk, brukeratferd og markedstrender, for å forutsi fremtidig LTV for individuelle brukere eller grupper. Disse modellene kan identifisere fremtidige trender som kanskje ikke er umiddelbart åpenbare for mennesker, og gir mer nøyaktig og omfattende innsikt i brukerverdi. For eksempel har vi på AppMetrica-appanalyseplattformen innlemmet en prediktiv LTV-modell bygget på Yandex Ads' maskinlæringsteknologi ved hjelp av anonymiserte data fra titusenvis av apper på tvers av flere kategorier. Dette lar appteam lage nøyaktige monetiseringsforutsigelser selv uten data fra selve appen. Så innen 24 timer etter at appen er installert, analyserer modellen flere LTV-relaterte beregninger og grupperer brukere basert på deres evne til å tjene penger på appen, og deler dem inn i de 5 % beste brukerne med høyest LTV, helt opp til de 20 % eller 50 % beste brukerne med høyest LTV.
Har du noen eksempler på vellykkede AI-applikasjoner for måling og prognoser av LTV?
Som jeg nevnte tidligere, har små utviklere ofte problemer med å få tilgang til de nødvendige datakildene for å beregne og forutsi LTV. For å løse dette problemet automatiserte vi prosessen og hentet data fra Yandex Direct, Yandex sin egen plattform for annonsører. Yandex Direct har en enorm database med titusenvis av apper og hundrevis av millioner brukere. Disse modellene lar annonsører markedsføre mobilapper for å få flere konverteringer etter installasjon og høyere inntekter, spesielt i betal-per-installasjonskampanjer. Når dataene er samlet inn fra Yandex Direct, begynner AppMetricas algoritme å beregne en poengsum for å forutsi brukerens LTV. Vi brukte denne poengsummen til å trene modellene våre og innlemme sannsynligheten for målhandlinger etter installasjon i prediksjonen. Basert på denne poengsummen justerer systemet automatisk annonseringsstrategien.
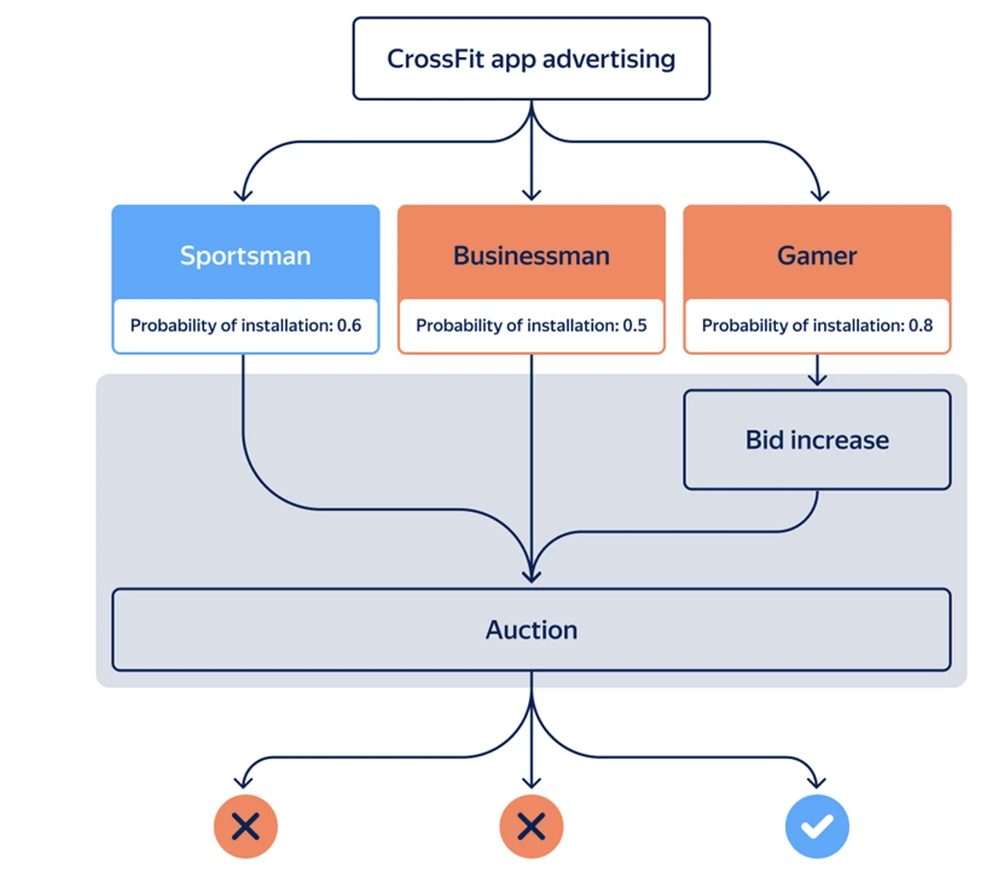
Ved å samle data lærer og tilpasser modellen seg individets oppførsel i en gitt applikasjon, noe som øker nøyaktigheten til prediksjonene til 99 %. Påliteligheten til disse prediksjonene kommer fra den enorme og mangfoldige mengden anonymiserte data vi analyserer, slik at vi kan identifisere mønstre og trender som kanskje ikke er umiddelbart åpenbare for mennesker. Disse dataene brukes til å bygge prediktive modeller som gir nøyaktig og omfattende innsikt i brukerverdi.
BINH LAM
[annonse_2]
Kilde

![[Foto] Handling for fellesskapet forteller historier om varige reiser – både intime og store, men likevel stille og besluttsomme](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/15/1763179022035_ai-dai-dieu-5828-jpg.webp)













































































































Kommentar (0)