
I samband med digital transformation och artificiell intelligens (AI) i Vietnam spelar OCR-teknik (optisk teckenigenkänning) en allt viktigare roll för att digitalisera dokument, automatisera affärsprocesser, spara kostnader och förbättra ledningseffektiviteten. Men med vietnamesiskan som kännetecknar accenter och handstil stannar inte igenkänningsproblemet vid att "läsa ord", utan kräver att modellen har förmågan att förstå sammanhanget på ett heltäckande sätt.
Nyligen tillkännagav CMC Technology Application Institute (CMC ATI) CATI-VLM-modellen (Visual Document Understanding), som utvecklats av forskarteamet från ett stort datalager på 5 TB. Modellen nådde topp 12 i världen och topp 1 i Vietnam i rankingen som just tillkännagavs av Robust Reading Competition (RRC) i juni 2025 i kategorin Document Visual Question Answering (DocVQA).
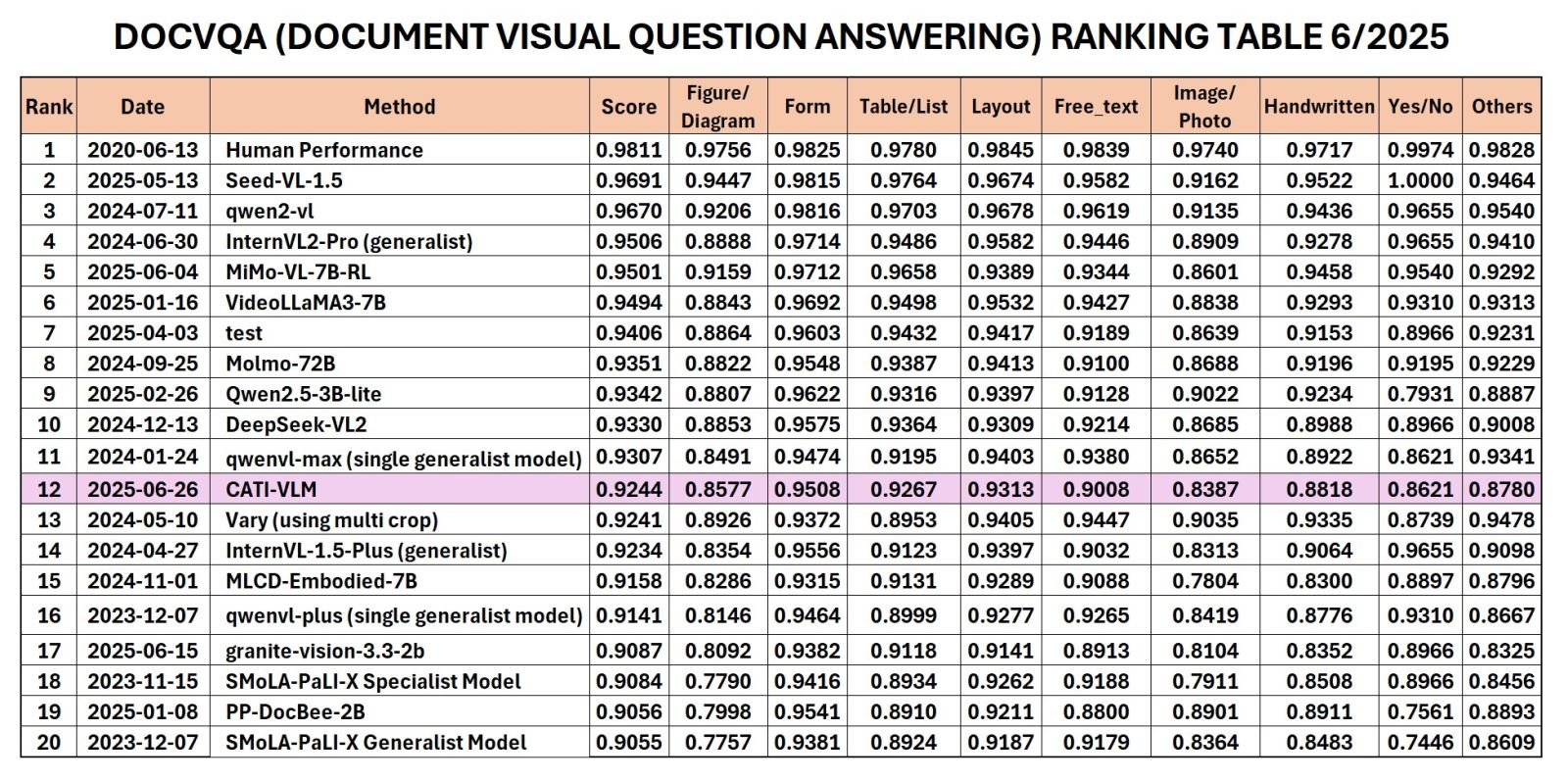
RRC-rankning i DocVQA-kategori 6/2025.
Robust Reading Competition (RRC) är en prestigefylld vetenskaplig lekplats (https://rrc.cvc.uab.es/) som organiseras av Computer Vision Center (CVC) vid Universitat Autònoma de Barcelona (UAB) i Spanien, en prestigefylld forskningsanläggning i världen inom datorseende. Tävlingen inleddes 2011 och äger alltid rum i samband med den internationella konferensen om textanalys och -igenkänning (ICDAR) – ett av världens största forum för dokumentanalys och datorseende. Tävlingen har blivit ett viktigt evenemang som lockar forskare, ingenjörer från prestigefyllda universitet, forskningsinstitut och teknikföretag som Tsinghua University, Hyundai Motor Group och Tencent... RRC:s uppgifter är utformade för att främja tekniska framsteg, nära kopplade till praktiska problem från översättning, företagsdatahantering till urban analys och historisk dokumentbehandling.
Dr. Dang Minh Tuan, chef för CMC ATI, delade: ”CMC-teamets forskningskapacitet bekräftas genom en prestigefylld global spelplats som RRC. Vi är stolta över att teamet på kort tid kan uppnå en hög ranking och stå sida vid sida med stora namn från utvecklade länder. Ännu viktigare är att detta är en tydlig demonstration av förmågan att bemästra teknik för att lösa specifika problem för vietnamesiska och specialiserade områden i Vietnam.”
CATI-VLM skiljer sig från traditionell OCR genom att den inte bara extraherar tecken, utan också förstår flera lager av information: textinnehåll, icke-textelement (kryssrutor, kryssrutor, diagram, signaturer, formler), layout (sidstruktur, tabeller, formulär) och stil (teckensnitt, markeringar etc.). Modellen kan svara på visuella frågor som ställs på dokumentbilder, liknande ChatGPT, utan att behöva lära sig specifika formulär i förväg.
Enligt tidningen News and People
Källa: https://doanhnghiepvn.vn/cong-nghe/ai-loi-make-in-vietnam-duoc-xep-hang-top-12-the-gioi/20250703100726051




![[Foto] Den 5:e patriotiska emuleringskongressen för den centrala inspektionskommissionen](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/27/1761566862838_ndo_br_1-1858-jpg.webp)































![[Foto] Partikommittéerna i de centrala partiorganen sammanfattar genomförandet av resolution nr 18-NQ/TW och partikongressens inriktning.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/27/1761545645968_ndo_br_1-jpg.webp)
![[Foto] Nationalförsamlingens ordförande Tran Thanh Man tar emot Uzbekistans representanthus ordförande Nuriddin Ismoilov](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/27/1761542647910_bnd-2610-jpg.webp)































![[Foto] Premiärministern deltar i det 28:e toppmötet mellan ASEAN och Kina](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/10/28/1761624895025_image-2.jpeg)








































Kommentar (0)