
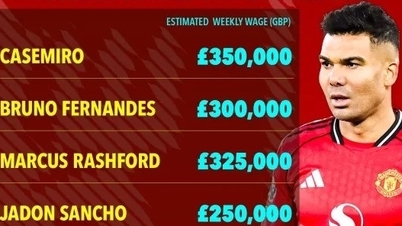
Відповідно, навіть найефективніша конфігурація моделі штучного інтелекту, яку вони протестували, GPT-4-Turbo від OpenAI, все одно досягла лише 79% правильних відповідей, незважаючи на прочитання всього профілю та часті «галюцинації» нереальних цифр чи подій.
«Такий рівень продуктивності абсолютно неприйнятний», — сказав Ананд Каннаппан, співзасновник Patronus AI. «Частота правильних відповідей має бути набагато вищою, щоб бути автоматизованою та готовою до використання».
Отримані результати підкреслюють деякі проблеми, з якими стикаються моделі штучного інтелекту, оскільки великі компанії, особливо у жорстко регульованих галузях, таких як фінанси, прагнуть впроваджувати передові технології у свою діяльність, чи то в обслуговуванні клієнтів, чи в дослідженнях.
«Ілюзія» фінансових даних
Здатність швидко витягувати ключові цифри та виконувати аналіз фінансової звітності вважається одним із найперспективніших застосувань для чат-ботів з моменту випуску ChatGPT наприкінці минулого року.
Звіти SEC містять важливі дані, і якщо бот може точно узагальнити або швидко відповісти на запитання щодо їхнього змісту, це може дати користувачам перевагу в конкурентній фінансовій галузі.

Протягом минулого року Bloomberg LP розробила власну модель штучного інтелекту для фінансових даних, а професори бізнес-шкіл вивчали, чи може ChatGPT аналізувати фінансові заголовки.
Тим часом JPMorgan також розробляє автоматизований інвестиційний інструмент на базі штучного інтелекту. Нещодавній прогноз McKinsey свідчить, що генеративний штучний інтелект може збільшити банківську галузь на трильйон доларів на рік.
Але ще багато чого попереду. Коли Microsoft вперше запустила Bing Chat з GPT від OpenAI, вона використовувала чат-бота для швидкого підсумовування прес-релізів про прибутки. Спостерігачі швидко помітили, що цифри, які видавав штучний інтелект, були спотвореними або навіть сфабрикованими.
Ті самі дані, різні відповіді
Частина проблеми впровадження LLM у реальні продукти полягає в тому, що алгоритми не є детермінованими, тобто немає гарантії, що вони дають однакові результати за однакових вхідних даних. Це означає, що компаніям потрібно проводити більш ретельне тестування, щоб переконатися, що ШІ працює правильно, не відхиляється від теми та надає надійні результати.
Штучний інтелект Patronus створив набір із понад 10 000 запитань та відповідей, взятих із документів SEC від великих публічних компаній, під назвою FinanceBench. Набір даних містить правильні відповіді, а також точне розташування в будь-якому файлі для їх пошуку.
Не всі відповіді можна взяти безпосередньо з тексту, а деякі питання вимагають розрахунків або легких міркувань.
Тест із 150 запитань включав чотири моделі LLM: GPT-4 та GPT-4-Turbo від OpenAI, Claude 2 від Anthropic та Llama 2 від Meta.
В результаті, GPT-4-Turbo, отримавши доступ до відповідних документів SEC, досягла лише 85% точності (порівняно з 88% неправильних відповідей без доступу до даних), незважаючи на те, що штучний інтелект мав вказівник миші на точний текст, щоб знайти відповідь.
Llama 2, модель штучного інтелекту з відкритим кодом, розроблена Meta, мала найбільшу кількість «галюцинацій», даючи неправильні відповіді у 70% випадків і правильні відповіді лише у 19% випадків, коли їй надавали доступ до частини відповідних документів.
Тест Claude 2 від Anthropic добре показав себе з «довгим контекстом», в який разом із питанням було включено майже всю відповідну заявку SEC. Він зміг відповісти на 75% поставлених запитань, неправильно відповівши на 21% та відмовившись відповідати на 3%. GPT-4-Turbo також добре показав себе з довгим контекстом, правильно відповівши на 79% запитань та неправильно відповівши на 17% з них.
(За даними CNBC)

Великі технологічні компанії змагаються за інвестування в стартапи зі штучним інтелектом

Технологія штучного інтелекту революціонізує стартапи електронної комерції

Штучний інтелект вперше успішно перетворює людські думки на реалістичні зображення
Джерело

![[Фото] Прем'єр-міністр Фам Мінь Чінь головує на 15-му засіданні Центральної ради з питань конкуренції та винагороди](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F27%2F1764245150205_dsc-1922-jpg.webp&w=3840&q=75)
![[Фото] Президент Луонг Куонг відвідав церемонію відзначення 50-ї річниці Національного дня Лаосу](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F27%2F1764225638930_ndo_br_1-jpg.webp&w=3840&q=75)
































































































Коментар (0)