
أعلن الباحثون في DeepSeek عن نموذج تجريبي جديد يسمى V3.2-exp، والذي تم تصميمه لتقليل تكلفة الاستدلال بشكل كبير عند استخدامه في العمليات ذات السياق الطويل.
أعلنت شركة DeepSeek عن النموذج في منشور على Hugging Face، ونشرت أيضًا ورقة أكاديمية مرتبطة على GitHub.
الميزة الأهم في النموذج الجديد والمعقد هي DeepSeek Sparse Attention. يستخدم النظام وحدةً تُسمى "مفهرس البرق" لتحديد أولوية مقتطفات محددة من نافذة السياق.

أعلنت شركة DeepSeek عن نموذج استدلال فعال من حيث التكلفة.
ثم يقوم نظام منفصل يُسمى "نظام اختيار الرموز الدقيقة" باختيار رموز محددة من تلك المقاطع لتحميلها في نافذة الانتباه المحدودة للوحدة. وبدمجها، تتيح هذه العناصر لنماذج الانتباه المتناثر العمل على أجزاء طويلة من السياق مع حمل خادم صغير نسبيًا.
بالنسبة للعمليات طويلة الأمد، تُعدّ فوائد النظام كبيرة. تُظهر الاختبارات الأولية لـ DeepSeek إمكانية خفض تكلفة استدعاء دالة الاستدلال البسيطة (API) بما يصل إلى النصف في سيناريوهات طويلة الأمد.
هناك حاجة إلى مزيد من الاختبارات لبناء تقييم أكثر قوة، ولكن بما أن النموذج مفتوح ومتاح مجانًا على Hugging Face، فلن يمر وقت طويل قبل أن تتمكن اختبارات الطرف الثالث من تقييم الادعاءات الواردة في الورقة.

على عكس نماذج Chatbots الأخرى التي تستهلك قدرًا كبيرًا من الطاقة، فإن DeepSeek يتجه نحو توفير التكاليف من التدريب إلى التشغيل.
ويعد نموذج DeepSeek الجديد واحدًا من سلسلة من الاختراقات الحديثة التي تعالج مشكلة تكلفة الاستدلال - في الأساس، تكلفة الخادم لتشغيل نموذج الذكاء الاصطناعي المدرب مسبقًا، بدلاً من تكلفة تدريبه.
وفي حالة DeepSeek، كان الباحثون يبحثون عن طرق لجعل بنية المحول الأساسية أكثر كفاءة، ووجدوا أن هناك حاجة إلى إجراء تحسينات كبيرة.
شركة DeepSeek، ومقرها الصين، تُعدّ شخصيةً استثنائيةً في عالم الذكاء الاصطناعي، خاصةً لمن يعتبرون أبحاث الذكاء الاصطناعي منافسةً بين الولايات المتحدة والصين. وقد حققت الشركة نجاحًا باهرًا في وقتٍ سابق من هذا العام بنموذجها R1، المُدرّب أساسًا باستخدام التعلم المُعزّز بتكلفةٍ أقل بكثير من منافسيها الأمريكيين.
ومع ذلك، فشل النموذج في إحداث ثورة كاملة النطاق في تدريب الذكاء الاصطناعي كما توقع البعض، وتراجعت الشركة ببطء عن دائرة الضوء في الأشهر التي تلت ذلك.
من غير المرجح أن يسبب نهج "الاهتمام المتناثر" الجديد نفس القدر من الغضب مثل R1 - لكنه لا يزال يمكن أن يعلم مقدمي الخدمات في الولايات المتحدة بعض الحيل الضرورية للغاية للمساعدة في الحفاظ على انخفاض تكاليف الاستدلال.
https://techcrunch.com/2025/09/29/deepseek-releases-sparse-attention-model-that-cuts-api-costs-in-half/
المصدر: https://khoahocdoisong.vn/deepseek-dao-tao-da-re-nay-con-co-ban-suy-luan-re-hon-post2149057353.html



![[صورة] طلاب مدرسة بينه مينه الابتدائية يستمتعون بمهرجان اكتمال القمر، ويتلقون أفراح الطفولة](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/3/8cf8abef22fe4471be400a818912cb85)

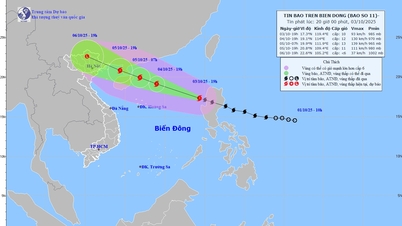
![[صورة] رئيس الوزراء فام مينه تشينه يرأس اجتماعًا للتغلب على عواقب العاصفة رقم 10](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/3/544f420dcc844463898fcbef46247d16)
























































































تعليق (0)