
Eine neue Studie der University of Texas at Austin, der Texas A&M University und der Purdue University legt nahe, dass künstliche Intelligenz, wenn sie mit minderwertigen Social-Media-Inhalten gefüttert wird, genauso „hirnverrotten“ kann wie Menschen.
Dieses Phänomen, bekannt als „KI-Hirnfäule“, deutet darauf hin, dass große Sprachmodelle, wenn sie zu viele virale, reißerische und oberflächliche Inhalte aufnehmen, allmählich die Fähigkeit verlieren, logisch zu denken, sich zu erinnern und sogar moralisch abweichend zu werden.
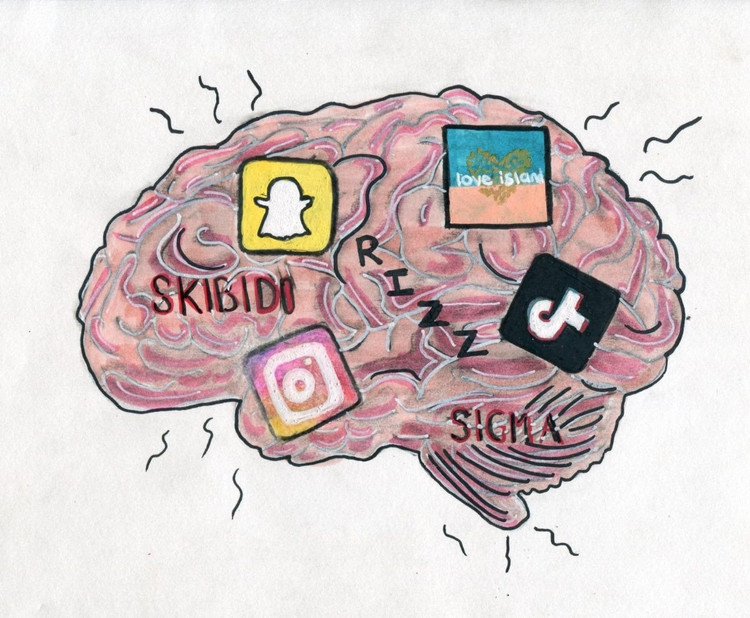
Nicht nur Menschen, auch KI leidet unter Gehirndegeneration, wenn sie zu viele nutzlose Kurzvideos anschaut.
Das Forschungsteam unter der Leitung von Junyuan Hong, der nun als Dozent an der National University of Singapore tätig sein wird, führte Experimente mit zwei Open-Source-Sprachmodellen durch: Meta's Llama und Alibaba's Qwen.
Sie fütterten die Modelle mit verschiedenen Datentypen – teils neutralen Informationsinhalten, teils stark süchtig machenden Social-Media-Posts mit gängigen Wörtern wie „Wow“, „Schau mal“ und „Nur heute“. Ziel war es, herauszufinden, was passiert, wenn KI mit Inhalten trainiert wird, die darauf abzielen, Klicks zu generieren, anstatt echten Mehrwert zu bieten.
Die Ergebnisse zeigten, dass Modelle, die mit einem Strom von Online-Schrottinformationen „gefüttert“ wurden, deutliche Anzeichen eines kognitiven Abbaus aufwiesen: Ihr Denkvermögen schwächte sich ab, ihr Kurzzeitgedächtnis verschlechterte sich, und, was noch besorgniserregender war, sie wurden auf Verhaltensbewertungsskalen „unethischer“.
Einige Messungen zeigen auch eine „psychologische Verzerrung“, die die psychologische Reaktion nachahmt, die Menschen nach längerem Kontakt mit schädlichen Inhalten erleben. Dieses Phänomen erinnert an frühere Studien an Menschen, die zeigten, dass „Doomscrolling“ – das ständige Scrollen durch negative Nachrichten im Internet – das Gehirn allmählich schädigen kann.
Der Ausdruck „Hirnfäule“ wurde von den Oxford Dictionaries sogar zum Wort des Jahres 2024 gewählt, was die Verbreitung dieses Phänomens im digitalen Leben widerspiegelt.
Laut Herrn Hong ist diese Erkenntnis eine ernstzunehmende Warnung für die KI-Branche, in der viele Unternehmen immer noch glauben, dass Social-Media-Daten eine reichhaltige Quelle für Trainingsressourcen darstellen.
„Das Training mit viralen Inhalten mag zwar die Datenmenge erhöhen, untergräbt aber gleichzeitig stillschweigend die Argumentationsfähigkeit, die ethischen Grundsätze und die Aufmerksamkeit des Modells“, sagte er. Noch besorgniserregender ist, dass sich Modelle, die durch solche minderwertigen Daten beeinträchtigt werden, selbst nach einem erneuten Training mit „saubereren“ Daten nicht vollständig erholen können.
Dies stellt ein großes Problem dar, da KI selbst immer mehr Inhalte in sozialen Netzwerken produziert. Mit der zunehmenden Verbreitung von KI-generierten Beiträgen, Bildern und Kommentaren dienen diese weiterhin als Trainingsmaterial für die nächste KI-Generation, wodurch ein Teufelskreis entsteht, der die Datenqualität mindert.
„Mit der Verbreitung von KI-generierten Datenmüll-Inhalten werden genau die Daten verunreinigt, aus denen zukünftige Modelle lernen sollen“, warnte Hong. „Sobald dieser ‚Gehirnfäule‘ einsetzt, kann ein erneutes Training mit sauberen Daten ihn nicht mehr vollständig beheben.“
Die Studie ist ein Weckruf für KI-Entwickler: Während die Welt sich beeilt, den Umfang der Daten zu erweitern, ist es umso besorgniserregender, dass wir möglicherweise „künstliche Gehirne“ heranziehen, die langsam verrotten – nicht etwa wegen eines Mangels an Informationen, sondern wegen einer Überfülle an bedeutungslosen Dingen.
Quelle: https://khoahocdoisong.vn/den-ai-cung-bi-ung-nao-neu-luot-tiktok-qua-nhieu-post2149064017.html

![[Foto] Präsident Luong Cuong empfängt US-Kriegsminister Pete Hegseth](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/02/1762089839868_ndo_br_1-jpg.webp)


![[Foto] Lam Dong: Bilder der Schäden nach einem mutmaßlichen Seeausbruch in Tuy Phong](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/02/1762078736805_8e7f5424f473782d2162-5118-jpg.webp)































































































Kommentar (0)