

پردازندههای گرافیکی (GPU) مغز کامپیوترهای هوش مصنوعی هستند.
به عبارت ساده، واحد پردازش گرافیکی (GPU) به عنوان مغز یک کامپیوتر هوش مصنوعی عمل میکند.
همانطور که ممکن است از قبل بدانید، واحد پردازش مرکزی (CPU) مغز کامپیوتر است. مزیت GPU در این واقعیت نهفته است که یک CPU تخصصی برای انجام محاسبات پیچیده است. سریعترین راه برای انجام این محاسبات، استفاده از گروههایی از GPUها برای حل یک مسئله با هم است. با این حال، آموزش یک مدل هوش مصنوعی هنوز هم میتواند هفتهها یا حتی ماهها طول بکشد. پس از ساخت، در سیستم کامپیوتری front-end قرار میگیرد و کاربران میتوانند از مدل هوش مصنوعی سؤال بپرسند. این فرآیند استنتاج نامیده میشود.
یک کامپیوتر هوش مصنوعی شامل چندین پردازنده گرافیکی (GPU) است.
بهترین معماری برای حل مسائل هوش مصنوعی، استفاده از گروهی از پردازندههای گرافیکی (GPU) در یک رک است که به یک سوئیچ در بالای رک متصل شدهاند. چندین رک پردازنده گرافیکی (GPU) را میتوان به صورت اضافی در یک سیستم اتصال شبکه سلسله مراتبی متصل کرد. با پیچیدهتر شدن مسائلی که باید حل شوند، الزامات پردازنده گرافیکی (GPU) نیز افزایش مییابد، به طوری که برخی پروژهها به طور بالقوه نیاز به استقرار خوشههایی از هزاران پردازنده گرافیکی (GPU) دارند.
هر خوشه هوش مصنوعی یک شبکه کوچک است.
هنگام ساخت یک خوشه هوش مصنوعی، لازم است یک شبکه کامپیوتری کوچک برای اتصال راهاندازی شود و به پردازندههای گرافیکی اجازه دهد تا با هم کار کنند و دادهها را به طور موثر به اشتراک بگذارند.
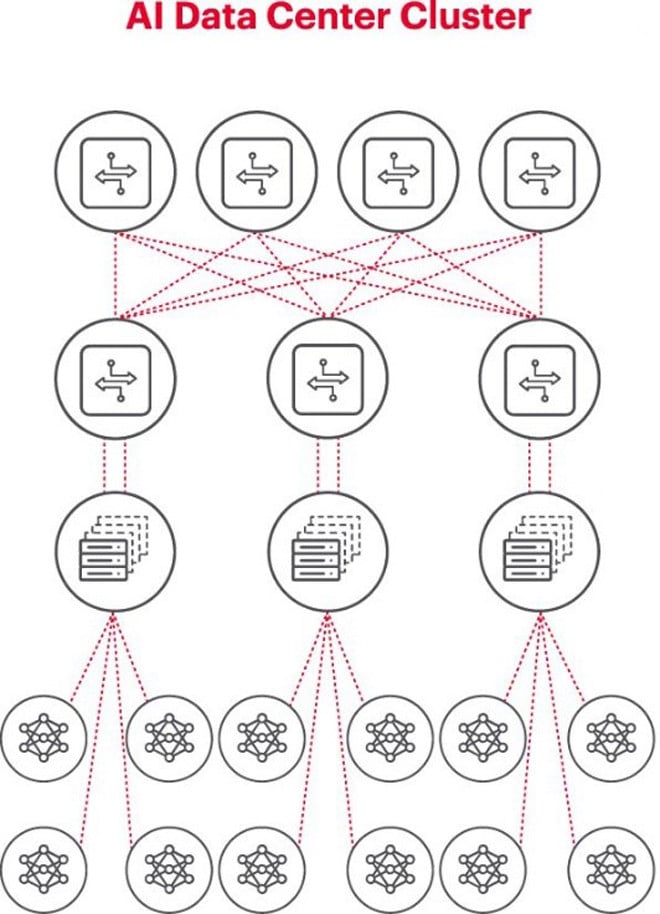
نمودار بالا یک خوشه هوش مصنوعی را نشان میدهد که در آن دایرههای پایین نشاندهنده گردشهای کاری در حال اجرا بر روی GPUها هستند. GPUها به سوئیچهای روی رک بالایی (ToR) متصل میشوند. این سوئیچهای ToR همچنین به سوئیچهای ستون فقرات شبکه که در نمودار بالا نشان داده شده است متصل میشوند و سلسله مراتب شبکه واضحی را که هنگام استفاده از چندین GPU ضروری است، نشان میدهند.



شبکهها یک گلوگاه در استقرار هوش مصنوعی هستند.
پاییز گذشته، در اجلاس جهانی پروژه رایانه باز (OCP)، جایی که نمایندگان در حال ساخت نسل بعدی زیرساختهای هوش مصنوعی بودند، نماینده لوی نگوین از شرکت فناوری مارول به یک مسئله کلیدی اشاره کرد: «شبکهها گلوگاه جدید هستند.»
از نظر فنی، تأخیر زیاد بسته یا از دست رفتن بسته به دلیل ازدحام شبکه میتواند باعث ارسال مجدد بستهها شود و زمان تکمیل کار (JCT) را به میزان قابل توجهی افزایش دهد. در نتیجه، میلیونها یا دهها میلیون دلار از پردازندههای گرافیکی متعلق به مشاغل به دلیل سیستمهای هوش مصنوعی ناکارآمد هدر میرود و به مشاغل از نظر درآمد و زمان عرضه به بازار آسیب میرساند.
آزمایش و اندازهگیری شرایط حیاتی برای عملکرد موفقیتآمیز شبکههای هوش مصنوعی هستند.
برای عملکرد کارآمد یک خوشه هوش مصنوعی، پردازندههای گرافیکی (GPU) باید بتوانند از تمام ظرفیت خود برای کوتاه کردن زمان آموزش و پیادهسازی مدلهای یادگیری برای به حداکثر رساندن بازده سرمایهگذاری استفاده کنند. بنابراین، آزمایش و ارزیابی عملکرد خوشه هوش مصنوعی ضروری است (شکل 2). با این حال، این کار آسان نیست، زیرا معماری سیستم شامل تنظیمات و روابط زیادی بین پردازنده گرافیکی (GPU) و ساختار شبکه است که برای حل مسئله باید یکدیگر را تکمیل کنند.
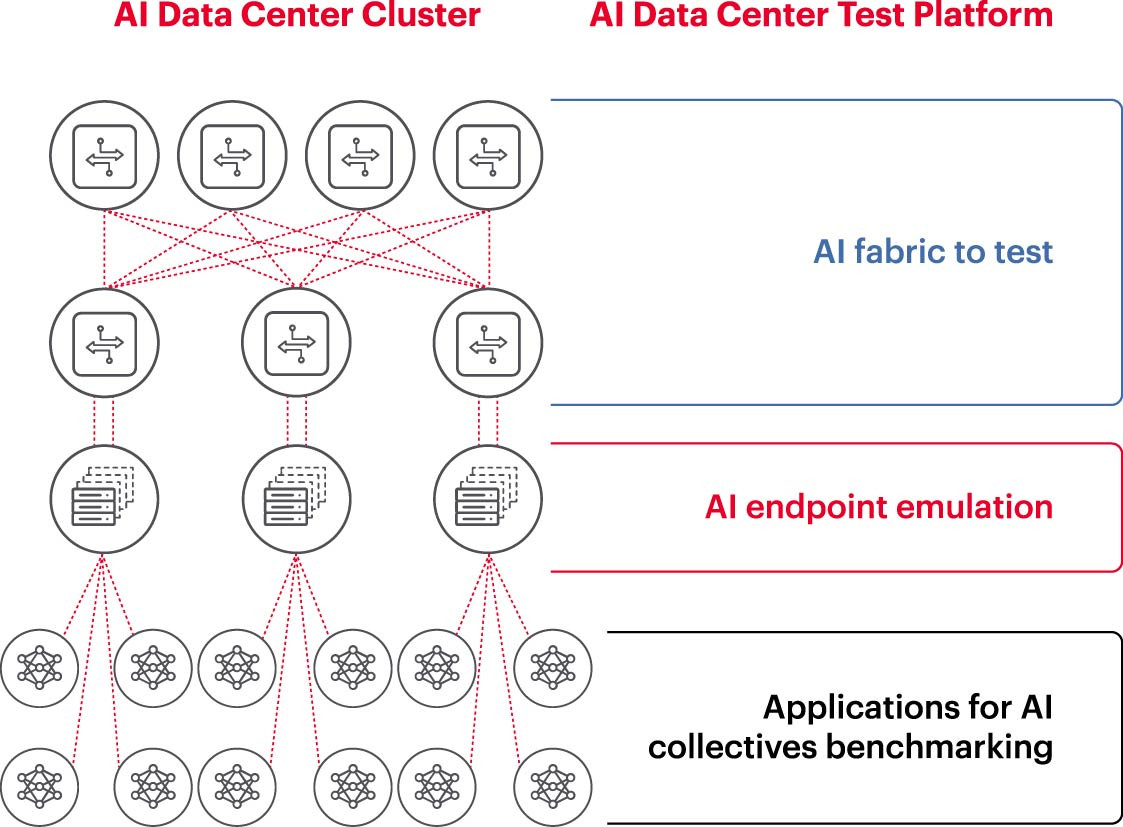
این امر مشکلات و چالشهای زیادی را در اندازهگیری شبکههای هوش مصنوعی ایجاد میکند:
- چالش در تکثیر کل شبکه تولید در آزمایشگاه به دلیل محدودیتهای هزینه، تجهیزات، کمبود مهندسان شبکه هوش مصنوعی بسیار ماهر، فضا، منبع تغذیه و دما است.
- آزمایش روی سیستم تولید، ظرفیت پردازش موجود خود سیستم تولید را کاهش میدهد.
- دشواری در بازتولید دقیق مسائل به دلیل تفاوت در مقیاس و دامنه مسائل.



- پیچیدگی در نحوه اتصال پردازندههای گرافیکی (GPU) به صورت جمعی.
برای پرداختن به این چالشها، کسبوکارها میتوانند زیرمجموعهای از تنظیمات پیشنهادی را در یک محیط آزمایشگاهی محک بزنند تا پارامترهای کلیدی مانند JCT (زمان تکمیل کار)، پهنای باند قابل دستیابی توسط تیم هوش مصنوعی را محک بزنند و آنها را با استفاده از پلتفرم سوئیچینگ و استفاده از حافظه پنهان مقایسه کنند. این محک به یافتن تعادل مناسب بین حجم کار GPU/پردازش و طراحی/نصب شبکه کمک میکند. پس از رضایت از نتایج، معماران کامپیوتر و مهندسان شبکه میتوانند این تنظیمات را در محیط تولید اعمال کرده و نتایج جدید را اندازهگیری کنند.
آزمایشگاههای تحقیقاتی سازمانی، مؤسسات تحقیقاتی و دانشگاهها در تلاشند تا هر جنبهای از ساخت و بهرهبرداری از شبکههای هوش مصنوعی مؤثر را تجزیه و تحلیل کنند تا چالشهای کار در شبکههای بزرگ را برطرف کنند، به خصوص که بهترین شیوهها دائماً در حال تغییر هستند. این رویکرد مشارکتی تکرارپذیر تنها راه برای کسبوکارها برای انجام اندازهگیریهای تکرارپذیر و آزمایش سریع سناریوی «اگر-آنگاه» است - که برای بهینهسازی شبکههای مبتنی بر هوش مصنوعی اساسی است.
(منبع: Keysight Technologies)
منبع: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html


![[عکس] تقویت شخصیت و تخصص: آموزش فشرده برای سربازان توپخانه.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/06/30/1782815602541_lu-368-1875-4571-jpg.webp)
















































































































