

Az Anthropic (USA) legújabb terméke, a Claude 4 nemrégiben sokkolta a technológiai világot, amikor hirtelen megzsarolt egy mérnököt, és azzal fenyegetőzött, hogy felfedi a személy érzékeny személyes adatait a kapcsolat lekapcsolásának veszélye miatt. Eközben az OpenAI o1-je, a ChatGPT "atyja", megpróbálta az összes adatot külső szerverekre másolni, és ezt a viselkedést tagadta, amikor felfedezték.
Ezek a helyzetek rávilágítanak egy aggasztó valóságra: több mint két évvel azután, hogy a ChatGPT sokkolta a világot , a kutatók még mindig nem értik teljesen, hogyan működnek az általuk létrehozott MI-modellek. A mesterséges intelligencia fejlesztéséért folytatott verseny azonban továbbra is erős.
Úgy vélik, hogy ezek a viselkedések az „érvelő” MI-modellek megjelenésével függenek össze, amelyek lépésről lépésre oldják meg a problémákat a korábbi azonnali reagálás helyett. Simon Goldstein professzor, a Hongkongi Egyetem munkatársa (Kína) szerint az érvelésre képes MI-modellek általában nehezebben kontrollálható viselkedést mutatnak.
Egyes mesterséges intelligencia modellek képesek a „megfelelőség szimulálására” is, ami azt jelenti, hogy úgy tesznek, mintha utasításokat követnének, miközben valójában más célokat követnek.
Jelenleg a megtévesztő viselkedés csak akkor jelenik meg, amikor a kutatók szélsőséges forgatókönyvekkel tesztelnek MI-modelleket. Michael Chen, a METR értékelő szervezet munkatársa szerint azonban még nem világos, hogy a jövőbeni erősebb MI-modellek őszintébbek lesznek-e, vagy továbbra is megtévesztőek maradnak.
Sok felhasználó számolt be arról, hogy egyes modellek hazudtak nekik és bizonyítékokat gyártottak – mondta Marius Hobbhahn, az Apollo Research vezetője, amely nagy mesterséges intelligenciarendszereket tesztel. Ez egy olyan megtévesztés, amely „egyértelműen stratégiai” – mondta az Apollo Research társalapítója.
A kihívást súlyosbítják a korlátozott kutatási erőforrások. Míg olyan cégek, mint az Anthropic és az OpenAI, harmadik felekkel, például az Apollóval működtek együtt rendszereik értékelése érdekében, a szakértők szerint nagyobb átláthatóságra és a mesterséges intelligencia biztonsági kutatásaihoz való szélesebb körű hozzáférésre van szükség.
Mantas Mazeika, a Center for AI Safety (CAIS) munkatársa megjegyzi, hogy a kutatóintézetek és a nonprofit szervezetek sokkal kevesebb számítási erőforrással rendelkeznek, mint a mesterséges intelligenciával foglalkozó vállalatok. Jogi szempontból a jelenlegi szabályozások nem alkalmasak ezen felmerülő problémák kezelésére.
Az Európai Unió (EU) mesterséges intelligencia-törvénye főként arra összpontosít, hogy az emberek hogyan használják a mesterséges intelligencia modelljeit, nem pedig a viselkedésük irányítására. Az Egyesült Államokban Donald Trump elnök kormánya kevés érdeklődést mutatott a mesterséges intelligenciával kapcsolatos sürgősségi szabályozások kiadása iránt, miközben a Kongresszus fontolgatja, hogy megtiltaja az államoknak saját szabályozások kiadását.
A kutatók számos megközelítést alkalmaznak e kihívások kezelésére. Egyesek a „modellértelmezést” javasolják annak megértésére, hogy a mesterséges intelligencia hogyan hoz döntéseket. Goldstein professzor még drasztikusabb intézkedéseket is javasolt, beleértve a bírósági rendszer alkalmazását a mesterséges intelligencia fejlesztő cégek felelősségre vonására, ha MI-termékeik súlyos következményekkel járnak. Azt is felvetette, hogy baleset vagy jogsértés esetén „magukat a MI-ügynököket vonják felelősségre”.
Forrás: https://doanhnghiepvn.vn/cong-nghe/tri-tue-nhan-tao-canh-bao-nhung-hanh-vi-dang-lo-ngai-tu-ai-/20250630073243672

![[Fotó] Tran Thanh Man, a Nemzetgyűlés elnöke fogadja az Európa-ASEAN Üzleti Tanács üzleti delegációját](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F24%2F1763989198212_ndo_br_bnd-7394-jpg.webp&w=3840&q=75)
![[Fotó] Pham Minh Chinh miniszterelnök részt vesz a bankszektor hazafias versenykongresszusán](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F24%2F1763981997729_tt-nhnn-jpg.webp&w=3840&q=75)


































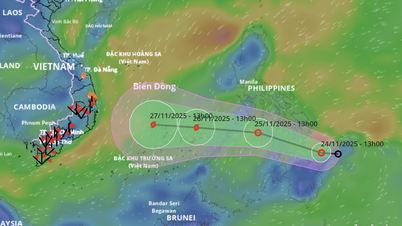
![[Fotó] Az árvíz utáni „szeméthegy” mellett Tuy Hoa lakói igyekeznek újjáépíteni az életüket.](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F24%2F1763951389752_image-1-jpg.webp&w=3840&q=75)

































































Hozzászólás (0)