
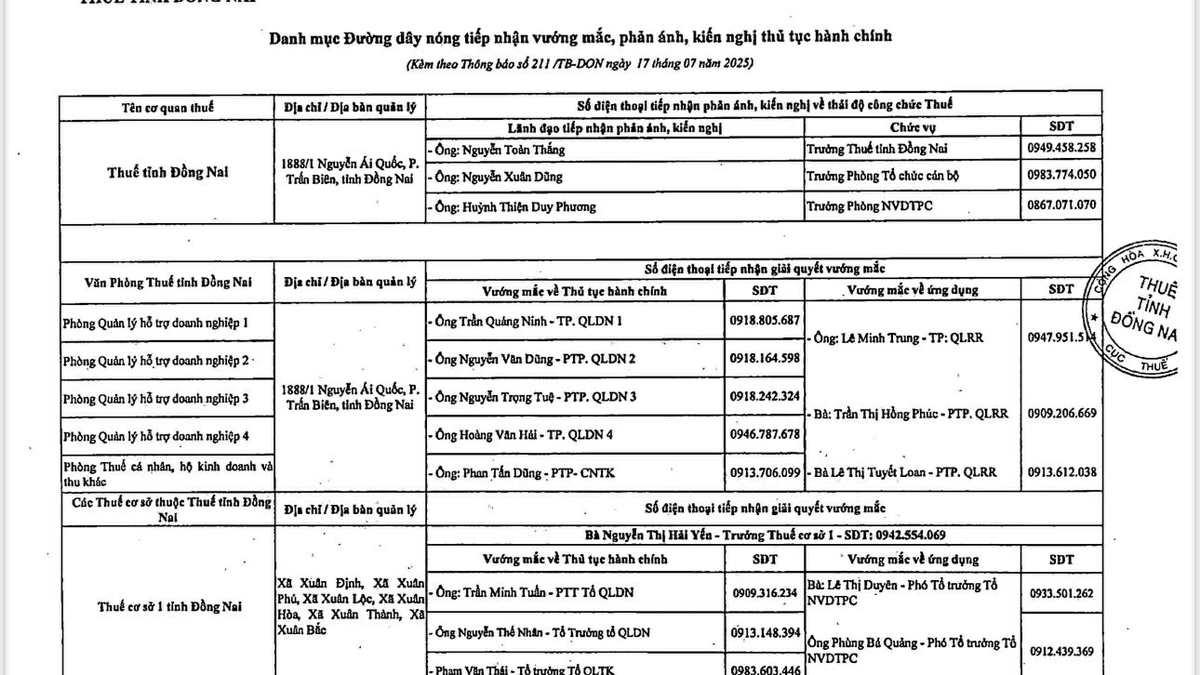
Исследование двух студентов из Технологического университета Хошимина, использующих методы состязательного обучения для генерации новых данных с помощью ИИ, было опубликовано на AAAI — ведущей мировой конференции по ИИ.
Исследование многоязычных моделей для обучения ИИ созданию синонимов, проведенное 23-летними Фам Кхань Чинем и Ле Минь Хоем, было опубликовано в документах конференции AAAI-24 по искусственному интеллекту, состоявшейся в конце февраля в Ванкувере, Канада.
Доцент, доктор Куан Тхань То, заместитель декана факультета компьютерных наук и инженерии Хошиминского технологического университета, оценил этот результат как достойный похвалы. Г-н То отметил, что исследователи и эксперты считают AAAI организацией высочайшего уровня в проведении научных конференций в области компьютерных наук и искусственного интеллекта, несмотря на очень низкий процент принятых статей – в этом году он составил 23,75%.

Минь Хой и Кхань Чинь (в центре) во время защиты дипломной работы, 2023 год. Фото: предоставлено персонажем
Разделяя страсть к глубокому обучению и обработке естественного языка, Тринь и Хой решили заняться исследованиями в области больших языковых моделей (LLM). Оба хотели выявить ограничения LLM и улучшить их.
Хань Чинь сказал, что чат-программы GPT или LLM необходимо обучать на огромном объёме текстовых данных, чтобы генерировать точные и разнообразные ответы для пользователей. Мальчики поняли, что при работе с менее популярными языками, такими как хинди, казахский или индонезийский, чат-программы GPT и LLM часто дают неожиданные результаты, поскольку они мало изучали эти языки или для них недостаточно данных.
«Почему бы нам не создать больше текстовых данных из „маленьких ресурсов“ этих языков для дальнейшего обучения ИИ?» — спросили двое студентов. Так родилась модель LAMPAT (низкоранговая адаптация для многоязыкового парафразирования с использованием состязательного обучения) — многоязыковой интерпретации с использованием метода состязательного обучения, разработанного Трин и Хоем.
LAMPAT способен генерировать синоним из заданного входного предложения для генерации дополнительных текстовых данных. Объяснитель «состязательного обучения» — относительно новый метод обучения больших языковых моделей. При использовании традиционных методов обучения, используя входное предложение, приложение генерирует выходное предложение. Однако при использовании состязательного обучения приложение может комментировать и редактировать выходное предложение «состязательное», чтобы генерировать больше предложений.
Многоязычность LAMPAT заключается в том, что эта модель одновременно интегрирует 60 языков. На основе собранных наборов данных команда продолжает обучать LAMPAT генерации синонимов. Объём текстовых данных, сгенерированных LAMPAT, будет и дальше использоваться для обучения LLM, чтобы эти модели могли изучать множество различных способов выражения информации для одного и того же контента, тем самым давая разнообразные ответы с большей вероятностью их правильности. Представитель команды считает, что благодаря этой функции LAMPAT можно интегрировать в такие приложения, как ChatGPT, для дальнейшего совершенствования модели.
Кроме того, отсутствие данных для Chat GPT или LLM вынуждает некоторые компании искать множество внешних источников, таких как книги, газеты, блоги и т. д., не обращая внимания на вопросы авторского права. По словам Ханя Чиня, создание синонимов также является одним из способов борьбы с плагиатом и нарушением авторских прав.
Нам Синх привел пример приложений, таких как Chat GPT: когда пользователь запрашивает краткое содержание существующего текста A, приложение сгенерирует краткое содержание текста B. Если метод исследования группы интегрирован, то при получении текста A приложение сгенерирует несколько текстов с одинаковым содержанием A1, A2, A3 на основе механизма генерации синонимов, из которых оно суммирует текст и выдает множество результатов для выбора пользователем.
На ранних этапах исследования команда столкнулась с трудностями при подготовке данных для оценки по 60 языкам. Из-за отсутствия доступа к достаточно большому объёму данных команда собрала разнообразный и полный набор данных по 13 языкам для объективной оценки модели, включая: вьетнамский, английский, французский, немецкий, русский, японский, китайский, испанский, венгерский, португальский, шведский, финский и чешский. Этот набор данных также является надёжным для финального этапа оценки с участием человека.

Минь Кхой (слева) и Кхань Чинь (справа) сделали памятное фото с учителем Куан Тхань То в день выпуска, ноябрь 2023 года. Фото: предоставлено персонажем
Для каждого из языков (английского, вьетнамского, немецкого, французского и японского) команда случайным образом извлекла 200 пар предложений (одна пара состояла из исходного предложения и правильной метки) для оценки. Для каждого из перечисленных языков команда попросила 5 лингвистов независимо оценить их по трём критериям: семантическая сохранность, выбор слов и лексическое сходство, а также беглость и связность исходного предложения. Шкала была рассчитана от 1 до 5. В результате средний балл, выставленный лингвистами по этим 5 языкам, составил от 4,2 до 4,6/5 баллов.
В примере приведена пара предложений на вьетнамском языке, оцененных в 4,4/5, в которой входное предложение: «Он подробно объяснил проблему», а выходное предложение: «Он подробно объяснил проблему».
Но есть и пары предложений низкого качества, содержащие семантические ошибки, например, пара предложений «Мы едим, пока суп горячий — Мы едим суп, пока мы горячие», которая оценивается всего в 2/5 балла.
Хань Чинь рассказал, что на исследование и реализацию этого проекта ушло 8 месяцев. Это также тема выпускной работы Чиня и Хоя. Диссертация заняла первое место в рейтинге Computer Science Council 2, набрав 9,72 балла из 10.
По словам г-на Куан Тхань То, хотя LAMPAT продемонстрировал свою компетентность в создании фраз-синонимов, похожих на человеческие, на нескольких языках, ему все еще требуется усовершенствование для обработки идиом, народных песен и пословиц на разных языках.
Кроме того, оценочный набор данных команды включает всего 13 языков, что по-прежнему не учитывает многие языки, особенно языки меньшинств. Поэтому команде необходимо провести исследование, чтобы улучшить и расширить возможности существующих многоязычных моделей перевода. Это позволит устранить языковой барьер между странами и этническими группами.
В конце 2023 года Тринь и Хой с отличием окончили факультет компьютерных наук со средним баллом 3,7 и 3,9/4 соответственно. Оба планируют продолжить обучение за рубежом, чтобы получить степень магистра, и продолжить исследования в области искусственного интеллекта и машинного обучения.
«Мы продолжаем исследовать эту тему с целью более широкого применения LAMPAT в будущих научных проектах, создавая надежный многоязычный продукт для пользователей», — поделился Тринь.
Ле Нгуен
Ссылка на источник



















![[Фото] Председатель Национальной ассамблеи Тран Тхань Ман посещает вьетнамскую героическую мать Та Тхи Тран](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/7/20/765c0bd057dd44ad83ab89fe0255b783)












































































Комментарий (0)