
ในบริบทของการเปลี่ยนแปลงทางดิจิทัลและการเปลี่ยนผ่านสู่ปัญญาประดิษฐ์ (AI) ในเวียดนาม เทคโนโลยี OCR (การรู้จำอักขระด้วยแสง) มีบทบาทสำคัญเพิ่มมากขึ้นในการแปลงเอกสารเป็นดิจิทัล การทำให้กระบวนการทางธุรกิจเป็นระบบอัตโนมัติ การประหยัดต้นทุน และการปรับปรุงประสิทธิภาพการบริหารจัดการ อย่างไรก็ตาม ด้วยลักษณะเฉพาะของชาวเวียดนามที่มีสำเนียงและลายมือ ปัญหาการรู้จำไม่ได้หยุดอยู่แค่ "การอ่านคำ" เท่านั้น แต่ยังจำเป็นต้องอาศัยความสามารถในการเข้าใจบริบทอย่างครอบคลุม
ล่าสุด CMC Technology Application Institute (CMC ATI) ได้ประกาศเปิดตัวโมเดล CATI-VLM (Visual Document Understanding) ที่ทีมวิจัยพัฒนาจากคลังข้อมูลขนาดใหญ่ 5TB ขึ้นสู่อันดับ 12 ของโลก และอันดับ 1 ของประเทศเวียดนาม ในการจัดอันดับที่เพิ่งประกาศโดย Robust Reading Competition (RRC) เมื่อเดือนมิถุนายน 2568 ในประเภท Document Visual Question Answering (DocVQA)
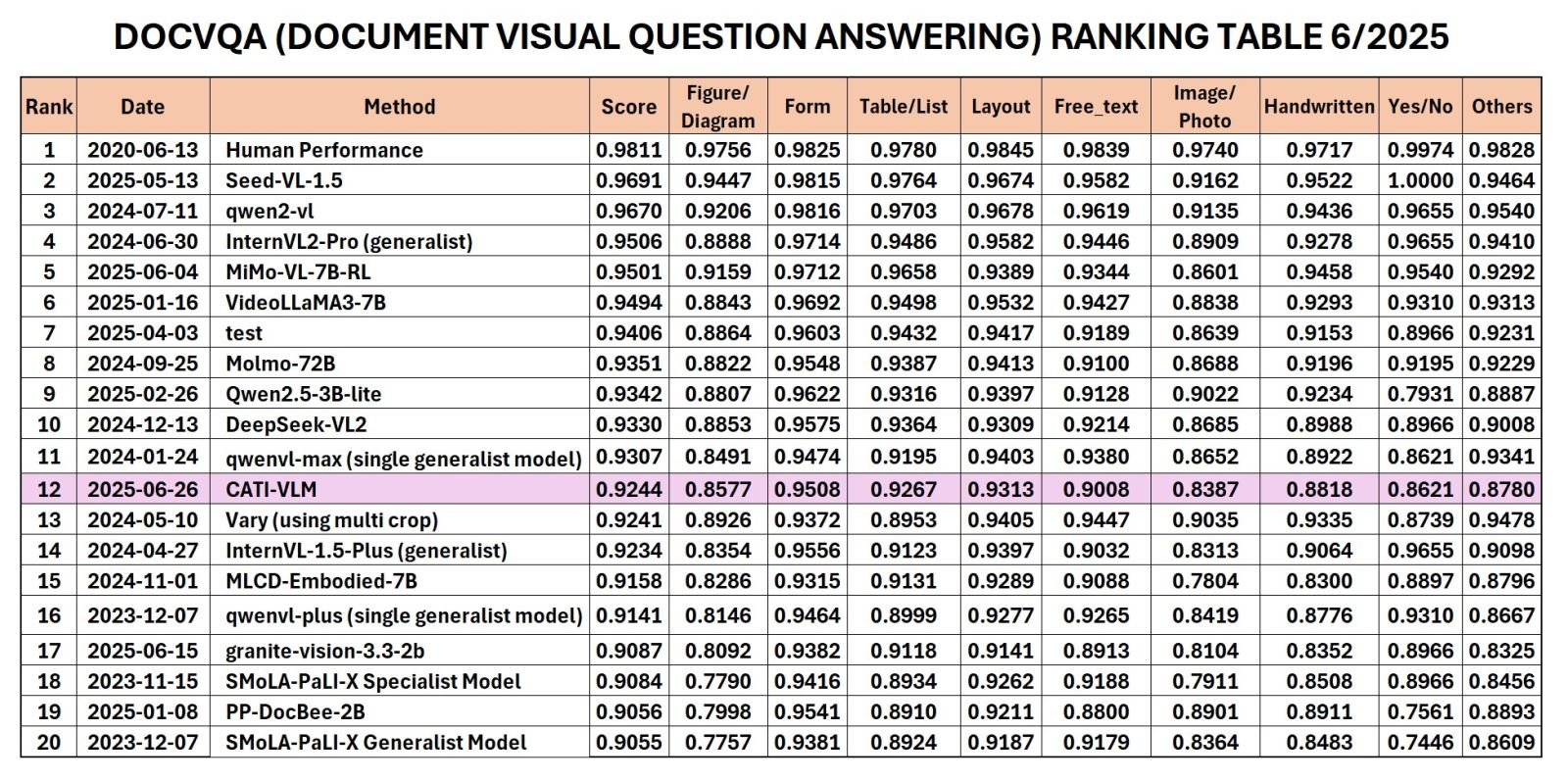
อันดับ RRC ในหมวด DocVQA 6/2025
การแข่งขันการอ่านอย่างเข้มข้น (Robust Reading Competition: RRC) เป็นเวที วิทยาศาสตร์ อันทรงเกียรติ (https://rrc.cvc.uab.es/) จัดโดยศูนย์วิชั่นคอมพิวเตอร์ (CVC) แห่งมหาวิทยาลัยออโตโนมาแห่งบาร์เซโลนา (UAB) ประเทศสเปน ซึ่งเป็นศูนย์วิจัยที่มีชื่อเสียงระดับโลกด้านวิชั่นคอมพิวเตอร์ การแข่งขันนี้เริ่มต้นขึ้นในปี พ.ศ. 2554 พร้อมกับการประชุมนานาชาติว่าด้วยการวิเคราะห์และการรู้จำข้อความ (ICDAR) ซึ่งเป็นหนึ่งในเวทีที่ใหญ่ที่สุดในโลกด้านการวิเคราะห์เอกสารและวิชั่นคอมพิวเตอร์ การแข่งขันนี้ได้กลายเป็นกิจกรรมสำคัญที่ดึงดูดนักวิจัย วิศวกรจากมหาวิทยาลัยชั้นนำ สถาบันวิจัย และบริษัทเทคโนโลยีต่างๆ เช่น มหาวิทยาลัยชิงหวา ฮุนไดมอเตอร์กรุ๊ป และเทนเซ็นต์... ภารกิจของ RRC มุ่งเน้นการส่งเสริมความก้าวหน้าทางเทคโนโลยี ซึ่งเชื่อมโยงอย่างใกล้ชิดกับปัญหาเชิงปฏิบัติ ตั้งแต่การแปล การจัดการข้อมูลองค์กร การวิเคราะห์เมือง และการประมวลผลเอกสารทางประวัติศาสตร์
ดร. ดัง มินห์ ตวน ผู้อำนวยการ CMC ATI กล่าวว่า "ศักยภาพด้านการวิจัยของทีม CMC ได้รับการยืนยันจากสนามวิจัยระดับโลกอันทรงเกียรติอย่าง RRC เราภูมิใจที่ในเวลาอันสั้น ทีมสามารถก้าวขึ้นสู่ตำแหน่งระดับสูง เคียงบ่าเคียงไหล่กับผู้เชี่ยวชาญจากประเทศพัฒนาแล้ว ที่สำคัญยิ่งกว่านั้น นี่คือการพิสูจน์ให้เห็นอย่างชัดเจนถึงความสามารถในการเชี่ยวชาญด้านเทคโนโลยีเพื่อแก้ไขปัญหาเฉพาะด้านของเวียดนามและสาขาเฉพาะทางในเวียดนาม"
CATI-VLM แตกต่างจาก OCR ทั่วไปตรงที่ไม่เพียงแต่สามารถแยกอักขระได้เท่านั้น แต่ยังเข้าใจข้อมูลหลายชั้น ได้แก่ เนื้อหาข้อความ องค์ประกอบที่ไม่ใช่ข้อความ (ช่องกาเครื่องหมาย ช่องกาเครื่องหมาย แผนภูมิ ลายเซ็น สูตร) เค้าโครง (โครงสร้างหน้า ตาราง แบบฟอร์ม) และสไตล์ (แบบอักษร ไฮไลต์ ฯลฯ) โมเดลนี้สามารถตอบคำถามภาพที่ปรากฏบนภาพเอกสารได้ คล้ายกับ ChatGPT โดยไม่จำเป็นต้องเรียนรู้แบบฟอร์มเฉพาะเจาะจงล่วงหน้า
ตามรายงานของหนังสือพิมพ์ News and People
ที่มา: https://doanhnghiepvn.vn/cong-nghe/ai-loi-make-in-vietnam-duoc-xep-hang-top-12-the-gioi/20250703100726051
![[ภาพถ่าย] เยี่ยมชมหุ่งเยนเพื่อชื่นชมเจดีย์ “ผลงานชิ้นเอกไม้” ใจกลางสามเหลี่ยมปากแม่น้ำเหนือ](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F21%2F1763716446000_a1-bnd-8471-1769-jpg.webp&w=3840&q=75)

![[ภาพ] เลขาธิการโต ลัม ต้อนรับประธานวุฒิสภาสาธารณรัฐเช็ก มิโลส วิสตริซิล](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F21%2F1763723946294_ndo_br_1-8401-jpg.webp&w=3840&q=75)

![[ภาพ] ประธานรัฐสภา ตรัน ถันห์ มาน หารือกับประธานวุฒิสภาสาธารณรัฐเช็ก มิโลส วิสตริซิล](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F21%2F1763715853195_ndo_br_bnd-6440-jpg.webp&w=3840&q=75)
![[ภาพ] ประธานาธิบดีเลืองเกวงให้การต้อนรับประธานสภาแห่งชาติเกาหลี วู วอน ชิก](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F11%2F21%2F1763720046458_ndo_br_1-jpg.webp&w=3840&q=75)






































































































การแสดงความคิดเห็น (0)