
غول فناوری OpenAI، ابزار تبدیل گفتار به متن خود، Whisper، را به عنوان یک هوش مصنوعی با «دقت و استحکامی شبیه به انسان» تبلیغ میکرد. اما Whisper یک نقص عمده داشت: متن و جملاتی تولید میکرد که کاملاً جعلی بودند.
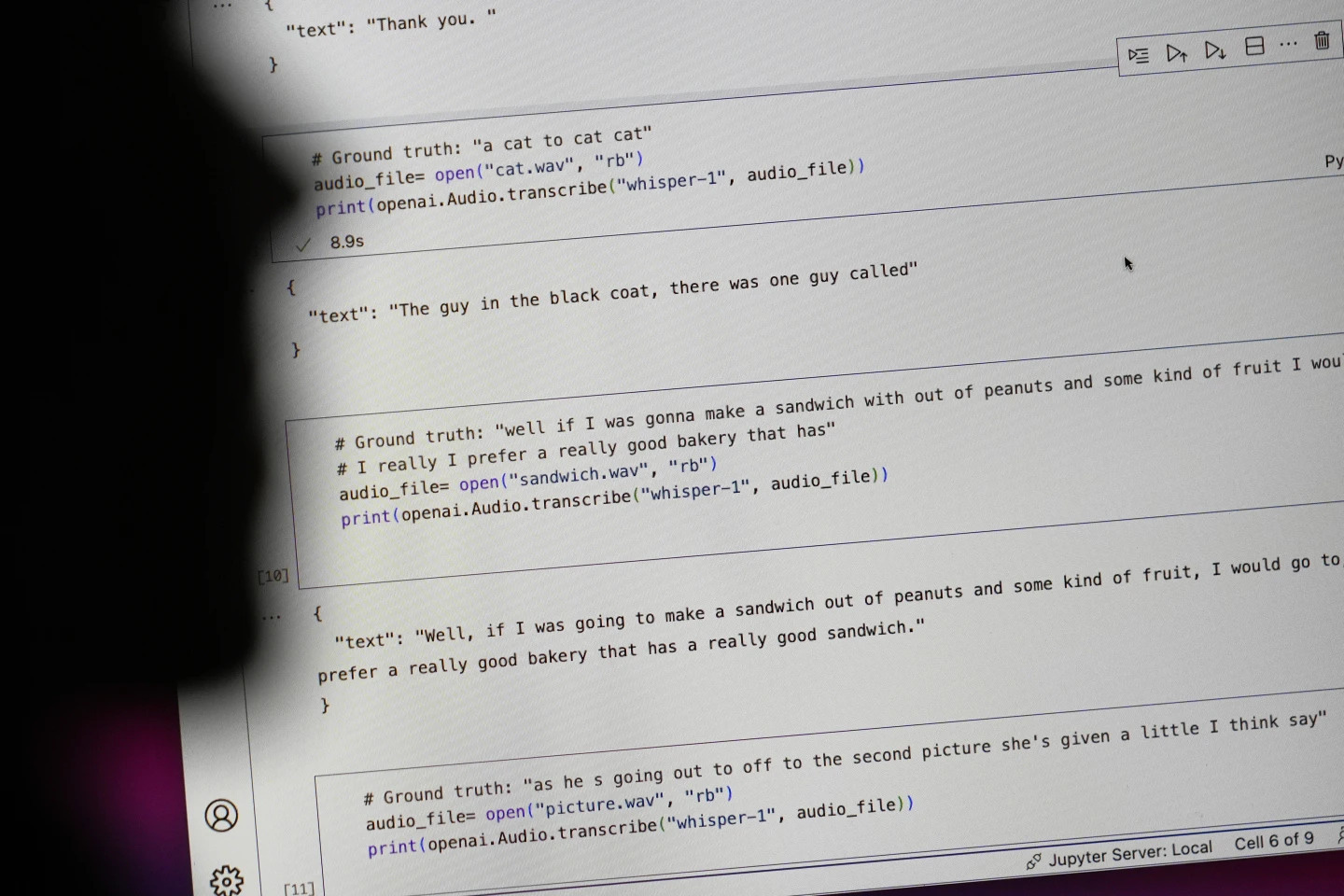
برخی از متنهای تولید شده توسط هوش مصنوعی - که «توهم» نامیده میشوند - میتوانند شامل نظرات نژادپرستانه، زبان خشونتآمیز و حتی درمانهای پزشکی خیالی باشند - عکس: AP
به گزارش آسوشیتدپرس، کارشناسان میگویند برخی از متنهای تولید شده توسط هوش مصنوعی به اصطلاح «توهمآلود» هستند، از جمله نظرات نژادپرستانه، زبان خشونتآمیز و حتی درمانهای پزشکی خیالی.
میزان بالای «توهم» در متون تولید شده توسط هوش مصنوعی
کارشناسان به ویژه نگران هستند زیرا Whisper به طور گسترده در بسیاری از صنایع در سراسر جهان برای ترجمه و رونویسی مصاحبهها، تولید متن در فناوریهای محبوب مصرفکننده و ایجاد زیرنویس برای ویدیوها استفاده میشود.
نگرانکنندهتر اینکه، بسیاری از مراکز پزشکی از Whisper برای انتقال مشاوره بین پزشکان و بیماران استفاده میکنند، اگرچه OpenAI هشدار داده است که این ابزار نباید در مناطق «پرخطر» استفاده شود.
تعیین وسعت کامل این مشکل دشوار است، اما محققان و مهندسان میگویند که مرتباً در کار خود با "توهمات" ویسپر مواجه میشوند.
یک محقق در دانشگاه میشیگان گفت که از هر ده رونویسی صوتی که بررسی کرده، در هشت مورد «توهم» یافته است. یک مهندس کامپیوتر در حدود نیمی از رونویسیهای بیش از ۱۰۰ ساعت صوتی که تجزیه و تحلیل کرده، «توهم» یافته است. یک توسعهدهنده دیگر گفت که تقریباً در تمام ۲۶۰۰۰ ضبطی که با استفاده از Whisper ایجاد کرده، «توهم» یافته است.
این مشکل حتی با نمونههای صوتی کوتاه و واضح ضبطشده نیز ادامه دارد. یک مطالعه اخیر توسط دانشمندان کامپیوتر، ۱۸۷ «توهم» را در بیش از ۱۳۰۰۰ کلیپ صوتی واضح که بررسی کردند، نشان داد. محققان گفتند که این گرایش منجر به دهها هزار رونویسی نادرست در میلیونها ضبط میشود.
به گفته آلوندرا نلسون، که تا سال گذشته ریاست دفتر علوم و فناوری کاخ سفید را در دولت بایدن بر عهده داشت، چنین خطاهایی میتواند «عواقب بسیار جدی» به ویژه در محیطهای بیمارستانی داشته باشد.
نلسون، که اکنون استاد موسسه مطالعات پیشرفته در پرینستون، نیوجرسی است، گفت: «هیچکس تشخیص اشتباه نمیخواهد. باید استاندارد بالاتری وجود داشته باشد.»
از Whisper همچنین برای ایجاد زیرنویس برای ناشنوایان و کمشنوایان استفاده میشود - جمعیتی که به ویژه در معرض خطر ترجمههای نادرست هستند. کریستین وگلر، ناشنوا و مدیر برنامه دسترسی به فناوری در دانشگاه گالودت، میگوید: «به این دلیل که افراد ناشنوا و کمشنوا هیچ راهی برای شناسایی متون ساختگی «پنهان در تمام متنهای دیگر» ندارند.»
از OpenAI خواسته شده است تا مشکل را حل کند
شیوع چنین «توهماتی» باعث شده است که متخصصان، مدافعان و کارمندان سابق OpenAI از دولت فدرال بخواهند که مقررات هوش مصنوعی را در نظر بگیرد. حداقل، OpenAI باید این نقص را برطرف کند.
ویلیام ساندرز، مهندس تحقیقاتی در سانفرانسیسکو که در ماه فوریه به دلیل نگرانی در مورد مسیر شرکت OpenAI، این شرکت را ترک کرد، گفت: «اگر شرکت مایل به اولویتبندی آن باشد، این مشکل قابل حل است.»
«اگر آن را منتشر کنید و مردم آنقدر به تواناییهای آن اعتماد کنند که آن را در تمام این سیستمهای دیگر ادغام کنند، مشکلساز خواهد بود.» سخنگوی OpenAI گفت که این شرکت دائماً در حال کار بر روی راههایی برای کاهش «توهمات» است و از یافتههای محققان قدردانی میکند و افزود که OpenAI بازخوردها را در بهروزرسانیهای مدل لحاظ میکند.
در حالی که اکثر توسعهدهندگان فرض میکنند که ابزارهای تبدیل متن به گفتار میتوانند غلط املایی یا اشتباهات دیگری داشته باشند، مهندسان و محققان میگویند که هرگز ابزار تبدیل متن به گفتار مبتنی بر هوش مصنوعی ندیدهاند که به اندازه Whisper «توهم» ایجاد کند.
 جایزه نوبل فیزیک ۲۰۲۴: افرادی که پایههای هوش مصنوعی را بنا نهادند
جایزه نوبل فیزیک ۲۰۲۴: افرادی که پایههای هوش مصنوعی را بنا نهادندمنبع: https://tuoitre.vn/cong-cu-ai-chuyen-loi-noi-thanh-van-ban-cua-openai-bi-phat-hien-bia-chuyen-20241031144507089.htm



![[عکس] نخست وزیر فام مین چین، جلسهای را برای استقرار نیروهای مقابله با پیامدهای طوفان شماره ۱۰ ریاست کرد](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/3/544f420dcc844463898fcbef46247d16)

![[عکس] دانشآموزان مدرسه ابتدایی بین مین از جشنواره ماه کامل لذت میبرند و شادیهای کودکی را تجربه میکنند](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/3/8cf8abef22fe4471be400a818912cb85)































































































نظر (0)