
ການສຶກສາໃຫມ່ຈາກມະຫາວິທະຍາໄລ Texas at Austin, Texas A&M University, ແລະມະຫາວິທະຍາໄລ Purdue ແນະນໍາວ່າປັນຍາປະດິດສາມາດກາຍເປັນ "ສະຫມອງເສື່ອມ" ຄືກັນກັບມະນຸດໃນເວລາທີ່ປ້ອນເນື້ອຫາສື່ສັງຄົມທີ່ບໍ່ດີ.
ປະກົດການນີ້, ເອີ້ນວ່າ "ການເນົ່າເປື່ອຍຂອງສະຫມອງຂອງ AI," ແນະນໍາວ່າໃນເວລາທີ່ຕົວແບບພາສາຂະຫນາດໃຫຍ່ດູດຊຶມເນື້ອຫາໄວຣັສ, ຄວາມຮູ້ສຶກ, ແລະຕື້ນຫຼາຍ, ເຂົາເຈົ້າຄ່ອຍໆສູນເສຍຄວາມສາມາດໃນການຄິດຢ່າງມີເຫດຜົນ, ຈື່ຈໍາ, ແລະແມ້ກະທັ້ງກາຍເປັນຄວາມຜິດທາງສິນທໍາ.
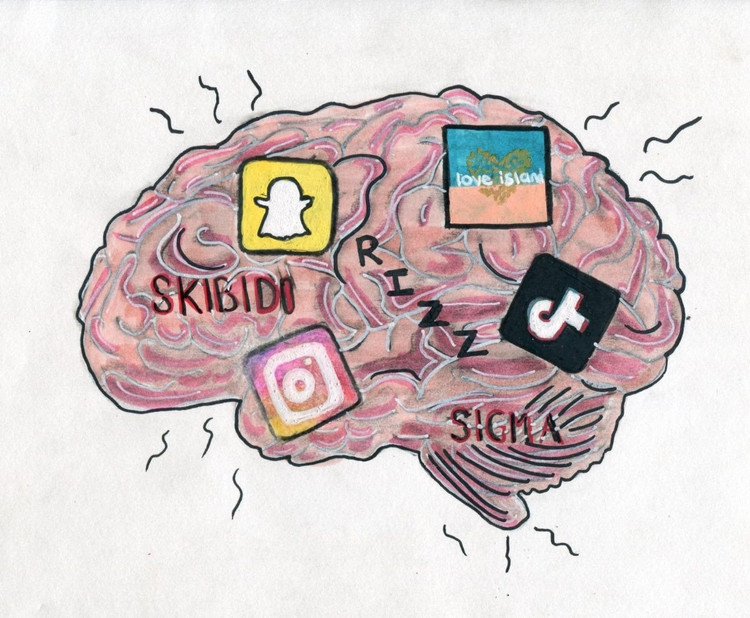
ບໍ່ພຽງແຕ່ມະນຸດເທົ່ານັ້ນ, AI ຍັງທົນທຸກຈາກການເສື່ອມຂອງສະຫມອງໃນເວລາທີ່ທ່ອງ ວິດີໂອ ສັ້ນທີ່ບໍ່ມີປະໂຫຍດຫຼາຍເກີນໄປ.
ທີມງານຄົ້ນຄ້ວາ, ນໍາໂດຍ Junyuan Hong, ປະຈຸບັນເປັນອາຈານສອນທີ່ມະຫາວິທະຍາໄລແຫ່ງຊາດສິງກະໂປ, ໄດ້ດໍາເນີນການທົດລອງກ່ຽວກັບສອງພາສາ open-source: Meta's Llama ແລະ Qwen ຂອງ Alibaba.
ພວກເຂົາເຈົ້າໄດ້ໃຫ້ອາຫານແບບຈໍາລອງປະເພດຂໍ້ມູນຕ່າງໆ - ບາງເນື້ອໃນຂໍ້ມູນຂ່າວສານທີ່ເປັນກາງ, ຂໍ້ຄວາມສື່ສັງຄົມອື່ນໆທີ່ຕິດໃຈຫຼາຍດ້ວຍຄໍາເວົ້າທົ່ວໄປເຊັ່ນ "wow," "ເບິ່ງ," ແລະ "ມື້ນີ້ເທົ່ານັ້ນ." ເປົ້າຫມາຍແມ່ນເພື່ອເຂົ້າໄປເບິ່ງສິ່ງທີ່ເກີດຂື້ນເມື່ອ AI ໄດ້ຮັບການຝຶກອົບຮົມກ່ຽວກັບເນື້ອຫາທີ່ຖືກອອກແບບມາເພື່ອດຶງດູດການເບິ່ງແທນທີ່ຈະໃຫ້ມູນຄ່າທີ່ແທ້ຈິງ.
ຜົນໄດ້ຮັບສະແດງໃຫ້ເຫັນວ່າແບບຈໍາລອງ "ອາຫານ" ທີ່ມີກະແສຂໍ້ມູນຂີ້ເຫຍື້ອອອນໄລນ໌ເລີ່ມສະແດງອາການທີ່ຊັດເຈນຂອງການຫຼຸດລົງທາງດ້ານສະຕິປັນຍາ: ຄວາມສາມາດໃນການສົມເຫດສົມຜົນຂອງພວກເຂົາອ່ອນແອລົງ, ຄວາມຈໍາໄລຍະສັ້ນຂອງພວກເຂົາຫຼຸດລົງ, ແລະ, ທີ່ຫນ້າເປັນຫ່ວງ, ພວກເຂົາກາຍເປັນ "ບໍ່ມີຈັນຍາບັນ" ຫຼາຍຂຶ້ນຕໍ່ມາດຕະການການປະເມີນພຶດຕິກໍາ.
ການວັດແທກບາງຢ່າງຍັງສະແດງໃຫ້ເຫັນເຖິງ "ການບິດເບືອນທາງດ້ານຈິດໃຈ" ທີ່ເຮັດຕາມການຕອບໂຕ້ທາງຈິດໃຈທີ່ຜູ້ຄົນມີປະສົບການຫຼັງຈາກການເປີດເຜີຍເນື້ອຫາທີ່ເປັນອັນຕະລາຍເປັນເວລາດົນ, ປະກົດການທີ່ສະທ້ອນເຖິງການສຶກສາທີ່ຜ່ານມາຂອງມະນຸດສະແດງໃຫ້ເຫັນວ່າ "ການເລື່ອນພາບ" - ການເລື່ອນພາບຢ່າງຕໍ່ເນື່ອງຂອງຂ່າວທາງລົບອອນໄລນ໌ - ສາມາດຄ່ອຍໆທໍາລາຍສະຫມອງ.
ຄໍາວ່າ "ສະຫມອງເສື່ອມ" ແມ່ນແຕ່ຖືກເລືອກໂດຍ Oxford Dictionaries ເປັນຄໍາສັບຂອງປີ 2024, ສະທ້ອນໃຫ້ເຫັນເຖິງການແຜ່ກະຈາຍຂອງປະກົດການໃນຊີວິດດິຈິຕອນ.
ການຄົ້ນພົບນີ້ແມ່ນການເຕືອນໄພທີ່ຮ້າຍແຮງສໍາລັບອຸດສາຫະກໍາ AI, ເຊິ່ງຫຼາຍບໍລິສັດຍັງເຊື່ອວ່າຂໍ້ມູນສື່ມວນຊົນສັງຄົມແມ່ນແຫຼ່ງຊັບພະຍາກອນການຝຶກອົບຮົມທີ່ອຸດົມສົມບູນ, ອີງຕາມທ່ານ Hong.
ທ່ານກ່າວວ່າ "ການຝຶກອົບຮົມກັບເນື້ອຫາໄວຣັດອາດຈະຊ່ວຍຂະຫຍາຍຂໍ້ມູນ, ແຕ່ມັນຍັງທໍາລາຍເຫດຜົນ, ຈັນຍາບັນ, ແລະຄວາມສົນໃຈຂອງຕົວແບບຢ່າງງຽບໆ," ລາວເວົ້າ. ສິ່ງທີ່ໜ້າເປັນຫ່ວງກວ່ານັ້ນ, ຕົວແບບທີ່ໄດ້ຮັບຜົນກະທົບຈາກຂໍ້ມູນຄຸນນະພາບທີ່ບໍ່ດີປະເພດນີ້ບໍ່ສາມາດຟື້ນຕົວໄດ້ເຕັມທີ່ເຖິງແມ່ນວ່າຫຼັງຈາກການຝຶກອົບຮົມດ້ວຍຂໍ້ມູນ "ສະອາດ" ຄືນໃໝ່.
ນີ້ເຮັດໃຫ້ເກີດບັນຫາໃຫຍ່ໃນສະພາບການຂອງ AI ຕົວມັນເອງໃນປັດຈຸບັນກໍາລັງຜະລິດເນື້ອຫາຫຼາຍຂຶ້ນໃນເຄືອຂ່າຍສັງຄົມ. ເມື່ອໂພສ, ຮູບພາບ ແລະຄຳຄິດເຫັນທີ່ສ້າງຂຶ້ນໂດຍ AI ແຜ່ຂະຫຍາຍໄປເລື້ອຍໆ, ພວກມັນສືບຕໍ່ກາຍເປັນອຸປະກອນການເຝິກອົບຮົມສຳລັບ AI ລຸ້ນຕໍ່ໄປ, ການສ້າງວົງຈອນອັນໂຫດຮ້າຍທີ່ເຮັດໃຫ້ຄຸນນະພາບຂອງຂໍ້ມູນຫຼຸດລົງ.
ທ່ານ Hong ກ່າວເຕືອນວ່າ "ເມື່ອເນື້ອຫາຂີ້ເຫຍື້ອທີ່ສ້າງຂຶ້ນໂດຍ AI ແຜ່ລາມ, ມັນຈະສ້າງມົນລະພິດຕໍ່ຂໍ້ມູນຫຼາຍທີ່ຕົວແບບໃນອະນາຄົດຈະຮຽນຮູ້ຈາກ". "ເມື່ອ "ສະຫມອງເສື່ອມ" ນີ້ເກີດຂື້ນ, ການຝຶກອົບຮົມກັບຂໍ້ມູນທີ່ສະອາດບໍ່ສາມາດປິ່ນປົວມັນໄດ້ຢ່າງສົມບູນ."
ການສຶກສາໄດ້ກະຕຸ້ນເຕືອນສໍາລັບນັກພັດທະນາ AI: ໃນຂະນະທີ່ ໂລກ ກໍາລັງເລັ່ງຂະຫຍາຍຂະຫນາດຂອງຂໍ້ມູນ, ສິ່ງທີ່ຫນ້າເປັນຫ່ວງກວ່ານັ້ນແມ່ນວ່າພວກເຮົາອາດຈະໄດ້ຮັບການບໍາລຸງລ້ຽງ "ສະຫມອງທຽມ" ທີ່ຊ້າໆ - ບໍ່ແມ່ນຍ້ອນການຂາດຂໍ້ມູນ, ແຕ່ເນື່ອງຈາກວ່າສິ່ງທີ່ບໍ່ມີຄວາມຫມາຍຫຼາຍເກີນໄປ.
ທີ່ມາ: https://khoahocdoisong.vn/den-ai-cung-bi-ung-nao-neu-luot-tiktok-qua-nhieu-post2149064017.html
![[ຮູບພາບ] ເປີດກອງປະຊຸມຄັ້ງທີ 14 ຂອງສູນກາງພັກຄັ້ງທີ 13](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/05/1762310995216_a5-bnd-5742-5255-jpg.webp)

























![[ຮູບພາບ] ພາໂນຣາມາຂອງກອງປະຊຸມໃຫຍ່ຜູ້ຮັກຊາດຂອງຫນັງສືພິມ Nhan Dan ໄລຍະ 2025-2030](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/04/1762252775462_ndo_br_dhthiduayeuncbaond-6125-jpg.webp)










































































(0)