
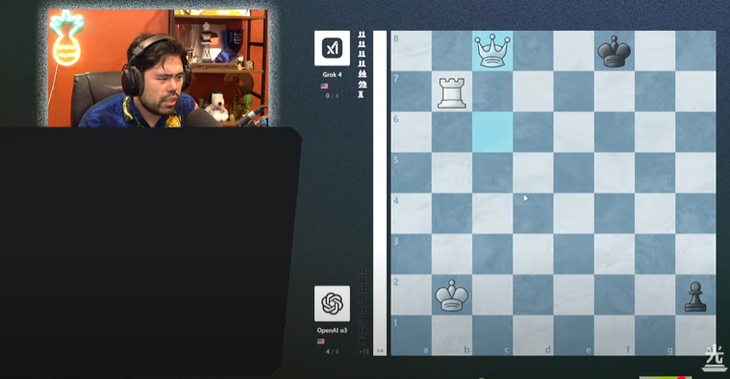
Spiller Nakamura sa at Grok 4 så ut til å ha spilt med en anspent mentalitet i den siste kampen - Foto: skjermbilde
Før kampen skapte OpenAI oppstyr da de annonserte lanseringen av den 11. generasjonen av LLM, GPT-5.
Imidlertid viste o3-ChatGPT-modellen som ble brukt i finalen fortsatt sterke slutningsevner, med en gjennomsnittlig korrekt bevegelsesrate på opptil 90,8 %, som fullstendig overgikk Grok 4s 80,2 %.
I alle fire partiene ga ikke ChatGPT Grok 4 noen sjanse, og satte motstanderen sjakkmatt etter henholdsvis 35, 30, 28 og 54 trekk.
Ifølge verdens nummer to, Hikaru Nakamura, virket det som om Grok 4 spilte med mer spenning og gjorde flere feil enn i tidligere runder. Spesielt mistet de brikker lett – en sjelden forekomst da de overveldende slo Googles Gemini 2.5 Flash og Gemini 2.5 Pro.
Med tre seire på rad med en score på 4-0 og en gjennomsnittlig treffsikkerhet på opptil 91 %, avsluttet o3 turneringen perfekt.
Selv om o3s styrke ikke kan sammenlignes med profesjonelle sjakkstormestere, er den nok til å skape problemer for spillere med Elo under 2000. Spesielt i blitz- og superblitz-kategoriene.
Den Google-organiserte turneringen endte med absolutt dominans fra de amerikanske representantene. Mens de to kinesiske modellene, Kimi K4 og DeepSeek, begge ble eliminert tidlig, ble tredjeplasskampen vunnet av Gemini 2.5 Pro over o4-mini, og befestet dermed posisjonen til de ledende amerikanske teknologiselskapene.
Denne hendelsen viser ikke bare de fantastiske egenskapene til generelle AI-modeller innen et spesialisert felt. Den åpner også et nytt perspektiv på utviklingspotensialet for kunstig intelligens i fremtiden.
Det er imidlertid også en påminnelse om at selv om LLM-er utvikler seg raskt, kan de fortsatt ikke matche nivået til profesjonelle sjakkmaskiner, hvis Elo-rangeringer langt overgår menneskers.
Kilde: https://tuoitre.vn/chatgpt-dang-quang-giai-co-vua-danh-cho-ai-20250808090405997.htm
![[Foto] Høstmessen 2025 – En attraktiv opplevelse](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/30/1761791564603_1761738410688-jpg.webp)

![[Foto] Tran Cam Tu, fast medlem av sekretariatet, besøker og oppmuntrer folk i de oversvømte områdene i Da Nang.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/30/1761808671991_bt4-jpg.webp)






























![[Foto] Medlemmer av New Era-partiet i den «grønne industriparken»](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/30/1761789456888_1-dsc-5556-jpg.webp)





































































Kommentar (0)