

GPU-en er hjernen til en AI-datamaskin
Enkelt sagt fungerer grafikkprosessoren (GPU) som hjernen til AI-datamaskinen.
Som du kanskje vet, er den sentrale prosessorenheten (CPU) hjernen i datamaskinen. Fordelen med en GPU er at den er en spesialisert CPU som kan utføre komplekse beregninger. Den raskeste måten å gjøre dette på er å la grupper av GPU-er løse det samme problemet. Det kan imidlertid fortsatt ta uker eller til og med måneder å trene en AI-modell. Når den er bygget, plasseres den i et front-end-datasystem, og brukere kan stille spørsmål til AI-modellen, en prosess som kalles inferens.
En AI-datamaskin som inneholder flere GPU-er
Den beste arkitekturen for AI-problemer er å bruke en klynge av GPU-er i et rack, koblet til en svitsj på toppen av racket. Flere GPU-rack kan kobles til i et nettverkshierarki. Etter hvert som problemet blir mer komplekst, øker GPU-kravene, og noen prosjekter kan trenge å distribuere klynger på tusenvis av GPU-er.
Hver AI-klynge er et lite nettverk
Når man bygger en AI-klynge, er det nødvendig å sette opp et lite datanettverk for å koble til og la GPU-er samarbeide og dele data effektivt.
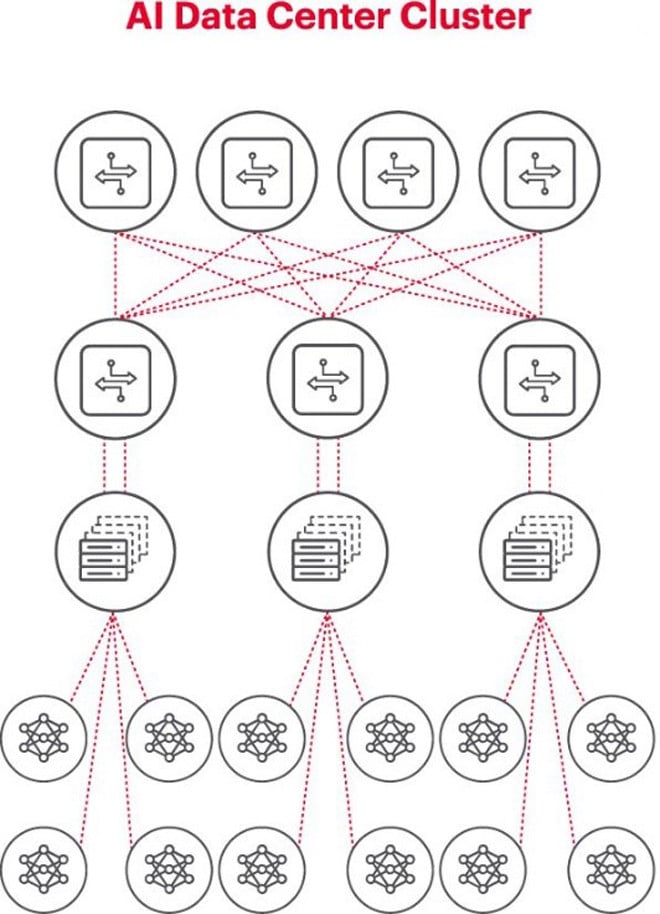
Figuren ovenfor illustrerer en AI-klynge der sirklene nederst representerer arbeidsflytene som kjører på GPU-er. GPU-ene kobles til Top-of-Rack (ToR)-svitsjene. ToR-svitsjene kobles også til nettverksryggradsvitsjene som vises ovenfor diagrammet, noe som demonstrerer det tydelige nettverkshierarkiet som kreves når flere GPU-er er involvert.
Nettverk er en flaskehals i AI-distribusjon
I fjor høst, på Open Computer Project (OCP) Global Summit, hvor delegatene jobbet med å bygge neste generasjon AI-infrastruktur, kom delegat Loi Nguyen fra Marvell Technology med et sentralt poeng: «nettverk er den nye flaskehalsen».
Teknisk sett kan høy pakkeforsinkelse eller pakketap på grunn av nettverksbelastning føre til at pakker sendes på nytt, noe som øker fullføringstiden for jobber betydelig. Som et resultat sløser bedrifter bort GPU-er verdt millioner eller titalls millioner dollar på grunn av ineffektive AI-systemer, noe som koster bedrifter både inntekter og tid til markedet.
Måling er en nøkkelforutsetning for vellykket drift av AI-nettverk
For å kjøre en AI-klynge effektivt, må GPU-er kunne utnyttes fullt ut for å forkorte treningstiden og ta læringsmodellen i bruk for å maksimere avkastningen på investeringen. Derfor er det nødvendig å teste og evaluere ytelsen til AI-klyngen (figur 2). Denne oppgaven er imidlertid ikke enkel, fordi det når det gjelder systemarkitektur er mange innstillinger og forhold mellom GPU-er og nettverksstrukturer som må utfylle hverandre for å løse problemet.
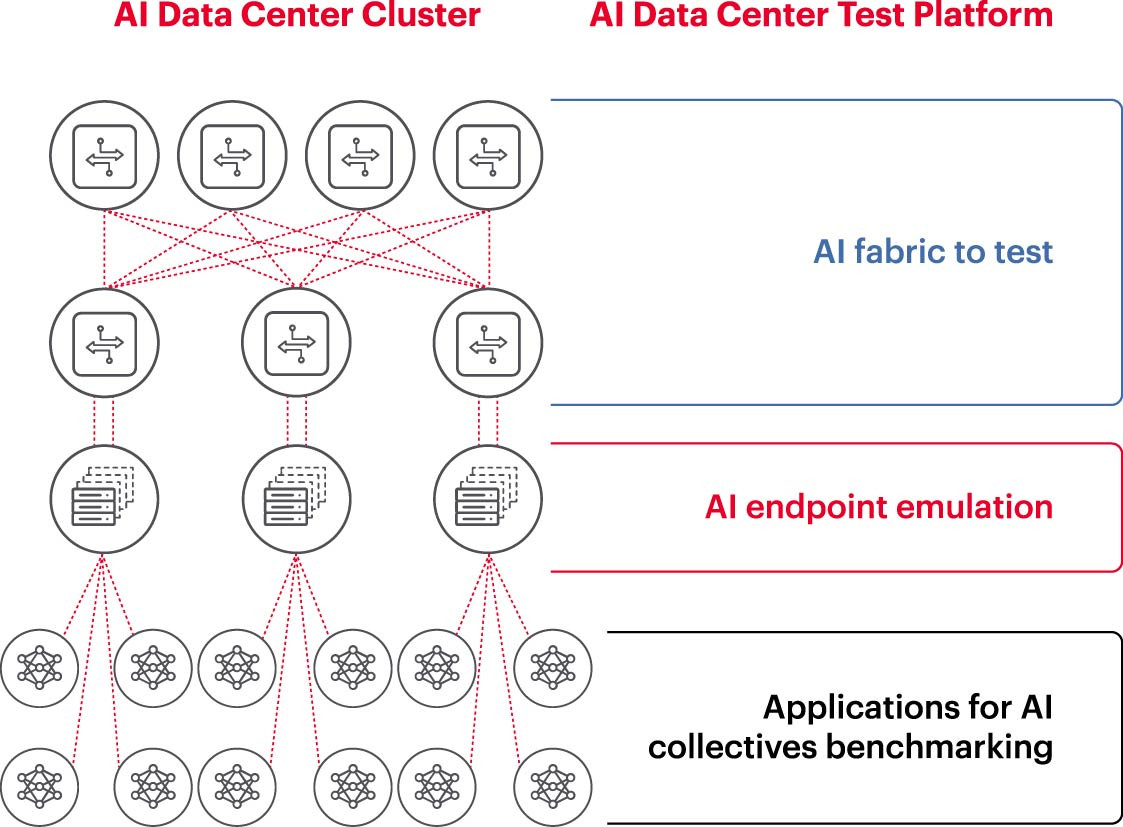
Dette skaper mange utfordringer i måling av AI-nettverk:
– Vanskeligheter med å reprodusere hele produksjonsnettverk i laboratoriet på grunn av begrensninger i kostnader, utstyr, mangel på dyktige nettverks-AI-ingeniører, plass, strøm og temperatur.
- Måling på produksjonssystemet reduserer den tilgjengelige prosesseringskapasiteten til selve produksjonssystemet.
- Vanskeligheter med å gjengi problemene nøyaktig på grunn av forskjeller i omfang og omfang av problemene.
– Kompleksiteten i hvordan GPU-er er samlet koblet sammen.
For å håndtere disse utfordringene kan bedrifter teste et delsett av de anbefalte oppsettene i et laboratoriemiljø for å sammenligne viktige målinger som fullføringstid for jobber (JCT), båndbredden AI-teamet kan oppnå, og sammenligne det med utnyttelse av svitsjeplattformer og hurtigbufferutnyttelse. Denne referansemålingen bidrar til å finne den rette balansen mellom GPU-/prosessorarbeidsbelastning og nettverksdesign/-oppsett. Når de er fornøyde med resultatene, kan dataarkitektene og nettverksingeniørene ta disse oppsettene til produksjon og måle nye resultater.
Bedriftsforskningslaboratorier, akademiske institusjoner og universiteter jobber med å analysere alle aspekter ved å bygge og drifte effektive AI-nettverk for å møte utfordringene ved å jobbe i store nettverk, spesielt ettersom beste praksis fortsetter å utvikle seg. Denne samarbeidende, repeterbare tilnærmingen er den eneste måten for bedrifter å utføre repeterbare målinger og raskt teste "hva hvis"-scenarier som er grunnlaget for å optimalisere nettverk for AI.
(Kilde: Keysight Technologies)
[annonse_2]
Kilde: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html
![[Foto] Avslutning av den 14. konferansen til den 13. sentralkomiteen i partiet](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/06/1762404919012_a1-bnd-5975-5183-jpg.webp)
![[Foto] Statsminister Pham Minh Chinh mottar delegasjonen fra Semiconductor Manufacturing International (SEMI)](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/06/1762434628831_dsc-0219-jpg.webp)















![[Video] Den tredje nasjonale presseprisen «For utviklingen av vietnamesisk kultur»](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/11/06/1762444834490_giai-bao-chi-vh-3937-jpg.webp)


























































































Kommentar (0)