Procesory graficzne są mózgami komputerów AI.
Mówiąc prościej, jednostka przetwarzania grafiki (GPU) działa jak mózg komputera AI.
Jak zapewne wiesz, jednostka centralna (CPU) to mózg komputera. Zaletą GPU jest to, że jest to wyspecjalizowany procesor do wykonywania złożonych obliczeń. Najszybszym sposobem na ich wykonanie jest wspólne rozwiązywanie problemu przez grupy GPU. Mimo to, wytrenowanie modelu sztucznej inteligencji (AI) może zająć tygodnie, a nawet miesiące. Po zbudowaniu jest on umieszczany w systemie komputerowym front-end, a użytkownicy mogą zadawać pytania modelowi AI; ten proces nazywa się wnioskowaniem.
Komputer AI zawiera wiele procesorów GPU.
Najlepszą architekturą rozwiązywania problemów związanych ze sztuczną inteligencją jest wykorzystanie grupy procesorów GPU w szafie rack, podłączonych do przełącznika na szczycie szafy. Wiele szaf GPU można dodatkowo połączyć w hierarchiczny system łączności sieciowej. Wraz ze wzrostem złożoności problemów do rozwiązania rosną również wymagania dotyczące procesorów GPU, a niektóre projekty potencjalnie wymagają wdrożenia klastrów składających się z tysięcy procesorów GPU.
Każdy klaster AI jest małą siecią.
Podczas tworzenia klastra AI konieczne jest utworzenie niewielkiej sieci komputerowej, która połączy procesory graficzne i umożliwi im efektywną współpracę oraz udostępnianie danych.
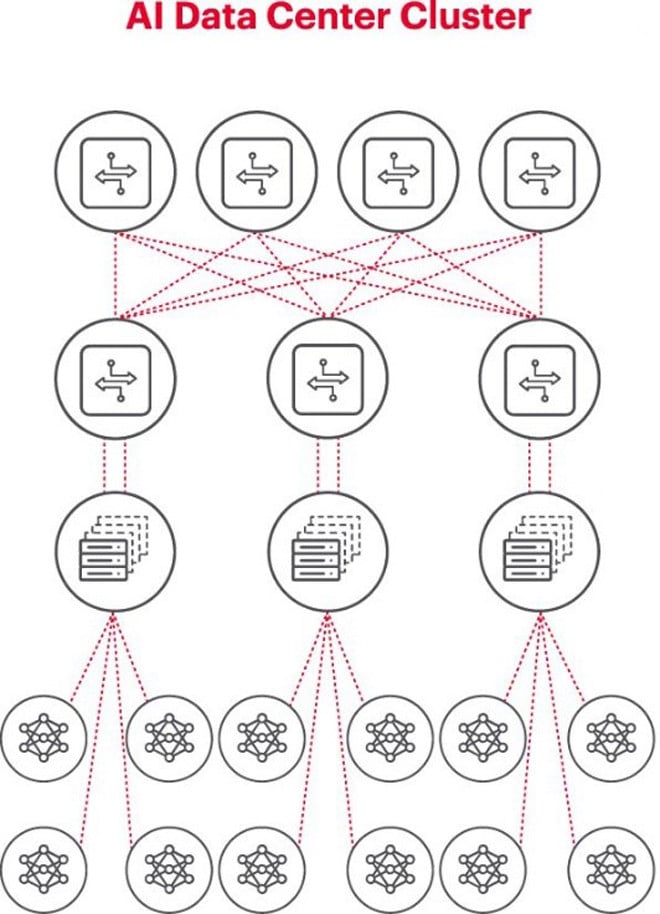
Powyższy diagram ilustruje klaster AI, w którym kółka u dołu reprezentują przepływy pracy realizowane na procesorach GPU. Procesory GPU łączą się z przełącznikami w górnej szafie (ToR). Przełączniki ToR łączą się również z przełącznikami szkieletowymi sieci przedstawionymi na powyższym diagramie, demonstrując przejrzystą hierarchię sieci niezbędną w przypadku użycia wielu procesorów GPU.



Sieci stanowią wąskie gardło we wdrażaniu sztucznej inteligencji.
Jesienią ubiegłego roku, podczas światowego szczytu Open Computer Project (OCP), na którym delegaci pracowali nad budową infrastruktury sztucznej inteligencji nowej generacji, delegat Loi Nguyen z Marvell Technology zwrócił uwagę na kluczową kwestię: „sieci są nowym wąskim gardłem”.
Z technicznego punktu widzenia, wysokie opóźnienie pakietów lub ich utrata spowodowana przeciążeniem sieci może powodować ponowne wysyłanie pakietów, co znacznie wydłuża czas realizacji zadania (JCT). W rezultacie, warte miliony, a nawet dziesiątki milionów dolarów procesory graficzne należące do firm marnują się z powodu nieefektywnych systemów AI, co negatywnie wpływa na firmy zarówno pod względem przychodów, jak i czasu wprowadzania produktów na rynek.
Testowanie i pomiary są kluczowymi warunkami pomyślnego działania sieci AI.
Aby klaster AI mógł sprawnie funkcjonować, procesory graficzne (GPU) muszą być w stanie w pełni wykorzystać swoją moc, skracając czas szkolenia i wdrażając modele uczenia się, maksymalizując zwrot z inwestycji. Dlatego konieczne jest testowanie i ocena wydajności klastra AI (rysunek 2). Zadanie to nie jest jednak łatwe, ponieważ architektura systemu obejmuje wiele ustawień i relacji między procesorem graficznym a strukturą sieci, które muszą się wzajemnie uzupełniać, aby rozwiązać problem.
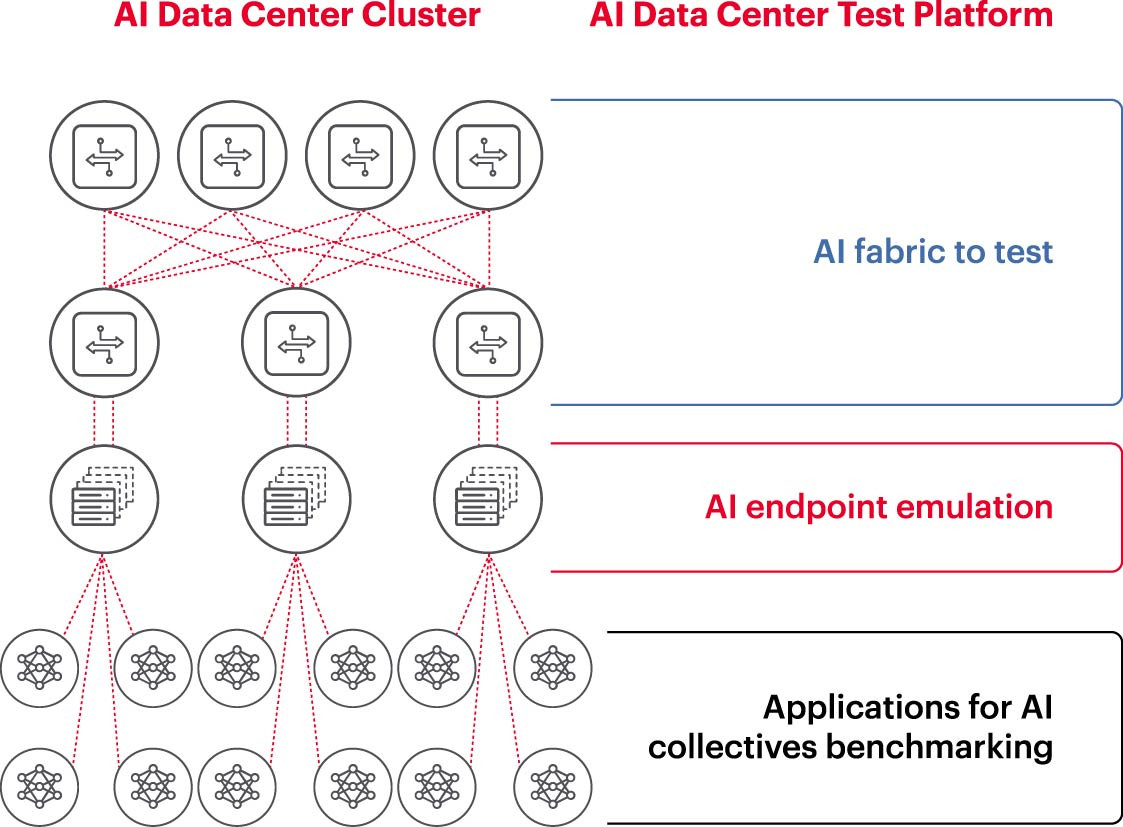
Stwarza to wiele trudności i wyzwań w pomiarze sieci AI:
- Wyzwaniem w powieleniu całej sieci produkcyjnej w laboratorium są ograniczenia dotyczące kosztów, sprzętu, niedoboru wysoko wykwalifikowanych inżynierów sieciowych AI, przestrzeni, zasilania i temperatury.
- Testowanie w systemie produkcyjnym zmniejsza dostępną moc obliczeniową samego systemu produkcyjnego.
- Trudności w dokładnym odtworzeniu problemów ze względu na różnice w skali i zakresie problemów.



- Złożoność łączenia się ze sobą układów GPU.
Aby sprostać tym wyzwaniom, firmy mogą przeprowadzić testy porównawcze podzbioru proponowanych konfiguracji w środowisku laboratoryjnym, aby porównać kluczowe parametry, takie jak JCT (czas wykonania zadania), przepustowość osiągalną przez zespół AI, oraz porównać je z wykorzystaniem platformy przełączającej i pamięci podręcznej. Takie testy porównawcze pomagają znaleźć właściwą równowagę między obciążeniem procesora graficznego (GPU) a projektem/instalacją sieci. Po uzyskaniu satysfakcjonujących rezultatów, architekci komputerowi i inżynierowie sieciowi mogą wdrożyć te konfiguracje w środowisku produkcyjnym i zmierzyć nowe rezultaty.
Przedsiębiorstwa, laboratoria badawcze, instytuty badawcze i uniwersytety pracują nad analizą każdego aspektu budowy i obsługi efektywnych sieci AI, aby sprostać wyzwaniom związanym z pracą w dużych sieciach, zwłaszcza w obliczu ciągłych zmian w najlepszych praktykach. To powtarzalne podejście oparte na współpracy to jedyny sposób, w jaki firmy mogą wykonywać powtarzalne pomiary i szybko testować scenariusze „jeśli-to” – co jest kluczowe dla optymalizacji sieci opartych na AI.
(Źródło: Keysight Technologies)
Źródło: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html


![[Grafika] Konferencja krajowa podsumowująca rok funkcjonowania całościowego modelu organizacyjnego systemu politycznego, trójstopniowego modelu rządu.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/07/01/1782882811691_ndo_br_1-jpg.webp)