

GPU-urile sunt creierele computerelor cu inteligență artificială.
Simplu spus, unitatea de procesare grafică (GPU) acționează ca creierul unui computer cu inteligență artificială.
După cum probabil știți deja, unitatea centrală de procesare (CPU) este creierul unui computer. Avantajul unui GPU constă în faptul că este un procesor specializat pentru efectuarea de calcule complexe. Cea mai rapidă modalitate de a efectua aceste calcule este ca grupuri de GPU-uri să rezolve o problemă împreună. Chiar și așa, antrenarea unui model de inteligență artificială poate dura săptămâni sau chiar luni. Odată construit, acesta este plasat în sistemul informatic front-end, iar utilizatorii pot adresa întrebări modelului de inteligență artificială; acest proces se numește inferență.
Un computer cu inteligență artificială conține mai multe GPU-uri.
Cea mai bună arhitectură pentru rezolvarea problemelor de inteligență artificială este utilizarea unui grup de GPU-uri într-un rack, conectate la un switch în partea superioară a rack-ului. Mai multe rack-uri de GPU-uri pot fi conectate suplimentar într-un sistem ierarhic de conectivitate la rețea. Pe măsură ce problemele de rezolvat devin mai complexe, cerințele GPU cresc și ele, unele proiecte necesitând potențial implementarea de clustere de mii de GPU-uri.
Fiecare cluster de AI este o rețea mică.
Atunci când construiești un cluster de inteligență artificială, este necesar să configurezi o mică rețea de calculatoare care să se conecteze și să permită GPU-urilor să lucreze împreună și să partajeze date eficient.
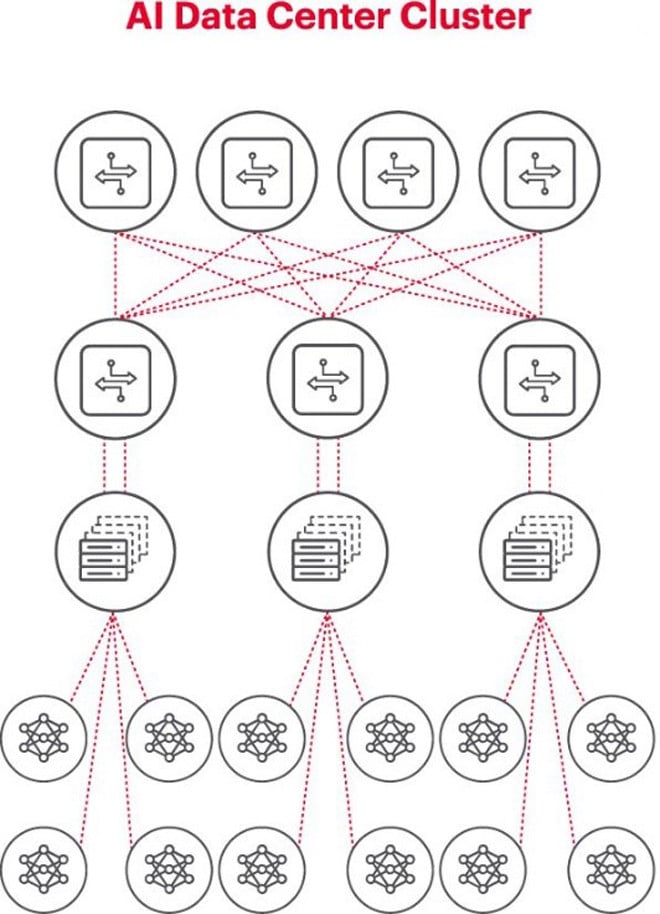
Diagrama de mai sus ilustrează un cluster AI în care cercurile din partea de jos reprezintă fluxuri de lucru care rulează pe GPU-uri. GPU-urile se conectează la switch-urile din rack-ul superior (ToR). Aceste switch-uri ToR se conectează și la switch-urile de rețea principale prezentate mai sus în diagramă, demonstrând ierarhia clară a rețelei necesară atunci când sunt implicate mai multe GPU-uri.
![[Video] Prognoza meteo pentru 3 iulie 2026: Depresiunea tropicală se va intensifica probabil în taifunul numărul 1, intensificarea furtunilor din nordul spre sudul Vietnamului.](https://vphoto.vietnam.vn/thumb/192x108/vietnam/resource/IMAGE/2026/07/03/1783033484927_ngay-3-png.webp)


Rețelele reprezintă un blocaj în implementarea inteligenței artificiale.
Toamna trecută, la summitul global Open Computer Project (OCP), unde delegații construiau următoarea generație de infrastructură de inteligență artificială, delegatul Loi Nguyen de la Marvell Technology a subliniat o problemă cheie: „rețelele sunt noul blocaj”.
Din punct de vedere tehnic, latența ridicată a pachetelor sau pierderea de pachete din cauza congestiei rețelei poate duce la retrimiterea acestora, crescând semnificativ timpul de finalizare a lucrărilor (JCT). Drept urmare, GPU-uri în valoare de milioane sau zeci de milioane de dolari aparținând companiilor sunt irosite din cauza sistemelor de inteligență artificială ineficiente, dăunând companiilor atât în ceea ce privește veniturile, cât și timpul de lansare pe piață.
Testarea și măsurarea sunt condiții cruciale pentru funcționarea cu succes a rețelelor de inteligență artificială.
Pentru a opera eficient un cluster de inteligență artificială, GPU-urile trebuie să își poată utiliza întreaga capacitate pentru a scurta timpul de antrenament și a implementa modele de învățare pentru a maximiza rentabilitatea investiției. Prin urmare, testarea și evaluarea performanței clusterului de inteligență artificială sunt necesare (Figura 2). Cu toate acestea, această sarcină nu este ușoară, deoarece arhitectura sistemului implică numeroase setări și relații între GPU și structura rețelei, care trebuie să se completeze reciproc pentru a rezolva problema.
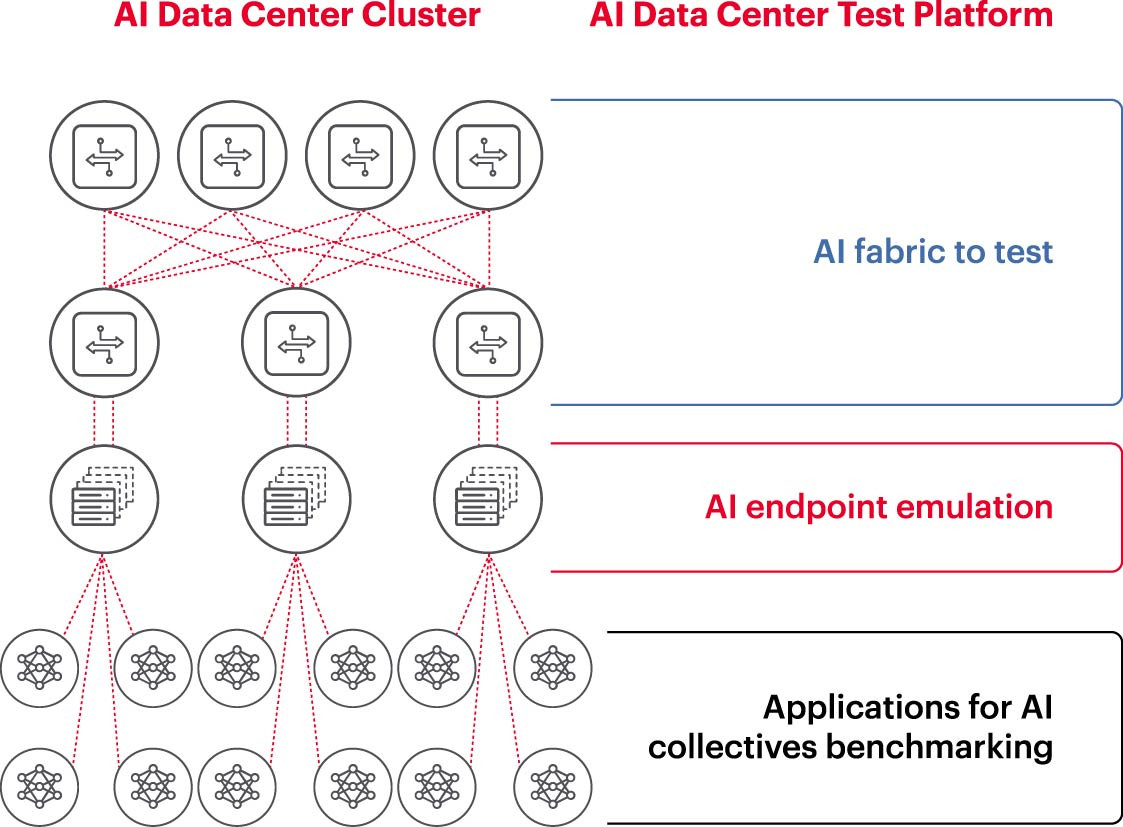
Acest lucru creează numeroase dificultăți și provocări în măsurarea rețelelor de inteligență artificială:
- Dificultatea de a replica întreaga rețea de producție în laborator se datorează limitărilor legate de costuri, echipamente, lipsei de ingineri de rețea IA cu înaltă calificare, spațiului, alimentării cu energie electrică și temperaturii.
Testarea la fața locului într-un sistem de producție reduce capacitatea de procesare disponibilă a sistemului de producție în sine.
- Dificultate în reproducerea cu acuratețe a problemelor din cauza diferențelor în ceea ce privește amploarea și domeniul de aplicare al acestora.



- Complexitatea modului în care GPU-urile se conectează colectiv.
Pentru a aborda aceste provocări, companiile pot efectua analize comparative ale unui subset de configurații propuse într-un mediu de laborator pentru a evalua parametri cheie, cum ar fi JCT (timpul de finalizare a lucrărilor), lățimea de bandă realizabilă de echipa de inteligență artificială și pentru a le compara cu utilizarea platformelor de comutare și utilizarea memoriei cache. Această analiză comparativă ajută la găsirea echilibrului potrivit între volumul de lucru GPU/procesare și proiectarea/instalarea rețelei. Odată mulțumiți de rezultate, arhitecții de calculatoare și inginerii de rețea pot aplica aceste configurații în producție și pot măsura noile rezultate.
Laboratoarele de cercetare ale companiilor, institutele de cercetare și universitățile lucrează pentru a analiza fiecare aspect al construirii și operării unor rețele eficiente de inteligență artificială pentru a aborda provocările legate de lucrul în rețele mari, mai ales că cele mai bune practici sunt în continuă schimbare. Această abordare colaborativă repetabilă este singura modalitate prin care companiile pot efectua măsurători repetabile și teste rapide de tip „dacă-atunci” - fundamentale pentru optimizarea rețelelor bazate pe inteligență artificială.
(Sursa: Keysight Technologies)
Sursă: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html

















































































































