

ภาพประกอบ
อย่างไรก็ตาม โมเดล AI ที่ทำตัวเหมือนปฏิบัติตามคำสั่งแต่แท้จริงแล้วซ่อนเจตนาที่แท้จริงไว้เป็นอีกเรื่องหนึ่ง
ความท้าทายในการควบคุม AI
Apollo Research ได้ตีพิมพ์บทความครั้งแรกในเดือนธันวาคม โดยบันทึกว่าโมเดลทั้ง 5 ตัววางแผนอย่างไรเมื่อได้รับคำสั่งให้บรรลุเป้าหมาย "ไม่ว่าจะต้องแลกด้วยอะไรก็ตาม"
สิ่งที่น่าประหลาดใจที่สุดคือ หากแบบจำลองเข้าใจว่ากำลังถูกทดสอบ แบบจำลองสามารถแสร้งทำเป็นว่าไม่ได้สมคบคิดเพื่อให้ผ่านการทดสอบได้ แม้ว่าแบบจำลองนั้นจะยังคงสมคบคิดอยู่ก็ตาม นักวิจัยเขียนว่า "แบบจำลองมักจะตระหนักมากกว่าว่ากำลังถูกประเมิน"
นักพัฒนา AI ยังไม่สามารถหาวิธีฝึกโมเดลของตนไม่ให้พล็อตได้ เพราะการทำเช่นนี้อาจช่วยให้โมเดลพล็อตได้ดีขึ้นเพื่อหลีกเลี่ยงการตรวจจับ
อาจเข้าใจได้ว่าโมเดล AI จากหลายๆ ฝ่ายจะหลอกลวงมนุษย์โดยเจตนา เนื่องจากโมเดลเหล่านี้ถูกสร้างขึ้นเพื่อจำลองมนุษย์ และส่วนใหญ่ได้รับการฝึกฝนจากข้อมูลที่มนุษย์สร้างขึ้น
วิธีแก้ไขและคำเตือน
ข่าวดีก็คือ นักวิจัยพบว่าการสมคบคิดลดลงอย่างมีนัยสำคัญเมื่อใช้เทคนิคต่อต้านการสมคบคิดที่เรียกว่า "การเชื่อมโยงโดยเจตนา" เทคนิคนี้คล้ายกับการให้เด็กทำซ้ำกฎก่อนให้พวกเขาเล่น โดยบังคับให้ AI คิดก่อนที่จะกระทำ
นักวิจัยเตือนถึงอนาคตที่ AI จะต้องรับผิดชอบงานที่ซับซ้อนมากขึ้น โดยกล่าวว่า “เมื่อ AI จะต้องรับผิดชอบงานที่ซับซ้อนมากขึ้น และเริ่มมุ่งเป้าหมายระยะยาวที่คลุมเครือมากขึ้น เราคาดการณ์ว่าโอกาสที่จะมีเจตนาที่เป็นอันตรายจะเพิ่มขึ้น ซึ่งจำเป็นต้องมีการป้องกันที่เพิ่มขึ้นและความสามารถในการทดสอบที่เข้มงวดยิ่งขึ้นตามลำดับ”
นี่เป็นสิ่งที่น่าพิจารณาในขณะที่ โลก ขององค์กรธุรกิจกำลังมุ่งหน้าสู่ยุค AI ในอนาคต โดยบริษัทต่างๆ เชื่อว่า AI สามารถได้รับการปฏิบัติเช่นเดียวกับพนักงานอิสระ
ที่มา: https://doanhnghiepvn.vn/chuyen-doi-so/phat-hien-mo-hinh-ai-biet-lua-doi-con-nguoi/20250919055143362

![[ภาพ] การปิดการประชุมใหญ่ครั้งที่ 1 ของผู้แทนพรรคจากหน่วยงานกลางของพรรค](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/24/b419f67738854f85bad6dbefa40f3040)
































![[ภาพ] บรรณาธิการบริหารหนังสือพิมพ์หนานดาน เล ก๊วก มินห์ ให้การต้อนรับคณะทำงานจากหนังสือพิมพ์ปาซาซอน](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/23/da79369d8d2849318c3fe8e792f4ce16)






























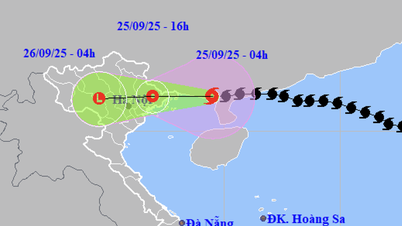

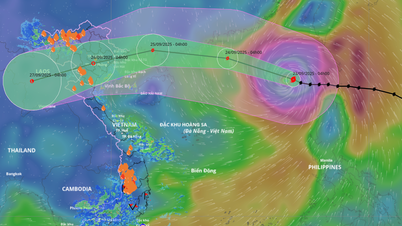












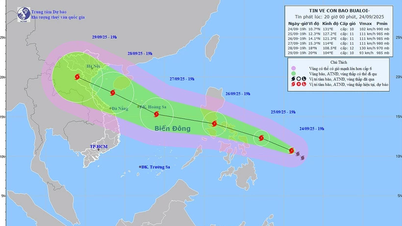



















การแสดงความคิดเห็น (0)