
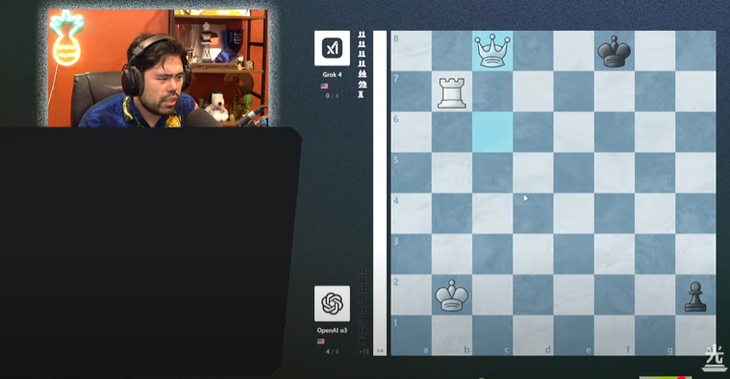
Гравець Накамура сказав, що Grok 4, схоже, грав у напруженому настрої у фінальному матчі - Фото: скріншот
Перед матчем OpenAI наробила галасу, оголосивши про запуск 11-го покоління LLM, GPT-5.
Однак, модель o3 - ChatGPT, яка використовувалася у фіналі, все ще демонструвала сильні можливості логічного висновку, із середнім показником правильних переміщень до 90,8%, що повністю перевершує 80,2% у Grok 4.
У всіх чотирьох іграх ChatGPT не дав Гроку 4 жодного шансу, поставивши мат супернику після 35, 30, 28 та 54 ходів відповідно.
За словами другого ракетки світу Хікару Накамури, команда Grok 4, здавалося, грала з більшою напругою та робила більше помилок, ніж у попередніх раундах. Зокрема, вона легко втрачала фігури – рідкісний випадок, коли вона переконливо перемогла Gemini 2.5 Flash та Gemini 2.5 Pro від Google.
З трьома перемогами поспіль з рахунком 4-0 та середнім показником точності до 91%, o3 ідеально завершили турнір.
Хоча силу o3 не можна порівняти з професійними гросмейстерами, її достатньо, щоб створити проблеми гравцям з ЕЛО нижче 2000. Особливо в бліц- та супербліц-категоріях.
Турнір, організований Google, завершився абсолютною домінацією американських представників. У той час як дві китайські моделі, Kimi K4 та DeepSeek, вибули достроково, матч за третє місце виграла Gemini 2.5 Pro над o4-mini, що закріпило позицію провідних американських технологічних компаній.
Ця подія не лише демонструє дивовижні можливості моделей штучного інтелекту загального призначення у спеціалізованій галузі. Вона також відкриває нову перспективу щодо потенціалу розвитку штучного інтелекту в майбутньому.
Однак, це також нагадування про те, що хоча LLM стрімко розвиваються, вони все ще не можуть зрівнятися з рівнем професійних шахових двигунів, чиї рейтинги Ело значно перевищують людські.
Джерело: https://tuoitre.vn/chatgpt-dang-quang-giai-co-vua-danh-cho-ai-20250808090405997.htm
![[Фото] Прем'єр-міністр Фам Мінь Чінь відвідав 5-ту церемонію вручення Національної премії преси, присвячену запобіганню та боротьбі з корупцією, марнотратством та негативом](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/31/1761881588160_dsc-8359-jpg.webp)


![[Фото] Дананг: Вода поступово відступає, місцева влада користується очищенням](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/31/1761897188943_ndo_tr_2-jpg.webp)





































































































Коментар (0)