
ویتنام میں ڈیجیٹل تبدیلی اور مصنوعی ذہانت (AI) کی تبدیلی کے تناظر میں، OCR ٹیکنالوجی (آپٹیکل کریکٹر ریکگنیشن) دستاویزات کو ڈیجیٹائز کرنے، کاروباری عمل کو خودکار بنانے، اخراجات کو بچانے اور انتظامی کارکردگی کو بہتر بنانے میں تیزی سے اہم کردار ادا کرتی ہے۔ تاہم، لہجے اور لکھاوٹ کے ساتھ ویتنامی کی خصوصیات کے ساتھ، شناخت کا مسئلہ 'الفاظ کو پڑھنے' پر نہیں رکتا، بلکہ اس کے لیے ماڈل کی ضرورت ہوتی ہے کہ وہ سیاق و سباق کو جامع طور پر سمجھنے کی صلاحیت رکھتا ہو۔
حال ہی میں، CMC ٹیکنالوجی ایپلی کیشن انسٹی ٹیوٹ (CMC ATI) نے CATI-VLM (Visual Document Understanding) ماڈل کا اعلان کیا ہے جسے ریسرچ ٹیم نے 5TB بڑے ڈیٹا گودام سے تیار کیا ہے، جو جون میں Robust Reading Competition (RRC) کے ذریعہ اعلان کردہ درجہ بندی میں دنیا میں ٹاپ 12 اور ویتنام میں ٹاپ 1 تک پہنچ گیا ہے۔ (DocVQA) زمرہ۔
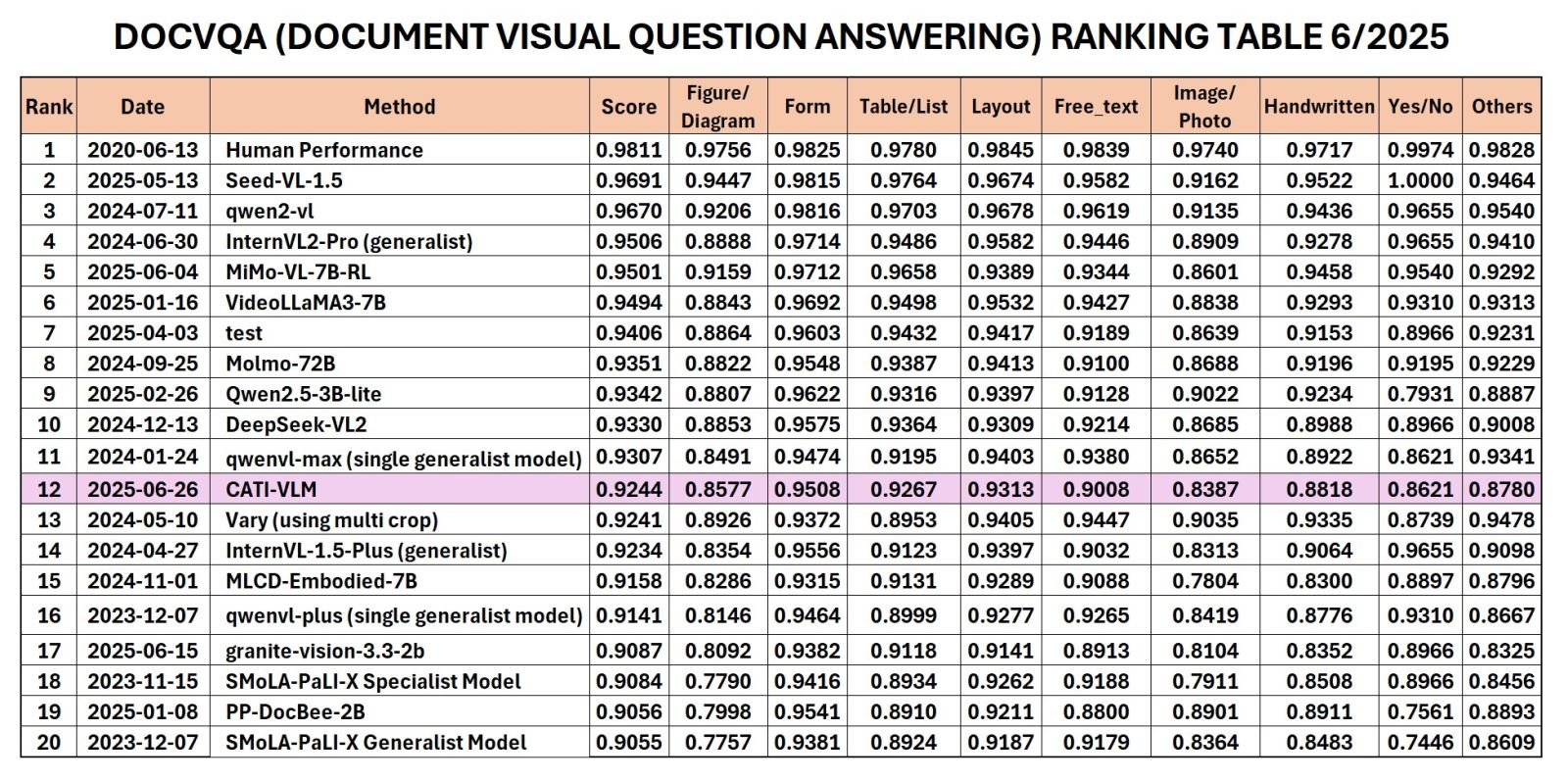
DocVQA زمرہ 6/2025 میں RRC کی درجہ بندی۔
Robust Reading Competition (RRC) ایک باوقار سائنسی کھیل کا میدان ہے، (https://rrc.cvc.uab.es/) جس کا اہتمام کمپیوٹر ویژن سینٹر (CVC) Universitat Autònoma de Barcelona (UAB) اسپین کے ذریعے کیا گیا ہے، جو کمپیوٹر ویژن کے میدان میں دنیا میں ایک باوقار تحقیقی مرکز ہے۔ 2011 میں شروع کیا گیا، ہمیشہ متن کے تجزیہ اور شناخت پر بین الاقوامی کانفرنس ICDAR کے ساتھ - دستاویز کے تجزیہ اور کمپیوٹر وژن پر دنیا کے سب سے بڑے فورمز میں سے ایک، مقابلہ ایک اہم ایونٹ بن گیا ہے، جس میں محققین، ممتاز یونیورسٹیوں کے انجینئرز، ریسرچ انسٹی ٹیوٹ اور ٹیکنالوجی کمپنیاں شامل ہیں جیسے Tsinghua's ٹاسک، Hyunden Groups، Hyunden Groups اور Hyunden Groups ڈیزائن. تکنیکی ترقی کو فروغ دینے کے لیے، ترجمے سے لے کر عملی مسائل سے قریب سے جڑے ہوئے، انٹرپرائز ڈیٹا مینجمنٹ سے لے کر شہری تجزیہ اور تاریخی دستاویز پراسیسنگ تک۔
CMC ATI کے ڈائریکٹر ڈاکٹر ڈانگ من ٹوان نے کہا: "CMC ٹیم کی تحقیقی صلاحیت کی تصدیق RRC جیسے باوقار عالمی کھیل کے میدان کے ذریعے کی گئی ہے۔ ہمیں فخر ہے کہ بہت کم وقت میں، ٹیم ترقی یافتہ ممالک کے بڑے ناموں کے ساتھ کندھے سے کندھا ملا کر ایک اعلیٰ درجہ بندی حاصل کر سکتی ہے۔ مزید اہم بات یہ ہے کہ یہ ویتنام کے مخصوص شعبے میں مخصوص مسائل کو حل کرنے کی مہارت اور ٹیکنالوجی کی مہارت کا واضح مظاہرہ ہے۔ ویتنام۔"
CATI-VLM روایتی OCR سے اس لحاظ سے مختلف ہے کہ یہ نہ صرف حروف کو نکالتا ہے، بلکہ معلومات کی متعدد پرتوں کو بھی سمجھتا ہے: متن کا مواد، غیر متنی عناصر (ٹک باکس، چیک باکس، چارٹ، دستخط، فارمولے)، لے آؤٹ (صفحہ کا ڈھانچہ، میزیں، فارم) اور طرز (فونٹس، ہائی لائٹس، وغیرہ)۔ ماڈل ChatGPT کی طرح دستاویز کی تصاویر پر پوچھے گئے بصری سوالات کا جواب دے سکتا ہے، بغیر کسی مخصوص فارم کو پہلے سے سیکھے۔
نیوز اور عوام اخبار کے مطابق
ماخذ: https://doanhnghiepvn.vn/cong-nghe/ai-loi-make-in-vietnam-duoc-xep-hang-top-12-the-gioi/20250703100726051
![[تصویر] ویتنام ایسوسی ایشن آف فوٹوگرافک آرٹسٹ کے قیام کی 60 ویں سالگرہ](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F12%2F05%2F1764935864512_a1-bnd-0841-9740-jpg.webp&w=3840&q=75)
![[تصویر] قومی اسمبلی کے چیئرمین ٹران تھان مین ون فیوچر 2025 ایوارڈ کی تقریب میں شرکت کر رہے ہیں](/_next/image?url=https%3A%2F%2Fvphoto.vietnam.vn%2Fthumb%2F1200x675%2Fvietnam%2Fresource%2FIMAGE%2F2025%2F12%2F05%2F1764951162416_2628509768338816493-6995-jpg.webp&w=3840&q=75)











































































































تبصرہ (0)