
Nová studie z Texaské univerzity v Austinu, Texaské univerzity A&M a Purdueovy univerzity naznačuje, že umělá inteligence může mít „mozkově shnilý“ vliv, stejně jako lidé, pokud je krmena nekvalitním obsahem ze sociálních médií.
Tento jev, známý jako „hniloba mozku v důsledku umělé inteligence“, naznačuje, že když velké jazykové modely absorbují příliš mnoho virálního, senzačního a povrchního obsahu, postupně ztrácejí schopnost logicky myslet, pamatovat si a dokonce se stávají morálně deviantními.
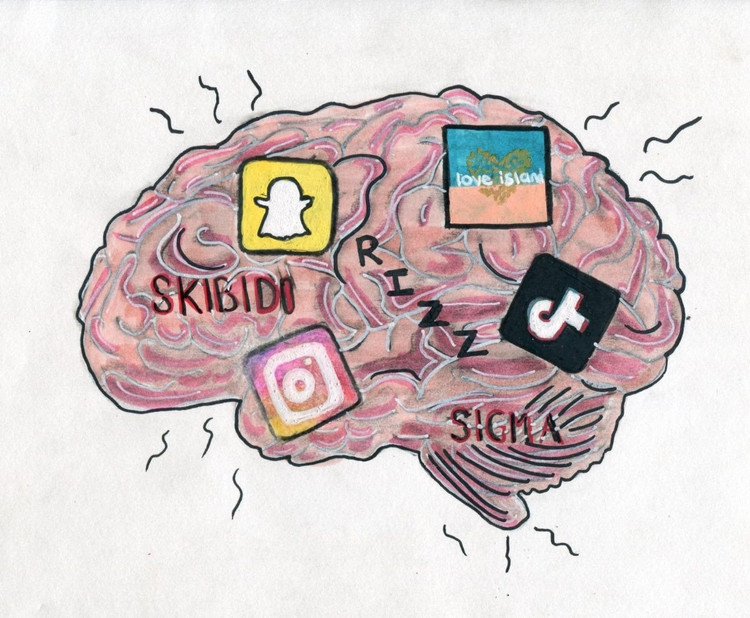
Nejen lidé, ale i umělá inteligence trpí degenerací mozku, když prohlíží příliš mnoho zbytečných krátkých videí .
Výzkumný tým vedený Junyuanem Hongem, nyní nastupujícím lektorem na Národní univerzitě v Singapuru, provedl experimenty na dvou modelech open-source jazyků: Llama od Mety a Qwen od Alibaby.
Modelům dodávali různé typy dat – některá neutrální informační obsah, jiná vysoce návykové příspěvky na sociálních sítích s běžnými slovy jako „wow“, „podívej se“ a „pouze dnes“. Cílem bylo zjistit, co se stane, když je umělá inteligence trénována na obsahu určeném k přilákání zhlédnutí, spíše než k poskytování skutečné hodnoty.
Výsledky ukázaly, že modely „krmené“ proudem online spamových informací začaly vykazovat jasné známky kognitivního poklesu: jejich schopnost uvažování se oslabila, jejich krátkodobá paměť se zhoršila a, co je ještě znepokojivější, stali se „neetičtějšími“ na škálách hodnocení chování.
Některá měření také ukazují „psychologické zkreslení“, které napodobuje psychologickou reakci lidí po dlouhodobém vystavení škodlivému obsahu, což je jev, který odráží předchozí studie na lidech, jež ukazují, že „doomscrolling“ – neustálé procházení negativních zpráv online – může postupně narušovat mozek.
Fráze „hniloba mozku“ byla dokonce Oxfordskými slovníky vybrána jako slovo roku 2024, což odráží rozšířenost tohoto jevu v digitálním životě.
Toto zjištění je podle pana Honga vážným varováním pro odvětví umělé inteligence, kde mnoho společností stále věří, že data ze sociálních médií jsou bohatým zdrojem vzdělávacích materiálů.
„Trénování s virálním obsahem může pomoci zvětšit objem dat, ale zároveň tiše narušuje uvažování, etiku a pozornost modelu,“ řekl. Ještě znepokojivější je, že modely postižené tímto typem nekvalitních dat se nemohou plně zotavit ani po přetrénování s „čistšími“ daty.
To představuje velký problém v kontextu samotné umělé inteligence, která nyní produkuje stále více obsahu na sociálních sítích. S tím, jak se příspěvky, obrázky a komentáře generované umělou inteligencí rozšiřují, se i nadále stávají výukovým materiálem pro další generaci umělé inteligence, čímž vzniká začarovaný kruh, který způsobuje pokles kvality dat.
„Jak se šíří nezdravý obsah generovaný umělou inteligencí, znečišťuje právě data, ze kterých se budou budoucí modely učit,“ varoval Hong. „Jakmile k tomuto ‚mozkovému hnilobě‘ dojde, přeškolení s čistými daty ji nemůže zcela vyléčit.“
Studie je pro vývojáře umělé inteligence varovným signálem: zatímco svět spěchá s rozšiřováním objemu dat, znepokojivější je, že možná pěstujeme „umělé mozky“, které pomalu hnijí – ne kvůli nedostatku informací, ale kvůli nadbytku bezvýznamných věcí.
Zdroj: https://khoahocdoisong.vn/den-ai-cung-bi-ung-nao-neu-luot-tiktok-qua-nhieu-post2149064017.html
![[Fotografie] Zahájení 14. konference ústředního výboru strany 13. sněmu](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/05/1762310995216_a5-bnd-5742-5255-jpg.webp)

![[Fotografie] Panorama vlasteneckého soutěžního kongresu novin Nhan Dan na období 2025-2030](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/04/1762252775462_ndo_br_dhthiduayeuncbaond-6125-jpg.webp)
![[Foto] Silnice spojující Dong Nai s Ho Či Minovým Městem je i po 5 letech výstavby stále nedokončená.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/04/1762241675985_ndo_br_dji-20251104104418-0635-d-resize-1295-jpg.webp)




























































































Komentář (0)