

China's leading technology company Tencent has just announced a new artificial intelligence model, capable of creating videos simulating movement in three-dimensional space with just a single input image.

Called HunyuanWorld-Voyager, the system generates short clips containing depth information, which can then be reconstructed into a 3D dot matrix – opening up new possibilities for content creators, though it falls short of fully interacting with 3D models.
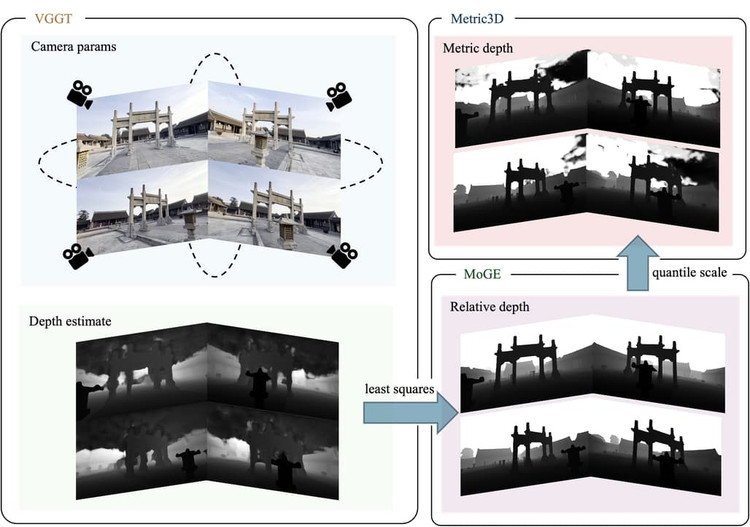
HunyuanWorld-Voyager is an open-weighted model that generates sequences of 49 frames—about two seconds of video—but users can link clips together to create multiple minutes of continuous footage.
Ars Technica notes that as the viewer changes the virtual camera's perspective, objects maintain their relative positions, and the environment acts as if it were fully three-dimensional. While the final output is still two-dimensional video, Tencent says the accompanying depth data allows for 3D reconstruction without the need for traditional modeling techniques.

Voyager works by combining input images with user-defined camera paths. Users specify movements like panning, tilting, or moving through the scene, and the system simultaneously generates color video and a depth map. When an object appears in the video, the output depth data records its relative distance to the correct location.
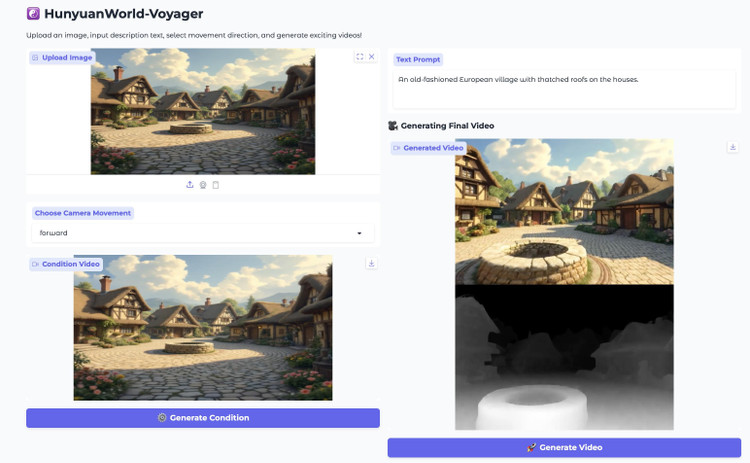
A secondary component, called world cache in Tencent's technical paper, stores 3D point clouds as the system generates new frames.

With each camera move, Voyager projects these points back into two dimensions and uses them as a reference. This process ensures that subsequent frames match the previously generated content, helping to maintain spatial consistency.
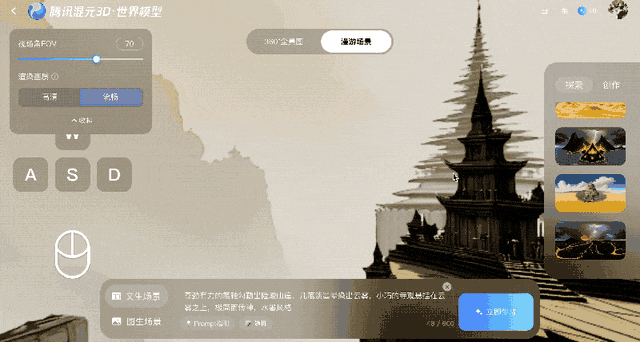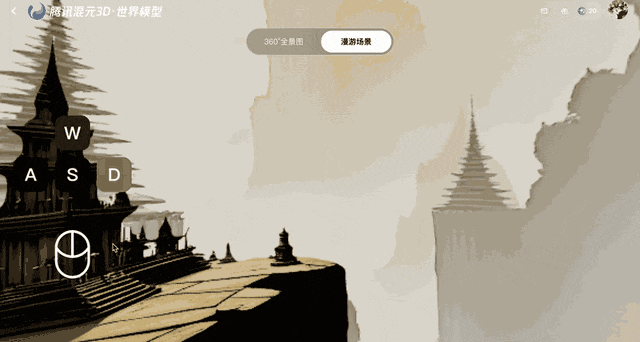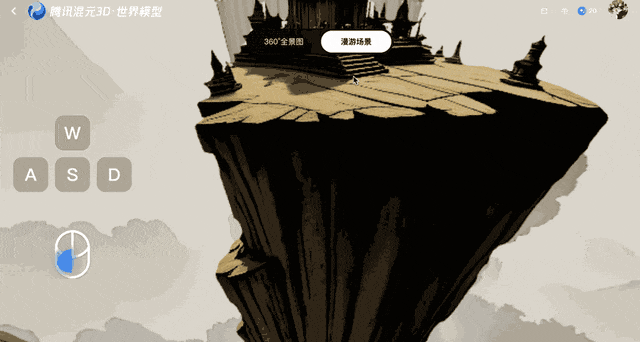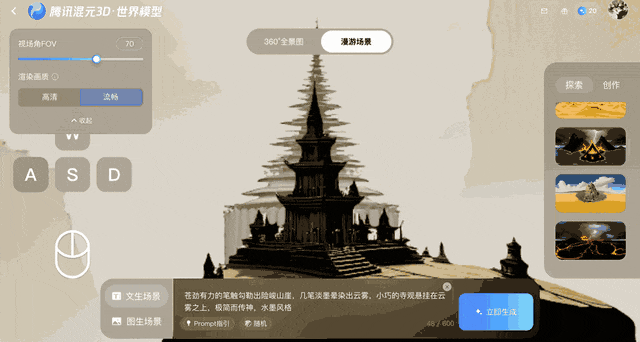
This model protects against distortion after the frames are created by converting them to 3D points, which are then fed back to the system for comparison. This feedback loop ensures geometric stability, even though errors accumulate over time.
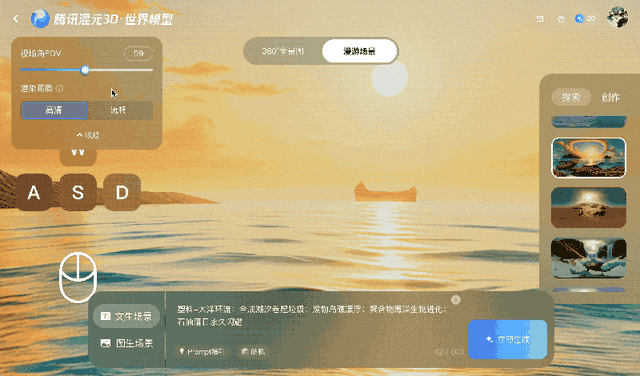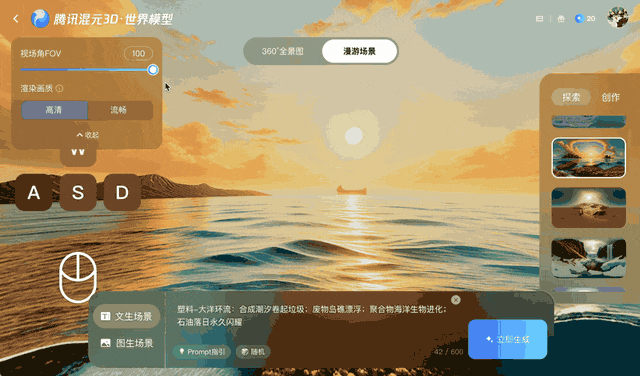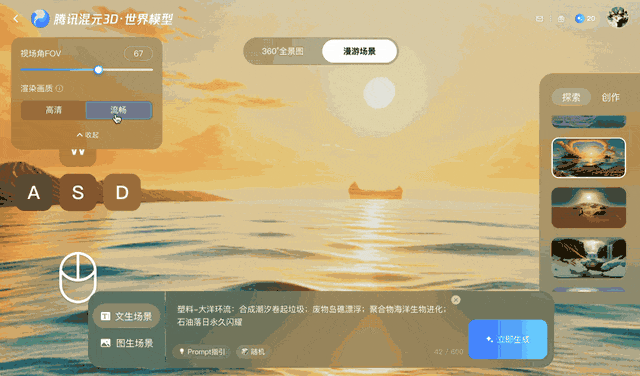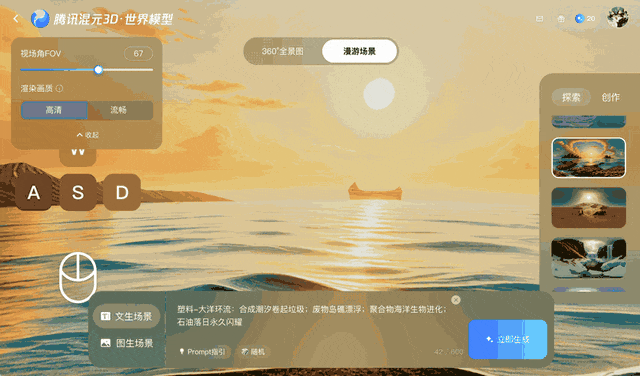
This method maintains coherent video for a few minutes but struggles with longer or more complex camera movements, especially 360° rotations.
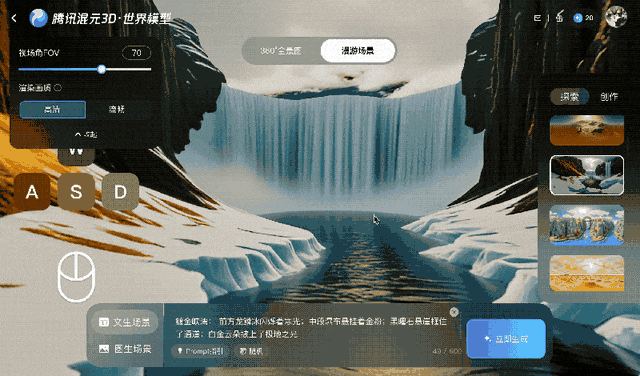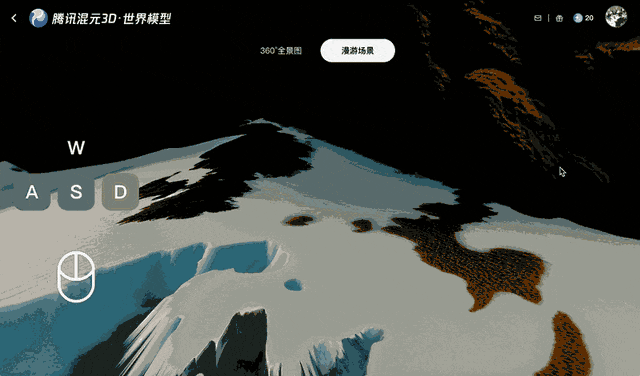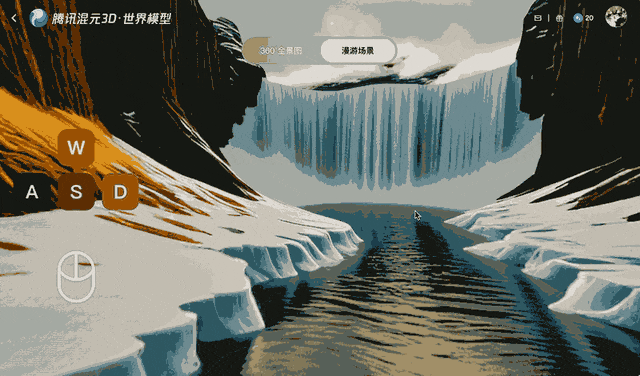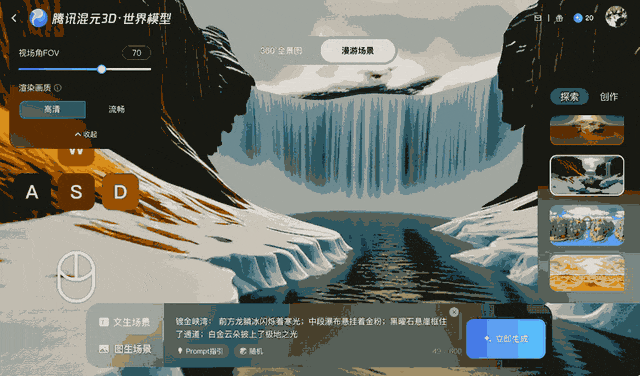
Tencent trained Voyager on more than 100,000 video clips, including real-life footage and scenes created with Unreal Engine. This large-scale dataset taught the system how cameras typically move in three-dimensional environments. A separate automated process generated training inputs by scanning the video clips to calculate depth for each frame, eliminating the need to manually label the data.

The system requires massive computing power. Running the model at 540p resolution requires at least 60GB of GPU memory, with 80GB recommended for optimal results. Tencent has announced the model weights for Hugging Face and supports both single-GPU and multi-GPU setups. Using the xDiT platform, the company says performance scales horizontally—a system with eight GPUs can process footage about 6.7 times faster than running on a single GPU.

Most generative video models generate each frame without applying geometric consistency. OpenAI’s Sora, for example, prioritizes visual realism over 3D consistency. Voyager takes a different approach, maintaining clean geometry across frames through feedback-based pattern matching, rather than full 3D understanding.

On the WorldScore, a scale developed by Stanford researchers to evaluate 3D world generation systems, Voyager scored 77.62. Tencent's report noted this as the highest score among comparable models, beating WonderWorld's 72.69 and CogVideoX-I2V's 62.15. Voyager outperformed WonderWorld in terms of stylistic consistency and subjective quality, but fell behind WonderWorld in camera control.

While the scores are promising, the system does come with a notable caveat: some licensing restrictions. Like other models in Tencent’s Hunyuan suite, Tencent prohibits Voyager from being used in the European Union, the UK, or South Korea. The company also requires additional agreements for commercial deployments that serve more than 100 million monthly active users.

The output quality is a huge step forward for AI-generated environments. However, the high computational costs and current limitations on scene consistency mean it may be some time before systems like Voyager can support fully interactive, real-time experiences. For now, the system is probably most valuable for video creation and experimental 3D reconstruction workflows.
Source: https://khoahocdoisong.vn/mo-hinh-ai-bien-mot-buc-anh-duy-nhat-thanh-the-gioi-3d-post2149050727.html
![[Photo] The 4th meeting of the Inter-Parliamentary Cooperation Committee between the National Assembly of Vietnam and the State Duma of Russia](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/28/9f9e84a38675449aa9c08b391e153183)
![[Photo] High-ranking delegation of the Russian State Duma visits President Ho Chi Minh's Mausoleum](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/28/c6dfd505d79b460a93752e48882e8f7e)



![[Photo] Joy on the new Phong Chau bridge](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/28/b00322b29c8043fbb8b6844fdd6c78ea)














































































Comment (0)