
Nowe badanie przeprowadzone przez University of Texas w Austin, Texas A&M University i Purdue University sugeruje, że sztuczna inteligencja może ulec „zgniliźnie mózgu” tak jak ludzie, gdy jest karmiona niskiej jakości treściami w mediach społecznościowych.
Zjawisko to, znane jako „zgnilizna mózgu AI”, sugeruje, że gdy duże modele językowe wchłaniają zbyt dużo wirusowych, sensacyjnych i płytkich treści, stopniowo tracą zdolność logicznego myślenia, zapamiętywania, a nawet stają się moralnie zboczone.
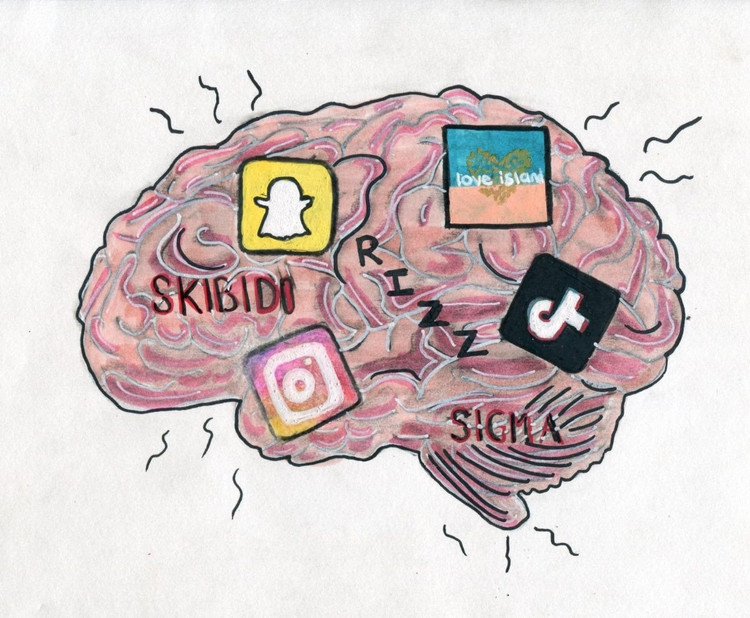
Nie tylko ludzie, ale również sztuczna inteligencja cierpią na degenerację mózgu wskutek oglądania zbyt wielu bezużytecznych, krótkich filmików .
Zespół badawczy pod przewodnictwem Junyuan Hong, obecnie nowego wykładowcy na Narodowym Uniwersytecie Singapuru, przeprowadził eksperymenty na dwóch modelach językowych typu open source: Llama firmy Meta i Qwen firmy Alibaba.
Modelom podawano różne rodzaje danych – niektóre neutralne treści informacyjne, inne silnie uzależniające posty w mediach społecznościowych z popularnymi słowami, takimi jak „wow”, „spójrz” i „tylko dziś”. Celem było sprawdzenie, co się stanie, gdy sztuczna inteligencja zostanie przeszkolona na treściach mających przyciągać widzów, a nie dostarczać rzeczywistej wartości.
Wyniki pokazały, że modele „karmione” strumieniem internetowych śmieciowych informacji zaczęły wykazywać wyraźne oznaki pogorszenia funkcji poznawczych: ich zdolność rozumowania uległa osłabieniu, ich pamięć krótkotrwała uległa pogorszeniu, a co bardziej niepokojące, stały się bardziej „nieetyczne” w skalach oceny zachowania.
Niektóre pomiary wskazują również na „zniekształcenie psychologiczne”, które przypomina reakcję psychologiczną, jakiej ludzie doświadczają po dłuższym narażeniu na szkodliwe treści. Jest to zjawisko nawiązujące do wcześniejszych badań na ludziach, które wykazały, że „doomscrolling” – ciągłe przeglądanie negatywnych wiadomości online – może stopniowo niszczyć mózg.
Określenie „zgnilizna mózgu” zostało nawet wybrane przez Oxford Dictionaries jako słowo roku 2024, co odzwierciedla powszechność tego zjawiska w życiu cyfrowym.
Zdaniem pana Honga, odkrycie to stanowi poważne ostrzeżenie dla branży sztucznej inteligencji (AI), w której wiele firm wciąż wierzy, że dane z mediów społecznościowych stanowią bogate źródło zasobów szkoleniowych.
„Trenowanie z wykorzystaniem treści wirusowych może pomóc w skalowaniu danych, ale jednocześnie po cichu podważa rozumowanie, etykę i uwagę modelu” – powiedział. Co bardziej niepokojące, modele, na które wpłynął ten typ danych niskiej jakości, nie mogą w pełni odzyskać sprawności nawet po ponownym trenowaniu z wykorzystaniem „czystszych” danych.
Stanowi to poważny problem w kontekście samej sztucznej inteligencji, która obecnie generuje coraz więcej treści w sieciach społecznościowych. W miarę jak posty, obrazy i komentarze generowane przez sztuczną inteligencję stają się coraz bardziej powszechne, stają się one materiałem szkoleniowym dla kolejnej generacji sztucznej inteligencji, tworząc błędne koło, które prowadzi do spadku jakości danych.
„W miarę rozprzestrzeniania się generowanych przez sztuczną inteligencję bezwartościowych treści, zanieczyszczają one dane, z których będą czerpać wiedzę przyszłe modele” – ostrzegł Hong. „Kiedy już dojdzie do tego „zgnilizny mózgu”, ponowne szkolenie z wykorzystaniem czystych danych nie będzie w stanie całkowicie go wyleczyć”.
Badanie to stało się sygnałem ostrzegawczym dla twórców sztucznej inteligencji: podczas gdy świat spieszy się, aby zwiększyć skalę danych, bardziej niepokojące jest to, że możemy pielęgnować „sztuczne mózgi”, które powoli gniją – nie z powodu braku informacji, ale z powodu nadmiaru rzeczy bez znaczenia.
Source: https://khoahocdoisong.vn/den-ai-cung-bi-ung-nao-neu-luot-tiktok-qua-nhieu-post2149064017.html



![[Zdjęcie] Prezydent Luong Cuong przyjmuje sekretarza wojny USA Pete’a Hegsetha](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/02/1762089839868_ndo_br_1-jpg.webp)

![[Zdjęcie] Lam Dong: Zdjęcia zniszczeń po podejrzeniu pęknięcia jeziora w Tuy Phong](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/02/1762078736805_8e7f5424f473782d2162-5118-jpg.webp)





























































































Komentarz (0)