

GPU jsou mozky počítačů s umělou inteligencí.
Jednoduše řečeno, grafická procesorová jednotka (GPU) funguje jako mozek počítače s umělou inteligencí.
Jak již možná víte, centrální procesorová jednotka (CPU) je mozkem počítače. Výhoda GPU spočívá v tom, že se jedná o specializovaný procesor pro provádění složitých výpočtů. Nejrychlejším způsobem, jak tyto výpočty provádět, je nechat skupinu GPU řešit problém společně. I tak může trénování modelu umělé inteligence trvat týdny nebo dokonce měsíce. Jakmile je model sestaven, je umístěn do front-endového počítačového systému a uživatelé mohou modelu umělé inteligence klást otázky; tento proces se nazývá inference.
Počítač s umělou inteligencí obsahuje více grafických procesorů (GPU).
Nejlepší architekturou pro řešení problémů s umělou inteligencí je použití skupiny grafických procesorů (GPU) v racku připojených k přepínači nahoře racku. Více racků s GPU lze navíc propojit v hierarchickém systému síťové konektivity. S rostoucí složitostí řešených problémů se zvyšují i požadavky na GPU, přičemž některé projekty mohou vyžadovat nasazení clusterů tisíců GPU.
Každý cluster umělé inteligence je malá síť.
Při budování clusteru umělé inteligence je nutné nastavit malou počítačovou síť, která propojí grafické procesory a umožní jim efektivně spolupracovat a sdílet data.
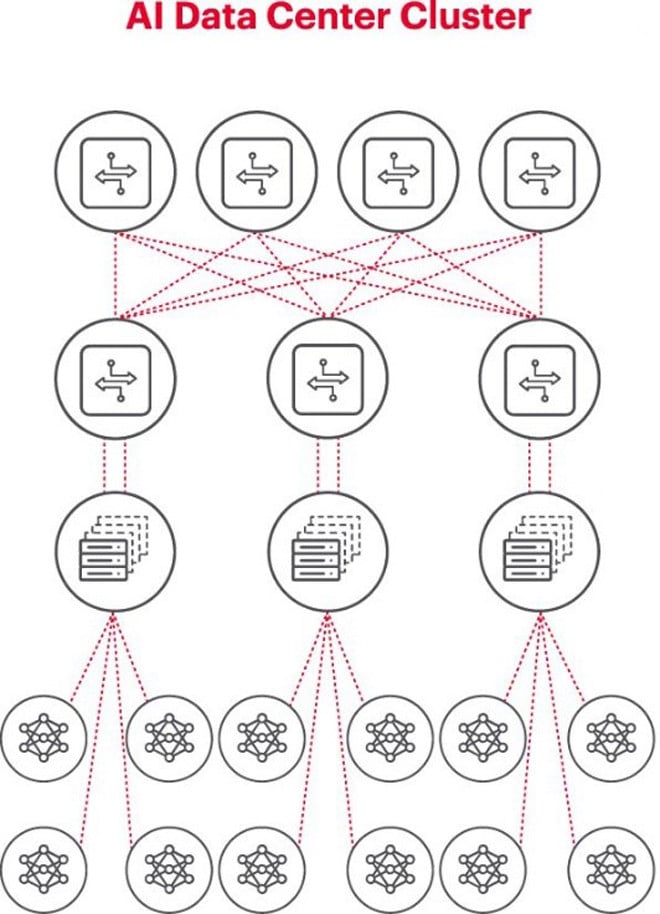
Výše uvedený diagram znázorňuje cluster AI, kde kruhy dole představují pracovní postupy běžící na grafických procesorech (GPU). GPU se připojují k přepínačům v horním racku (ToR). Tyto přepínače ToR se také připojují k páteřním přepínačům sítě zobrazeným na výše uvedeném diagramu, což demonstruje jasnou hierarchii sítě nezbytnou při zapojení více GPU.



Sítě jsou úzkým hrdlem v zavádění umělé inteligence.
Loni na podzim, na globálním summitu Open Computer Project (OCP), kde delegáti budovali infrastrukturu umělé inteligence nové generace, delegát Loi Nguyen ze společnosti Marvell Technology poukázal na klíčový problém: „sítě jsou novým úzkým hrdlem.“
Technicky vzato může vysoká latence paketů nebo ztráta paketů v důsledku přetížení sítě způsobit jejich opětovné odeslání, což výrazně zvyšuje dobu dokončení úlohy (JCT). V důsledku toho se kvůli neefektivním systémům umělé inteligence plýtvá grafickými procesory (GPU) patřící firmám v hodnotě milionů nebo desítek milionů dolarů, což poškozuje podniky jak z hlediska tržeb, tak i doby uvedení na trh.
Testování a měření jsou klíčovými podmínkami pro úspěšné fungování sítí umělé inteligence.
Pro efektivní provoz clusteru umělé inteligence musí být grafické procesory (GPU) schopny využít svou plnou kapacitu ke zkrácení doby trénování a implementaci modelů učení pro maximalizaci návratnosti investic. Proto je nezbytné testovat a vyhodnocovat výkon clusteru umělé inteligence (obrázek 2). Tento úkol však není snadný, protože architektura systému zahrnuje mnoho nastavení a vztahů mezi GPU a síťovou strukturou, které se musí vzájemně doplňovat, aby problém vyřešily.
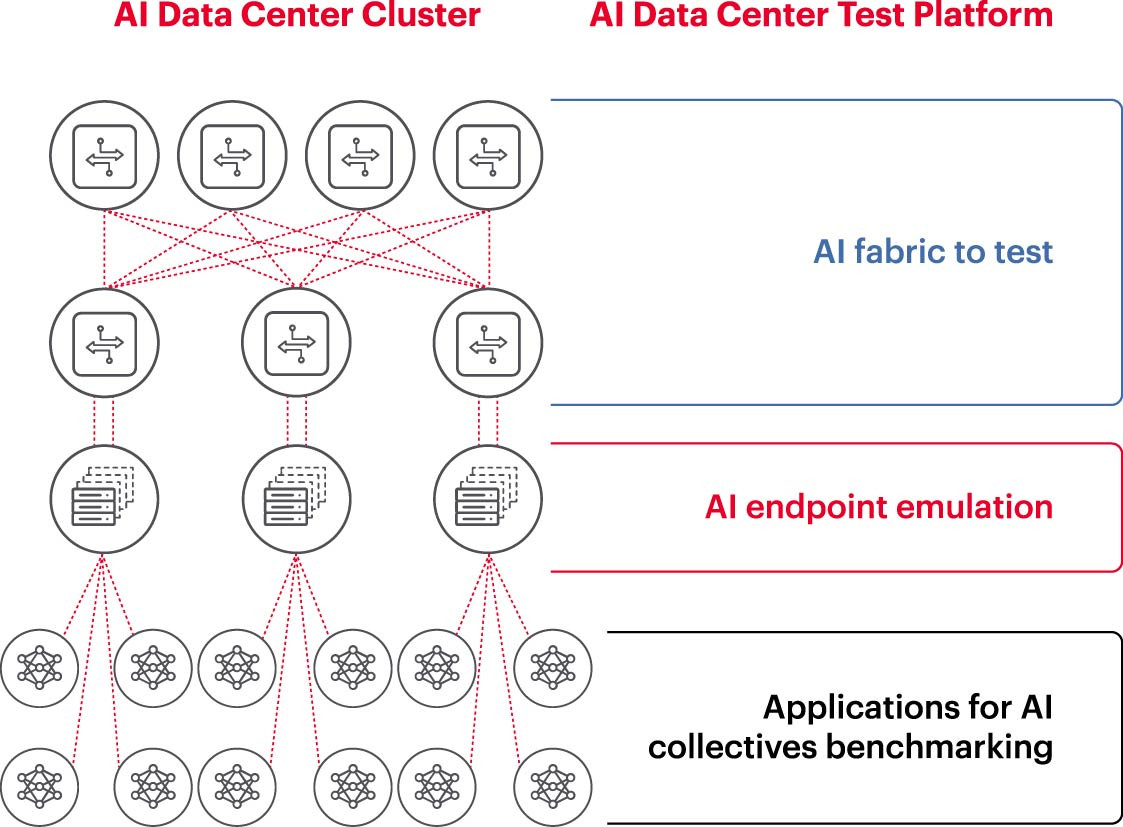
To vytváří mnoho obtíží a výzev při měření sítí umělé inteligence:
- Problém s replikací celé výrobní sítě v laboratoři je způsoben omezeními v nákladech, vybavení, nedostatku vysoce kvalifikovaných síťových inženýrů s umělou inteligencí, prostoru, napájení a teplotě.
- Testování na produkčním systému snižuje dostupnou výpočetní kapacitu samotného produkčního systému.
- Obtížnost s přesnou reprodukcí problémů kvůli rozdílům v rozsahu a rozsahu problémů.



- Složitost kolektivního propojení GPU.
Aby se firmy s těmito výzvami vypořádaly, mohou provést benchmarking podmnožiny navrhovaných nastavení v laboratorním prostředí, aby porovnaly klíčové parametry, jako je JCT (doba dokončení úlohy), šířka pásma dosažitelná týmem umělé inteligence, a porovnaly je s využitím přepínací platformy a využitím mezipaměti. Tento benchmarking pomáhá najít správnou rovnováhu mezi pracovní zátěží GPU/výpočetního výkonu a návrhem/instalací sítě. Jakmile jsou s výsledky spokojeni, mohou počítačoví architekti a síťoví inženýři tato nastavení aplikovat do produkčního prostředí a měřit nové výsledky.
Podnikové výzkumné laboratoře, výzkumné ústavy a univerzity pracují na analýze všech aspektů budování a provozu efektivních sítí s umělou inteligencí, aby řešily výzvy spojené s prací na velkých sítích, zejména proto, že se osvědčené postupy neustále mění. Tento opakovatelný kolaborativní přístup je jediný způsob, jak mohou firmy provádět opakovatelná měření a rychlé testování scénářů „pokud-pak“ – což je zásadní pro optimalizaci sítí s umělou inteligencí.
(Zdroj: Keysight Technologies)
Zdroj: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html




![[Foto] Posilování charakteru a odbornosti: Intenzivní výcvik dělostřeleckých vojáků.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2026/06/30/1782815602541_lu-368-1875-4571-jpg.webp)


































































































