
Інтерфейс v7, клавіатура з інтегрованим штучним інтелектом. Фото: NVCC . |
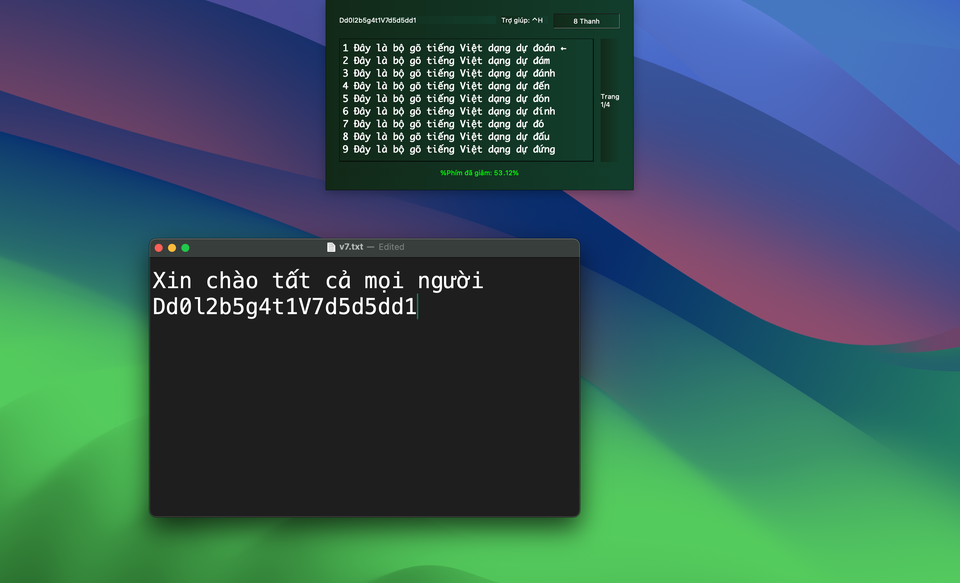
У інтерв'ю для Tri Thuc - Znews Трі Дик (народився у 2003 році) розповів про ідею застосування штучного інтелекту для зміни способу введення в'єтнамської мови. Інструмент набору тексту v7, його студентський проєкт, переріс у дослідницьку роботу та був прийнятий на IJCAI 2025, престижну конференцію зі штучного інтелекту.
Незважаючи на популярність протягом десятиліть, набор тексту за допомогою Telex або VNI все ще має багато обмежень у взаємодії з користувачем. Тому версія 7 була створена як легкий інструмент прогнозування, який допомагає скоротити час набору тексту в'єтнамською мовою завдяки інтеграції штучного інтелекту.
Пристрасть до мов та технологій
Його любов до мов і технологій привела його до спеціалізації «Прикладний штучний інтелект» в Технологічному університеті міста Хошимін.
Під час навчання він займався такими проектами, як велика мовна модель (LLM) для в'єтнамської мови, програмне забезпечення для перекладу мов етнічних меншин або чат-бот для підтримки вступу. «Цей досвід допоміг мені накопичити міцну основу знань, розвинути мою пристрасть і бажання застосовувати штучний інтелект для створення корисних продуктів для громади», – поділився він.
Tri Duc хоче втілити штучний інтелект у життя. Фото: NVCC. |

Крім того, маючи досвід у мандаринській та кантонській мовах, Дик розпізнав зв'язок між піньїнь/джутпін з в'єтнамським правописом. Цей фактор також показує, що, на відміну від складності ієрогліфів, китайська система набору тексту піньїнь вимагає лише введення «ин», щоб отримати назву нашої країни китайськими ієрогліфами. У той час як для отримання слова «В'єтнам» у телексі чи VNI потрібно 10 клавіш.
Завдяки своїм спостереженням Дюк зрозумів, що під час швидкого спілкування користувачі часто скорочують слова, зберігаючи першу приголосну, як-от «hs» для слова «студент». «Якщо люди можуть легко зрозуміти цей стиль письма, штучний інтелект може повністю його зрозуміти, якщо його навчити з правильними даними», – сказав він про обставини, що призвели до цієї ідеї.
Замість того, щоб писати повний символ, а потім додавати наголоси під час використання традиційних інструментів набору тексту, таких як Telex або VNI, які використовують механізм додавання, v7 використовує штучний інтелект, щоб підказати слово, яке ви хочете написати. Технологія точно передбачить повне слово з найменшою можливою кількістю клавіш.
У в'єтнамській орфографічній структурі слово складається з початкової приголосної, рими та тону. Наприклад, слово «Nguyen» складається з «ng», «uyen» та низхідного тону. На основі цього принципу, механізм набору тексту v7 побудований для прогнозування повних слів лише з початковою приголосною та тоном, що допомагає значно зменшити кількість натискань клавіш, зберігаючи при цьому точність.
Завдання навчання в'єтнамської мови для ШІ
За словами Дика, найбільшим викликом є навчання ШІ «розуміти» в'єтнамську мову для роботи з цим інструментом набору тексту. Він перепробував багато моделей, перш ніж обрати GPT-2 як основу, з архітектурою Transformers для гарного розуміння контексту та точного прогнозування слів.
Після вибору базової архітектури, Дюк повністю замінив токенізатор (кодер словника) на в'єтнамський словник, створений власноруч. Інженер відфільтрував усі дійсні, правильно написані в'єтнамські слова, щоб забезпечити комплексну обробку, передбачаючи будь-яке слово, яке користувач хотів написати.
Ще один виклик полягає в балансуванні прогностичної продуктивності та швидкості відгуку, забезпечуючи можливість роботи моделі в режимі реального часу як на комп’ютерах, так і на телефонах, але водночас достатньо потужною для створення найкращих прогнозів. Після 2 місяців безперервного тестування поточна версія правильно виводить майже 70% слів, які вводять користувачі, на початок результату, із затримкою лише 0,03 секунди.
Щодо методу введення на клавіатурі, то, згідно з багатьма дослідженнями, з якими Дик консультувався у лінгвістів Цао Сюань Хао або Анрі Масперо, в'єтнамська мова має не лише 6, а 8 тонів. Щоб скористатися цією функцією, v7 використовує систему з 8 тонів замість звичайних 6 (включаючи плоский тон і 5 акцентованих тонів: дієзливий, плоский, питальний, спадний, важкий). На цій клавіатурі під час набору "v7" модель запропонує слово "Viet". Це також є ідеєю для назви продукту.
Поділившись версією v7 у своїй соціальній мережі, Дик сказав, що був дуже радий і здивований, коли модель отримала увагу, підтримку та бажання її випробувати. «Це дало мені чітке відчуття потреби в розумнішому та швидшому інструменті для набору тексту в'єтнамською мовою», – сказав він.
Група авторів наукової статті. Зліва направо: Нят Кханг, Хіеу Нгіа та Трі Дук. Фото: NVCC. |

Наразі клавіатура все ще перебуває на стадії прототипу, з відкритим вихідним кодом на GitHub для тестування та внесення змін до розробки програмістами або користувачами технологій. Також розробляється повноцінна версія програми для Windows та macOS, яку звичайні користувачі зможуть легко встановити та використовувати.
У майбутньому головним пріоритетом для версії 7 є версія для клавіатури iPhone, щоб покращити спосіб введення в'єтнамського тексту на смартфонах. Крім того, точність моделі буде підвищена завдяки більшому навчанню на даних щоденних розмов, що допоможе штучному інтелекту краще розуміти поширені контексти.
Подорож Дика сприяла розвитку творчості, дозволяючи йому бути в курсі технологічних тенденцій у контексті значних інвестицій В'єтнаму в інфраструктуру штучного інтелекту. Один момент, який його пишає, – це коли v7 вперше створила повне речення. «Саме тоді маленька модель, ймовірно, лише в 1/10 000 від розміру ChatGPT сьогодні, все ще могла думати як людина», – сказав Дик.
Джерело: https://znews.vn/ky-su-tre-dung-ai-thay-doi-cach-go-tieng-viet-post1552246.html



![[Фото] Локшина Чу — есенція рису та сонця](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/11/1762846220477_ndo_tl_7-jpg.webp)

![[Фото] Прем'єр-міністр Фам Мінь Чінь головує на нараді з питань житлової політики та ринку нерухомості.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/11/11/1762838719858_dsc-2107-jpg.webp)


























































































![Трансформація Dong Nai OCOP: [Стаття 4] Досягнення національних стандартів продукції](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/11/11/1762825820379_4702-cac-san-pham-trai-cay-chung-nhan-ocop-nongnghiep-174649.jpeg)



![Перехідний період Донг Най OCOP: [Стаття 3] Зв'язок туризму зі споживанням продукції OCOP](https://vphoto.vietnam.vn/thumb/402x226/vietnam/resource/IMAGE/2025/11/10/1762739199309_1324-2740-7_n-162543_981.jpeg)





Коментар (0)