
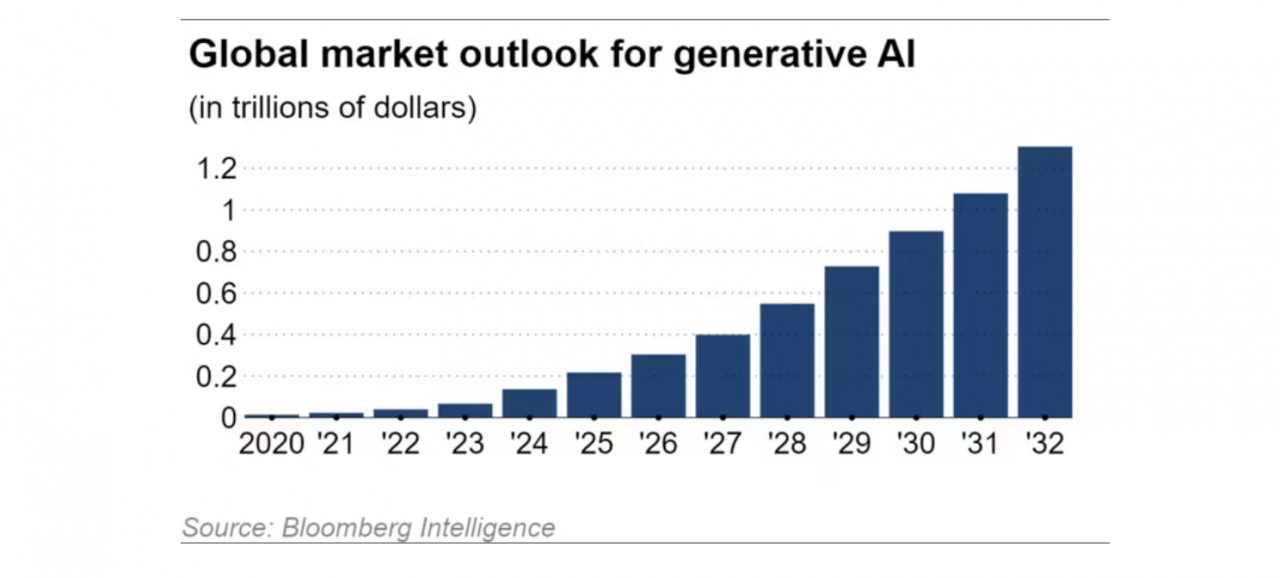
По оценкам Bloomberg Intelligence, мировой рынок синтетического ИИ ежегодно растет на 42% и, как ожидается, к 2032 году достигнет 1,3 триллиона долларов США, что примерно в 32 раза превышает объем рынка 2022 года, составивший 40 миллиардов долларов США.
Лидерами являются американские технологические компании, такие как OpenAI, Google и Amazon — технологические гиганты с большими бюджетами и человеческими ресурсами.
Несмотря на жесткую конкуренцию, VinGroup решила разработать собственную версию, используя вьетнамские данные для создания ИИ с более высокой точностью, чем у зарубежных конкурентов, говорит Ву Ха Ван, профессор математики Йельского университета, который является научным руководителем VBD.
До сих пор программы генеративного ИИ обучались преимущественно на данных на английском языке. Это означает, что данных по Вьетнаму относительно мало, что снижает точность этих программ в отношении местной культуры, истории и законов.
Говорят, что большая языковая модель ViGPT (LLM) состоит из 1,6 миллиарда параметров, что составляет несколько процентов от размера GPT-4 OpenAI.
Большее количество параметров обычно соответствует более высокому интеллекту. Однако, согласно общей оценке ИИ, адаптированной для вьетнамского рынка, ViGPT превзошёл многих зарубежных конкурентов и уступил только ChatGPT.
Группа компаний VinFast будет применять технологии искусственного интеллекта (ИИ) при производстве электромобилей. Водители смогут управлять транспортным средством с помощью голосовых команд на вьетнамском языке. Группа также планирует внедрить ИИ в сферы финансов, страхования и логистики.
Гонка за развитие ИИ в Азии
По оценкам, только около 5% населения мира говорят на английском как на родном языке, что означает огромную потенциальную потребность в разработке ИИ для людей, для которых английский язык не является родным.
В Японии компании разрабатывают искусственный интеллект, генерирующий японский язык. В августе электронный гигант NEC запустил сервис на основе LLM (котоми). Телекоммуникационная компания NTT в марте запустит сервис на основе tsuzumi, ещё одной LLM. Японский оператор мобильной связи SoftBank также разрабатывает собственный LLM.
«Понимание японских деловых практик дает преимущества в плане удобства использования, например, позволяет более естественно отвечать на электронные письма и выполнять работу колл-центра», — сказал президент SoftBank Дзюнъити Миякава.
Гонку за разработку собственных систем ИИ подпитывают риски чрезмерной зависимости от США, особенно в вопросах международной конкурентоспособности и национальной безопасности. Также существуют опасения, что использование программ ИИ, разработанных в других странах, приведёт к утечкам данных и раскрытию конфиденциальной информации.
Профессор Ван заявил, что развивающийся технологический сектор не должен оставаться в руках иностранных компаний, поскольку все больше студентов используют ИИ для обучения, а это значит, что инновации оказывают огромное влияние на молодое поколение.
В Китае, конкурирующем с США в сфере технологий, Baidu, Tencent Holdings и Alibaba Group Holding разрабатывают инновационный ИИ. К концу прошлого года число пользователей Ernie Bot от Baidu превысило 100 миллионов.
«Разрабатываемая нами сейчас генеративная модель большого языка больше подойдет для китайского языка и китайского рынка», — заявил председатель и генеральный директор Baidu Робин Ли.
В августе прошлого года южнокорейская интернет-компания Naver представила HyperClova X — искусственный интеллект, адаптированный для корейского языка. Программа будет интегрирована с поисковой системой и платформой онлайн-покупок компании, чтобы помочь пользователям эффективнее находить нужные результаты.
Компания Naver утверждает, что ее база данных корейских текстов в 6500 раз больше, чем база данных корейских текстов ChatGPT, что обеспечивает более естественное чтение текста и более плавное распознавание языка.
В прошлом месяце Сингапур объявил о планах разработки программ магистратуры права (LLM), адаптированных для индонезийского, малайзийского и тайского языков. Однако подобные инициативы столкнутся с рядом трудностей, таких как нехватка данных для обучения редко встречающимся языкам, а также рентабельность разработки таких моделей.

Источник
![[Фото] Президент Луонг Куонг проводит переговоры с президентом ЮАР Матамелой Сирилом Рамафосой](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/23/1761221878741_ndo_br_1-8416-jpg.webp)

![[Фото] Постоянный член Секретариата Чан Кам Ту председательствовал на заседании Постоянного комитета Организационного подкомитета по обслуживанию 14-го Национального съезда партии.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/24/1761286395190_a3-bnd-4513-5483-jpg.webp)
![[Фото] Премьер-министр Фам Минь Чинь встречается с президентом ЮАР Матамелой Сирилом Рамафосой](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/23/1761226081024_dsc-9845-jpg.webp)




































































































Комментарий (0)