

GPUs sind das Gehirn von KI-Computern.
Vereinfacht ausgedrückt fungiert die Grafikprozessoreinheit (GPU) als das Gehirn eines KI-Computers.
Wie Sie vielleicht bereits wissen, ist die zentrale Verarbeitungseinheit (CPU) das Gehirn eines Computers. Der Vorteil einer GPU liegt darin, dass sie eine spezialisierte CPU für komplexe Berechnungen ist. Am schnellsten lassen sich diese Berechnungen durchführen, indem mehrere GPUs gemeinsam ein Problem lösen. Trotzdem kann das Training eines KI-Modells Wochen oder sogar Monate dauern. Sobald es erstellt ist, wird es in das Frontend-Computersystem integriert, und Benutzer können dem KI-Modell Fragen stellen; dieser Prozess wird als Inferenz bezeichnet.
Ein KI-Computer enthält mehrere GPUs.
Die beste Architektur zur Lösung von KI-Problemen besteht darin, mehrere GPUs in einem Rack zu verwenden, die über einen Switch mit diesem verbunden sind. Mehrere GPU-Racks lassen sich zusätzlich in einem hierarchischen Netzwerk verbinden. Mit zunehmender Komplexität der zu lösenden Probleme steigen auch die Anforderungen an die GPUs; manche Projekte benötigen unter Umständen Cluster mit Tausenden von GPUs.
Jeder KI-Cluster ist ein kleines Netzwerk.
Beim Aufbau eines KI-Clusters ist es notwendig, ein kleines Computernetzwerk einzurichten, um die GPUs zu verbinden und ihnen eine effiziente Zusammenarbeit und den effizienten Datenaustausch zu ermöglichen.
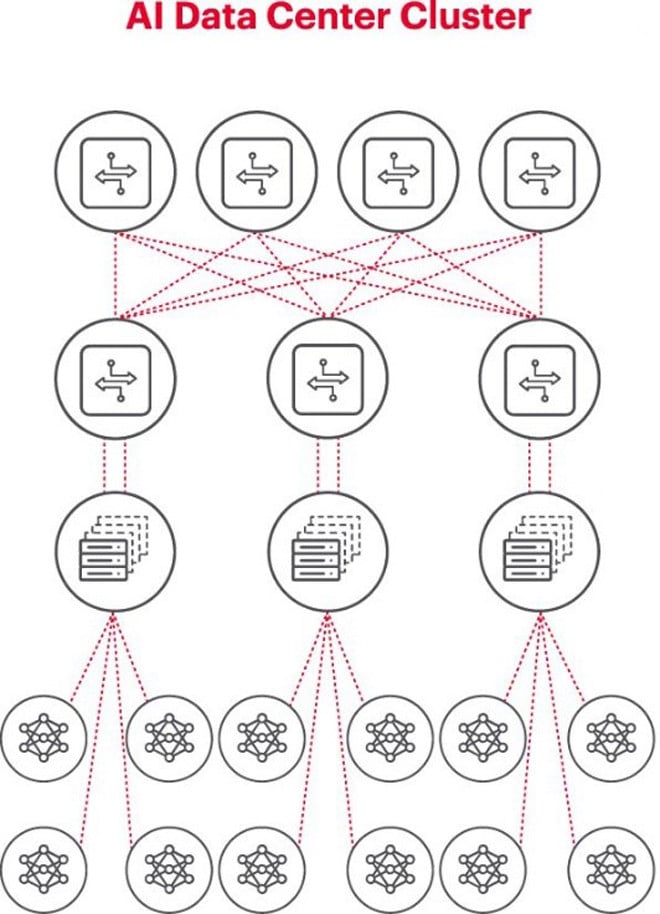
Das obige Diagramm veranschaulicht einen KI-Cluster. Die Kreise unten stellen Workflows dar, die auf GPUs ausgeführt werden. Die GPUs sind mit Switches im oberen Rack (ToR) verbunden. Diese ToR-Switches sind wiederum mit den oben im Diagramm dargestellten Backbone-Switches des Netzwerks verbunden. Dies verdeutlicht die klare Netzwerkhierarchie, die bei der Verwendung mehrerer GPUs notwendig ist.
![[Podcast] Weltnachrichten vom 1. Juli: Iran verweigert Treffen mit US-Gesandtem](https://vphoto.vietnam.vn/thumb/192x108/vietnam/resource/IMAGE/2026/07/01/1782896024877_khung-thumbnail-tham-khao-tu-mau-cu-500-x-500-px-900-x-600-px-15.jpeg)


Netzwerke stellen einen Engpass bei der KI-Implementierung dar.
Im vergangenen Herbst wies Loi Nguyen von Marvell Technology auf dem globalen Gipfeltreffen des Open Computer Project (OCP), bei dem die Delegierten die nächste Generation der KI-Infrastruktur entwickelten, auf ein zentrales Problem hin: „Netzwerke sind der neue Flaschenhals.“
Technisch gesehen können hohe Paketlatenz oder Paketverluste aufgrund von Netzwerküberlastung dazu führen, dass Pakete erneut gesendet werden müssen, was die Jobabwicklungszeit (JCT) erheblich verlängert. Infolgedessen werden GPUs im Wert von Millionen oder gar Dutzenden Millionen Dollar, die Unternehmen gehören, aufgrund ineffizienter KI-Systeme verschwendet, was den Unternehmen sowohl hinsichtlich Umsatz als auch Markteinführungszeit schadet.
Testen und Messen sind entscheidende Voraussetzungen für den erfolgreichen Betrieb von KI-Netzwerken.
Für den effizienten Betrieb eines KI-Clusters müssen GPUs ihre volle Kapazität ausschöpfen können, um die Trainingszeit zu verkürzen und Lernmodelle so zu implementieren, dass der Return on Investment maximiert wird. Daher ist die Prüfung und Bewertung der Leistung des KI-Clusters unerlässlich (Abbildung 2). Diese Aufgabe ist jedoch komplex, da die Systemarchitektur zahlreiche Einstellungen und Wechselwirkungen zwischen GPU und Netzwerkstruktur umfasst, die sich gegenseitig ergänzen müssen, um das Problem zu lösen.
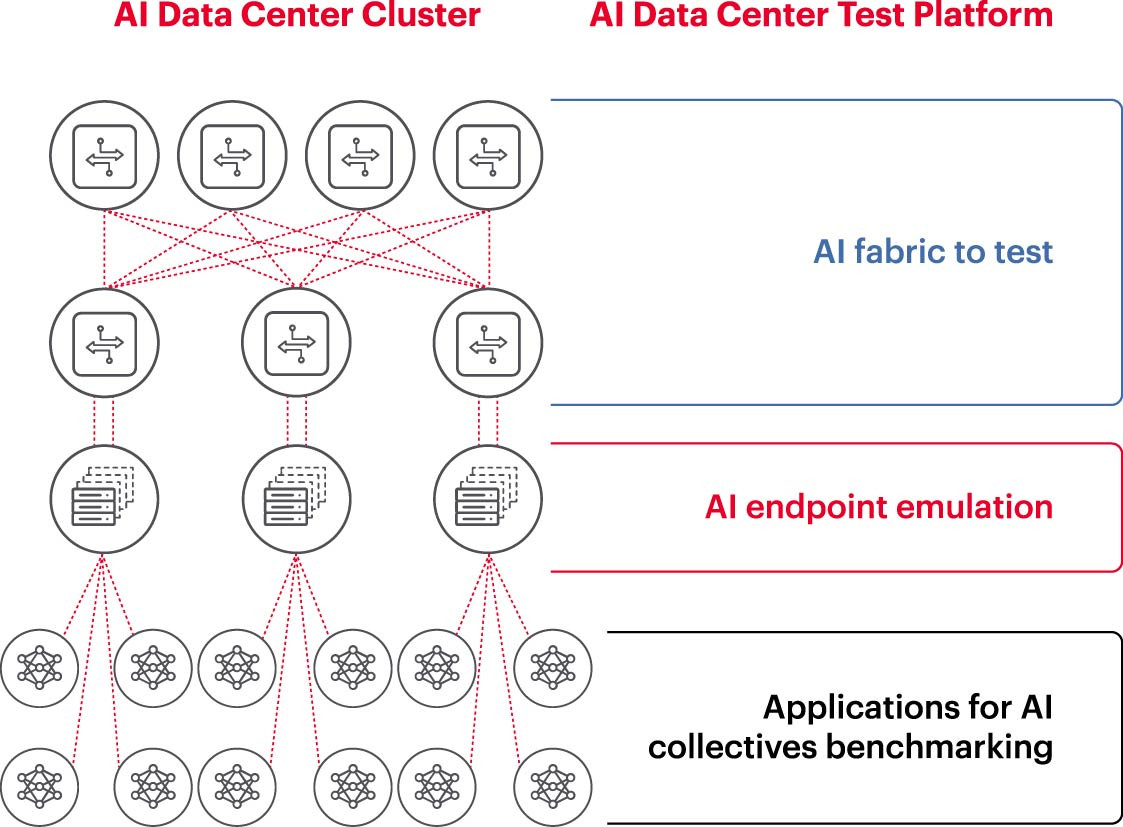
Dies führt zu vielen Schwierigkeiten und Herausforderungen bei der Messung von KI-Netzwerken:
Die Herausforderung bei der Nachbildung des gesamten Produktionsnetzwerks im Labor liegt in den Einschränkungen bei Kosten, Ausrüstung, einem Mangel an hochqualifizierten KI-Netzwerkingenieuren, Platz, Stromversorgung und Temperatur.
- Tests am Produktionssystem verringern die verfügbare Verarbeitungskapazität des Produktionssystems selbst.
- Schwierigkeiten bei der genauen Reproduktion der Probleme aufgrund von Unterschieden im Umfang und der Reichweite der Probleme.



- Die Komplexität der Art und Weise, wie GPUs gemeinsam verbunden werden.
Um diese Herausforderungen zu bewältigen, können Unternehmen in einer Laborumgebung Benchmarking-Tests für eine Auswahl vorgeschlagener Setups durchführen. Dabei lassen sich wichtige Parameter wie die Job-Completion-Time (JCT), die vom KI-Team erreichbare Bandbreite sowie die Nutzung von Switching-Plattformen und Caching vergleichen. Dieses Benchmarking hilft, das optimale Verhältnis zwischen GPU-/Verarbeitungslast und Netzwerkdesign/-installation zu finden. Sind die Ergebnisse zufriedenstellend, können die Systemarchitekten und Netzwerktechniker diese Setups in der Produktion einsetzen und die neuen Ergebnisse messen.
Unternehmensforschungslabore, Forschungsinstitute und Universitäten analysieren alle Aspekte des Aufbaus und Betriebs effektiver KI-Netzwerke, um den Herausforderungen der Arbeit mit großen Netzwerken zu begegnen, insbesondere angesichts der sich ständig ändernden Best Practices. Dieser wiederholbare, kollaborative Ansatz ist für Unternehmen die einzige Möglichkeit, reproduzierbare Messungen und schnelle Wenn-Dann-Szenariotests durchzuführen – grundlegend für die Optimierung KI-gestützter Netzwerke.
(Quelle: Keysight Technologies)
Quelle: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html


























































































































