

As GPUs são o cérebro dos computadores com inteligência artificial.
Em termos simples, a unidade de processamento gráfico (GPU) funciona como o cérebro de um computador com inteligência artificial.
Como você já deve saber, a unidade central de processamento (CPU) é o cérebro de um computador. A vantagem de uma GPU reside no fato de ser uma CPU especializada para realizar cálculos complexos. A maneira mais rápida de realizar esses cálculos é ter grupos de GPUs resolvendo um problema em conjunto. Mesmo assim, o treinamento de um modelo de IA ainda pode levar semanas ou até meses. Uma vez construído, ele é colocado no sistema de computador de front-end, e os usuários podem fazer perguntas ao modelo de IA; esse processo é chamado de inferência.
Um computador com inteligência artificial contém múltiplas GPUs.
A melhor arquitetura para resolver problemas de IA é usar um grupo de GPUs em um rack, conectado a um switch no topo do rack. Vários racks de GPUs podem ser conectados em um sistema de conectividade de rede hierárquico. À medida que os problemas a serem resolvidos se tornam mais complexos, os requisitos de GPU também aumentam, com alguns projetos potencialmente necessitando implantar clusters com milhares de GPUs.
Cada cluster de IA é uma pequena rede.
Ao construir um cluster de IA, é necessário configurar uma pequena rede de computadores para conectar e permitir que as GPUs trabalhem juntas e compartilhem dados de forma eficiente.
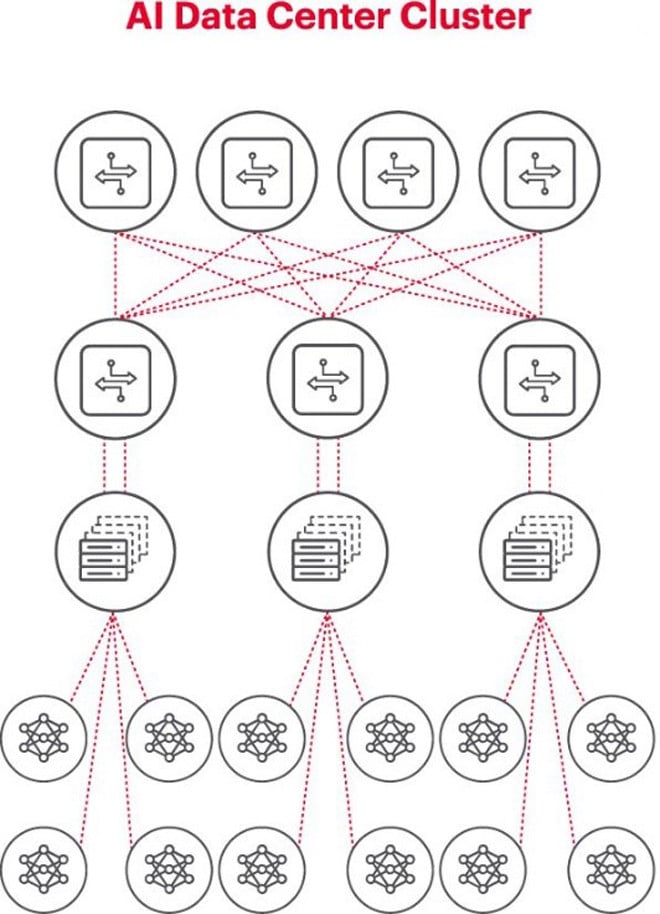
O diagrama acima ilustra um cluster de IA onde os círculos na parte inferior representam fluxos de trabalho executados em GPUs. As GPUs se conectam aos switches no rack superior (ToR). Esses switches ToR também se conectam aos switches da rede principal mostrados acima no diagrama, demonstrando a hierarquia de rede clara necessária quando várias GPUs estão envolvidas.



As redes são um gargalo na implementação da IA.
No outono passado, na cúpula global do Open Computer Project (OCP), onde os participantes estavam construindo a próxima geração de infraestrutura de IA, o participante Loi Nguyen, da Marvell Technology, apontou uma questão fundamental: "as redes são o novo gargalo".
Tecnicamente, alta latência de pacotes ou perda de pacotes devido à congestão da rede podem fazer com que os pacotes sejam reenviados, aumentando significativamente o tempo de conclusão da tarefa (JCT). Como resultado, milhões ou dezenas de milhões de dólares em GPUs pertencentes a empresas são desperdiçados devido a sistemas de IA ineficientes, prejudicando os negócios em termos de receita e tempo de lançamento no mercado.
Os testes e as medições são condições cruciais para o funcionamento bem-sucedido das redes de IA.
Para operar um cluster de IA de forma eficiente, as GPUs precisam ser capazes de utilizar toda a sua capacidade para reduzir o tempo de treinamento e implementar modelos de aprendizado, maximizando o retorno sobre o investimento. Portanto, testar e avaliar o desempenho do cluster de IA é essencial (Figura 2). No entanto, essa tarefa não é fácil, pois a arquitetura do sistema envolve diversas configurações e relações entre a GPU e a estrutura de rede, que precisam se complementar para solucionar o problema.
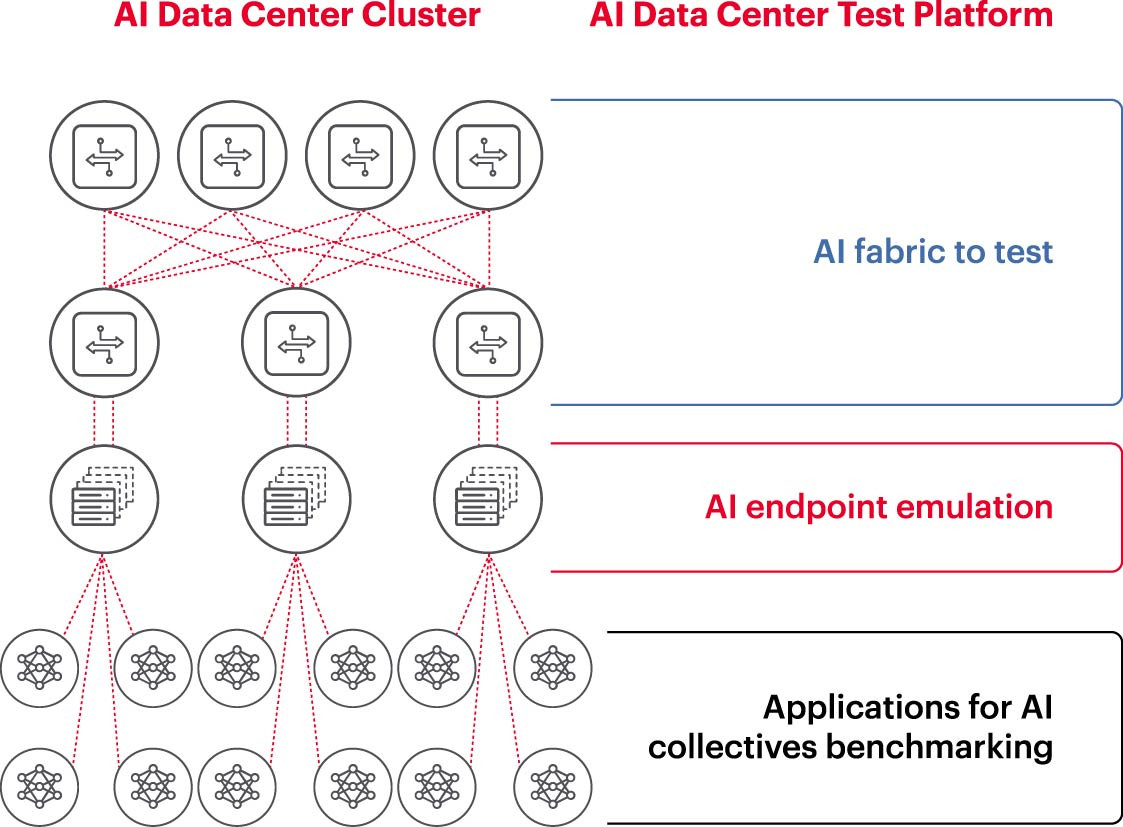
Isso cria muitas dificuldades e desafios na medição de redes de IA:
O desafio de replicar toda a rede de produção em laboratório deve-se às limitações de custo, equipamento, escassez de engenheiros de redes de IA altamente qualificados, espaço, fornecimento de energia e temperatura.
- Os testes no sistema de produção reduzem a capacidade de processamento disponível do próprio sistema de produção.
- Dificuldade em reproduzir os problemas com precisão devido às diferenças na escala e no escopo dos mesmos.



- A complexidade de como as GPUs se conectam coletivamente.
Para lidar com esses desafios, as empresas podem realizar testes comparativos de um subconjunto das configurações propostas em um ambiente de laboratório para avaliar parâmetros-chave, como o tempo de conclusão da tarefa (JCT), a largura de banda alcançável pela equipe de IA e compará-los com o uso da plataforma de comutação e o uso de cache. Esses testes comparativos ajudam a encontrar o equilíbrio ideal entre a carga de trabalho da GPU/processamento e o projeto/instalação da rede. Uma vez satisfeitos com os resultados, os arquitetos de sistemas e engenheiros de rede podem aplicar essas configurações à produção e mensurar os novos resultados.
Laboratórios de pesquisa empresarial, institutos de pesquisa e universidades estão trabalhando para analisar todos os aspectos da construção e operação de redes de IA eficazes, visando enfrentar os desafios de trabalhar com grandes redes, especialmente considerando a constante evolução das melhores práticas. Essa abordagem colaborativa e repetível é a única maneira de as empresas realizarem medições consistentes e testes rápidos de cenários "se-então" — fundamentais para a otimização de redes baseadas em IA.
(Fonte: Keysight Technologies)
Fonte: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html


























































































































