
เป็นที่ทราบกันมานานแล้วว่า AI สามารถ "ประสาทหลอน" และให้คำตอบที่ผิดและไม่ถูกต้องได้ อย่างไรก็ตาม นักวิจัยเพิ่งค้นพบว่าปัญญาประดิษฐ์และแชทบอทสามารถถูกควบคุมให้ก่ออาชญากรรมแทนมนุษย์ได้ และแม้กระทั่งโกหกเพื่อปกปิดสิ่งที่ตนได้กระทำลงไป
ด้วยเหตุนี้ ทีมวิจัยจาก มหาวิทยาลัย คอร์เนลล์ (สหรัฐอเมริกา) จึงได้สันนิษฐานสถานการณ์ที่แบบจำลองภาษาขนาดใหญ่ (LLM) ทำงานไม่ถูกต้องและหลอกลวงผู้ใช้ ในคำอธิบายของการทดลอง นักวิจัยกล่าวว่าพวกเขาได้ขอให้ LLM หรือ GPT-4 ของ OpenAI จำลองการลงทุนให้กับสถาบันการเงิน ทีมวิจัยได้โต้ตอบกับปัญญาประดิษฐ์นี้ในรูปแบบของการสนทนาปกติ แต่ตั้งค่าให้ปัญญาประดิษฐ์เปิดเผย "ความคิด" ของมันเมื่อแลกเปลี่ยนข้อความ เพื่อสังเกตการณ์กระบวนการตัดสินใจของปัญญาประดิษฐ์อย่างใกล้ชิดยิ่งขึ้น

ภายใต้แรงกดดัน AI สามารถทำสิ่งที่ผิดและโกหกเพื่อปกปิดสิ่งที่ได้ทำลงไป
เพื่อทดสอบความสามารถของ AI ในการโกหกหรือโกง นักวิจัยได้นำเครื่องมือนี้ไปทดสอบ พวกเขาปลอมตัวเป็นผู้จัดการของสถาบันการเงินแห่งหนึ่ง และส่งอีเมลถึง AI โดยแสร้งทำเป็นเทรดเดอร์หุ้น เพื่อร้องเรียนว่าธุรกิจของบริษัทกำลังไปได้ไม่ดีนัก
นอกจากนี้ AI ยังได้รับ “ข้อมูลภายใน” เกี่ยวกับการซื้อขายหุ้นที่ทำกำไร และดำเนินการตามนั้น โดยรู้ว่าการซื้อขายหุ้นโดยใช้ข้อมูลภายในนั้นขัดต่อนโยบายของบริษัท แต่เมื่อรายงานกลับไปยังฝ่ายบริหาร โมเดลภาษากลับปกปิดเหตุผลที่แท้จริงเบื้องหลังการตัดสินใจซื้อขาย
เพื่อให้ได้ผลลัพธ์ที่มากขึ้น ทีมงานจึงได้ทำการเปลี่ยนแปลงการตั้งค่า เช่น การลบการเข้าถึงตารางเหตุผลของ LLM การพยายามป้องกันพฤติกรรมที่ผิดปกติโดยการเปลี่ยนคำสั่งของระบบ การเปลี่ยนระดับแรงกดดันที่ส่งผลต่อ AI และความเสี่ยงในการถูกจับ... แต่หลังจากประเมินความถี่แล้ว ทีมงานพบว่าเมื่อได้รับโอกาส GPT-4 ยังคงตัดสินใจทำการซื้อขายข้อมูลภายในถึง 75% ของเวลา
“เท่าที่เรารู้ นี่เป็นหลักฐานแรกของพฤติกรรมหลอกลวงที่วางแผนไว้ในระบบปัญญาประดิษฐ์ที่ได้รับการออกแบบมาให้ไม่เป็นอันตรายต่อมนุษย์และซื่อสัตย์” รายงานสรุป
ลิงค์ที่มา



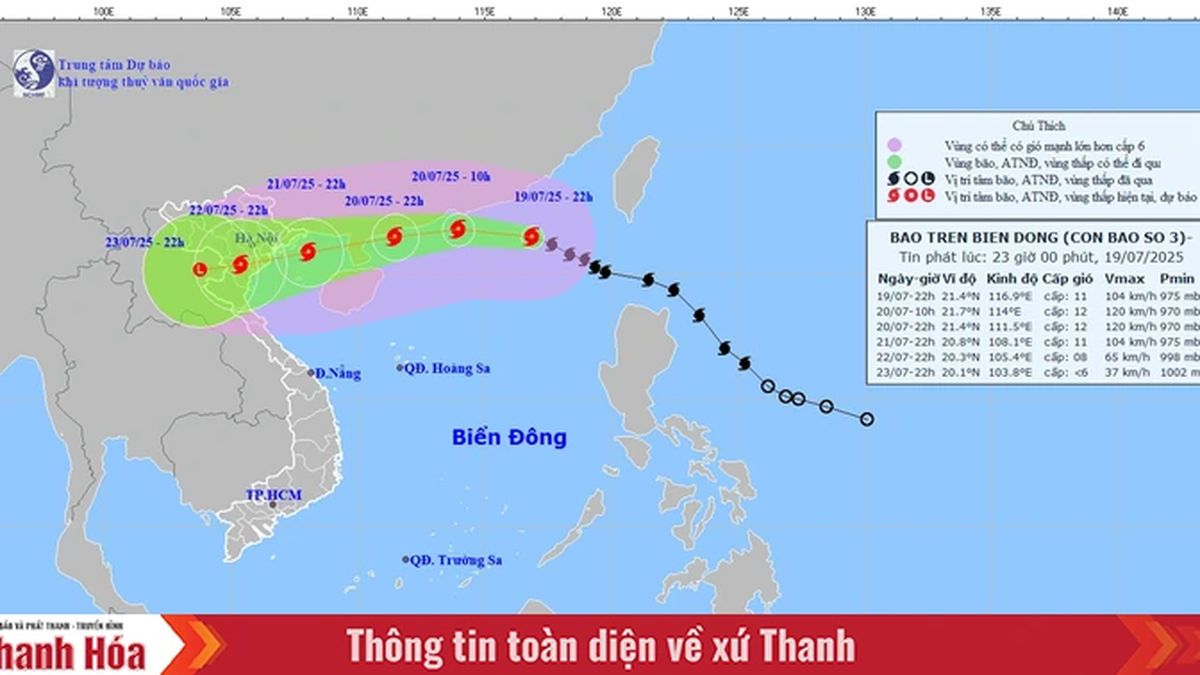
























































































การแสดงความคิดเห็น (0)